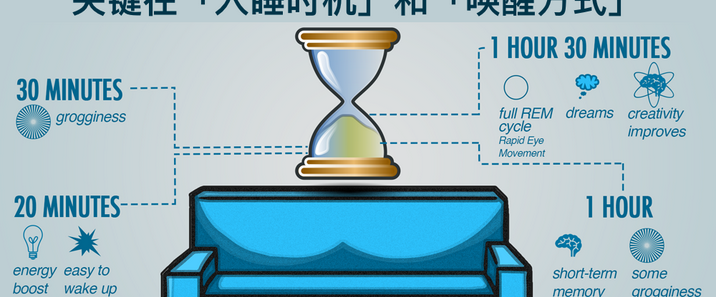
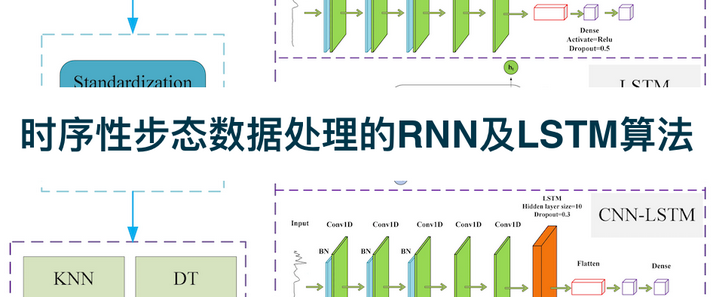
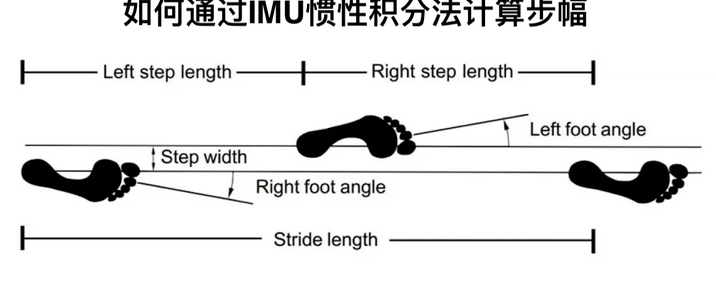
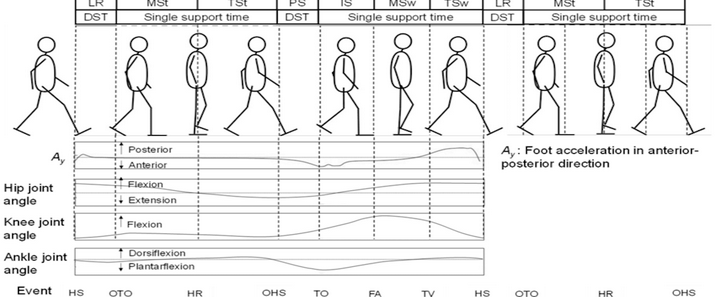
人工智能的迭代始终围绕“数据”与“效率”两大核心命题。传统机器学习在图像识别、语音合成等领域的突破,背后是动辄数百万级的标注数据和巨大的算力投入——训练一套识别罕见皮肤病的模型,需积累数千名患者的高清病灶图像并由皮肤科专家逐一审定;开发一套适用于古籍修复的文字识别系统,要耗费大量人力对残缺字迹进行标注。然而在实际场景中,“数据匮乏”“场景多变”才是常态,传统模型“一次训练仅适用于一类任务”的局限性愈发凸显。迁移学习(Transfer Learning)的诞生,彻底打破了这一僵局,它通过复用已有任务的知识经验,让AI在新任务中实现“低数据成本、高学习效率”的突破,成为推动人工智能从实验室走向实用化的核心技术之一。