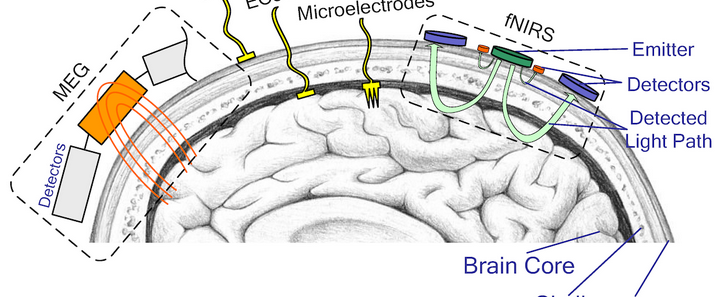
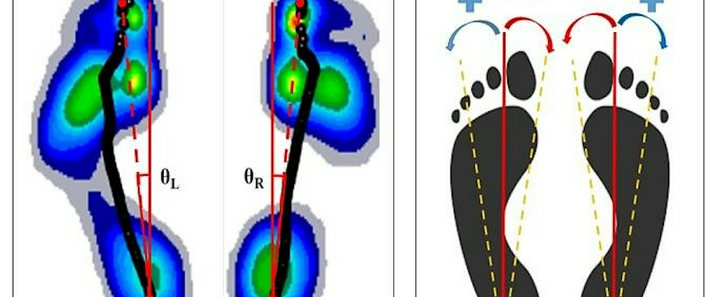
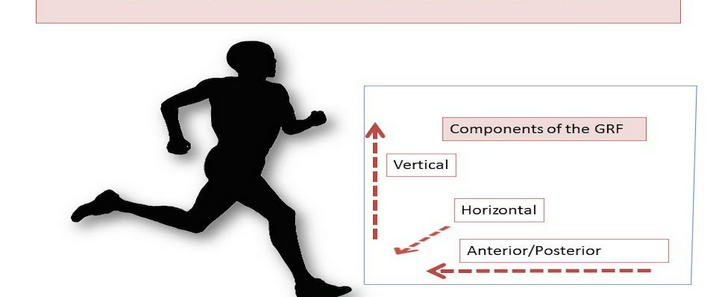
压力中心点(Center of Pressure, COP)是足底压力分布的等效作用点,其位置与轨迹可直观反映人体姿态稳定性、步态特征及足部健康状况,在跌倒风险评估、运动康复、糖尿病足监测等领域具有重要价值。智能鞋垫通过集成压力传感单元与数据处理模块,突破了传统测力台的空间限制,实现了COP的便携式、动态测量。以下将详细阐述其核心实现路径。
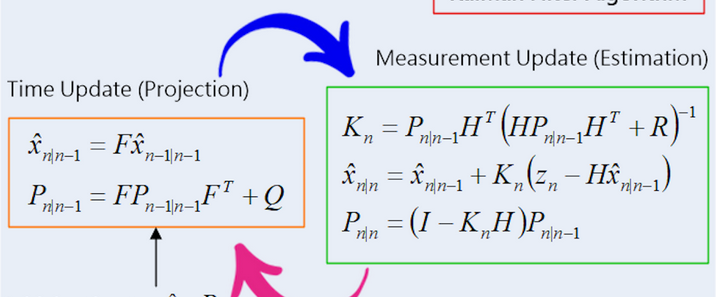
在信号处理、控制系统、自动驾驶等众多领域,我们常常需要从包含噪声的观测数据中提取出系统真实的状态信息。卡尔曼滤波(Kalman Filter)作为一种高效的递归滤波算法,凭借其对线性系统的最优估计能力,成为解决这类问题的经典工具。一、卡尔曼滤波的基本概念卡尔曼滤波由鲁道夫·卡尔曼(Rudolf E. Kalman)于1960年提出,其本质是一种基于线性系统状态方程和观测方程,利用递推方式对系统状态进行最优估计的算法。与传统的批处理滤波(如最小二乘法)不同,卡尔曼滤波不需要存储全部历史观测数据,而是通过当前观测值和上一时刻的状态估计值,实时计算出当前的最优状态估计,具有计算量小、实时性强的显著优势。