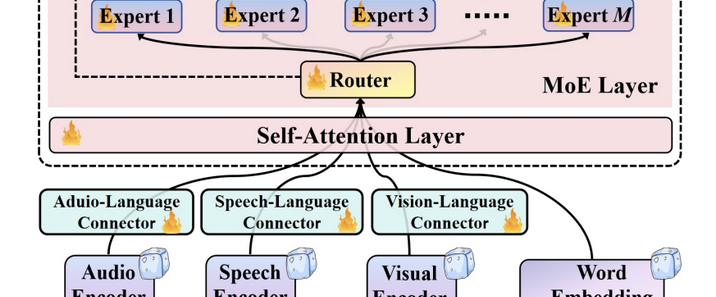
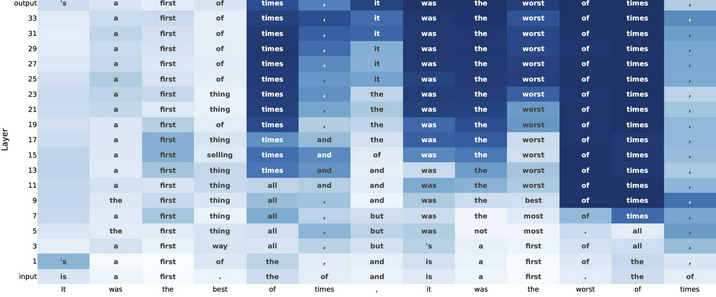
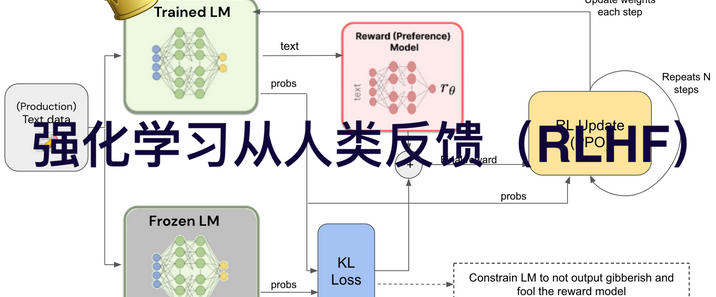
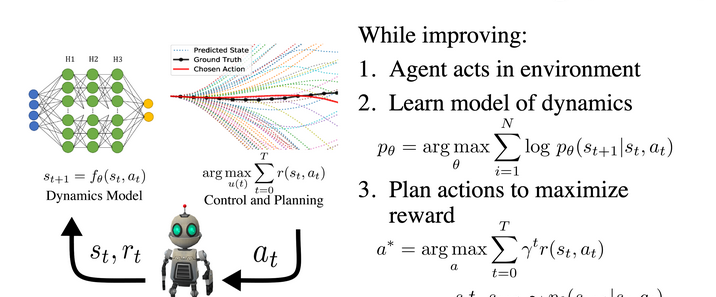
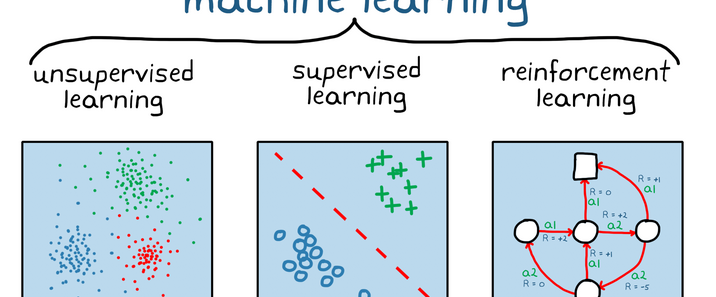
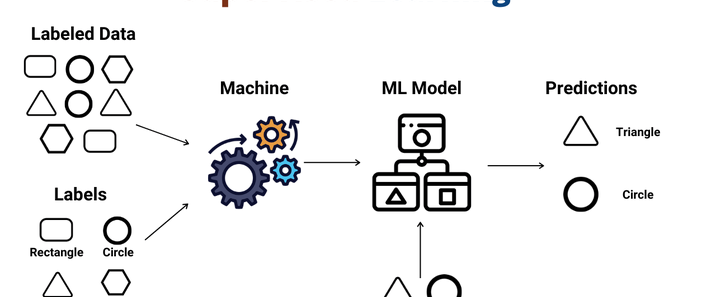
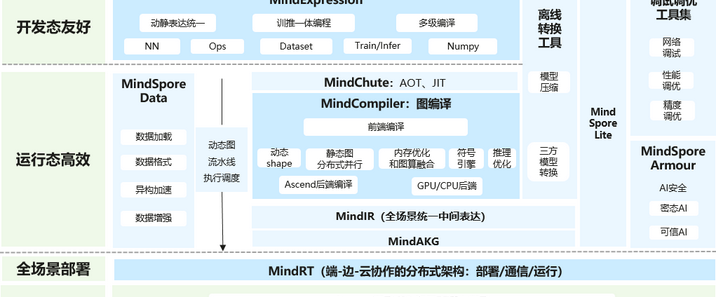
OpenAI于2024年12月20日发布了人工智能“推理”模型o3-mini,并于2025年2月1日在ChatGPT和API中正式上线。人工智能 “推理” 模型是一类能够模拟人类推理过程,对输入信息进行分析、判断和决策的智能模型。o3-mini模型会展开事实核查,可规避一些常见的模型陷阱,但会产生响应延迟,通常为几秒到几分钟。使用 “私人思想链” 进行 “思考”,能在响应前暂停,考虑相关提示并解释推理过程,最终总结出最准确的答案。可调整推理时间,有低、中、高三种计算级别,计算级别越高,任务执行性能越好。在软件工程能力测评中准确度得分 71.7%。在 2024 年 AIME 数学竞赛题目测试中准确度得分为 96.7%。以 100% 为最高分的 ARC-AGI 评估结果显示,最低成绩为 75.7%,最高成绩为 87.5%