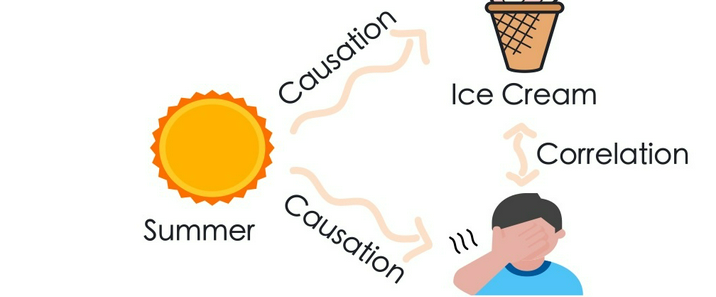
智能体记忆架构(Agent Memory)是当前大模型应用落地中,赋予人工智能智能体类人记忆能力、经验沉淀能力、自主进化能力的核心底层架构。传统无记忆大模型存在天然短板:上下文窗口有限、对话结束数据清零、无法自主留存用户习惯、无法复用历史交互经验,每一次问答都属于“全新开局”,无法形成连续的智能行为。而标准三层记忆架构由短期工作记忆、长期向量记忆、情景记忆共同组成,三层记忆分级管控、异步存储、联动调用,高度复刻人类大脑的记忆运转逻辑。该架构让智能体拥有真实的“过往经历”,能够记住用户、沉淀经验、复盘优化,最终实现个性化、连续性、可迭代的智能化交互。