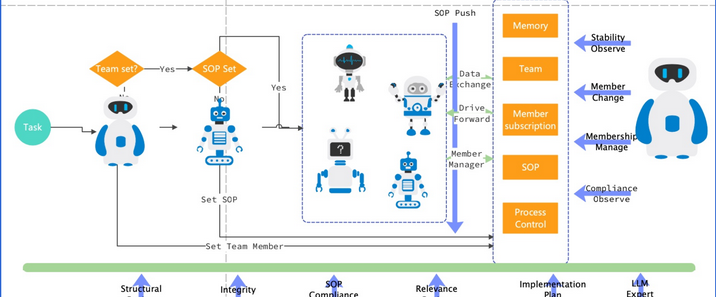
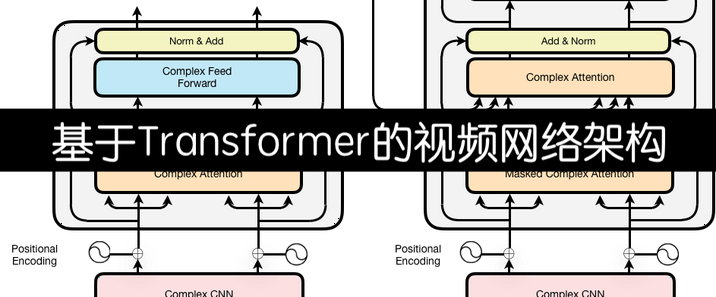
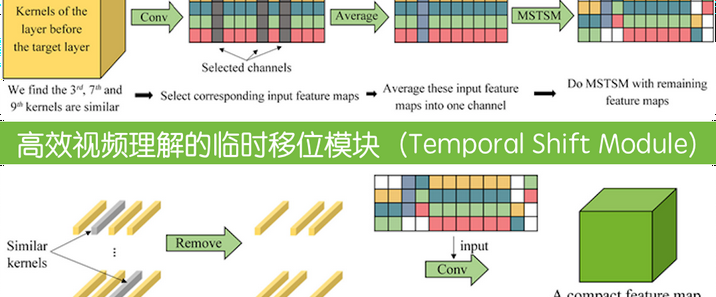
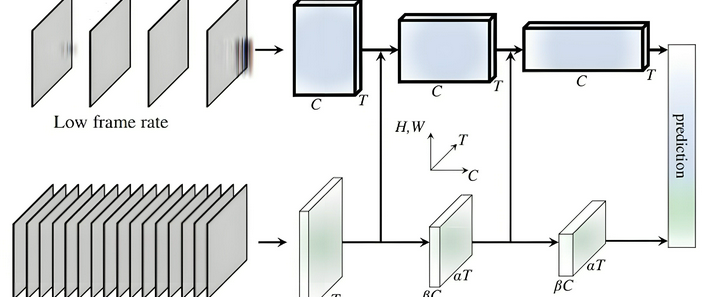
在深度学习浪潮席卷计算机视觉领域的当下,视频数据的高效处理已然成为学术研究与产业应用的关键焦点。海量的视频数据蕴含着丰富的时空信息,从安防监控中的行为识别,到影视娱乐中的内容分析,再到自动驾驶中的场景感知,对视频数据的精准解读需求与日俱增。传统的卷积神经网络(CNN)凭借强大的特征提取能力,在图像识别领域斩获了令人瞩目的成绩,成功实现了对图像中物体、场景的高精度分类与定位。然而,视频数据作为连续的图像帧序列,不仅包含空间维度上的视觉信息,更具有时间维度上的动态变化与因果关联,这使得传统CNN在处理视频数据时面临诸多挑战。CNN固有的局部感受野特性,使其难以捕捉视频中长距离的时间依赖关系和复杂的动态变化,无法充分挖掘视频数据的时空潜力。TimeSformer正是在这样的背景下应运而生,它以自注意力机制为核心,致力于打破传统模型的局限,重新定义视频理解的技术范式,为视频处理领域带来全新的突破与发展。