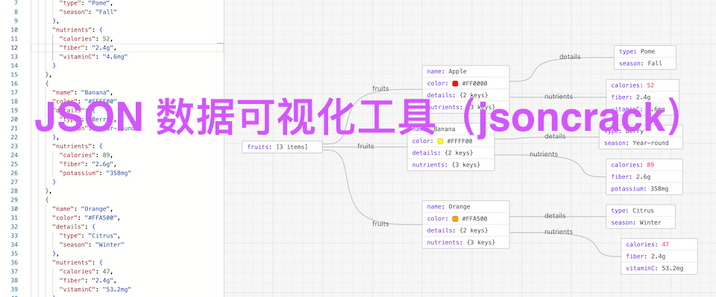
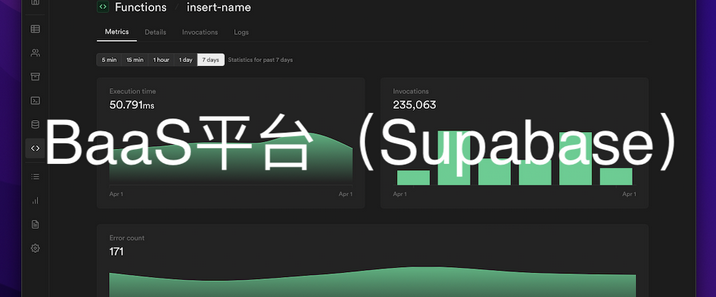
Supabase 是一个开源的后端即服务(Backend-as-a-Service, BaaS)平台,常被称为“开源版 Firebase”。它旨在为开发者提供快速搭建后端所需的核心工具,无需从零构建数据库、认证、存储等基础设施。Supabase 的核心目标是:“提供开源的 Firebase 替代方案”,让开发者通过简单的 API 即可使用企业级后端功能,同时保持数据控制权和开源自由。它强调“无供应商锁定”,支持自托管或使用其托管服务,数据存储在开源的 PostgreSQL 中,避免被单一平台绑定。