Marquez由Willy Lul Ciuc和Julien Le Dem在WeWork于2017年开发,并在2019年开源,目前是LF AI & Data基金会的孵化阶段项目。具有用户友好且直观的界面,操作细节设计出色,方便用户快速上手和使用。代码简洁,部署相对容易,降低了使用门槛和部署成本。依靠底层的OpenLineage协议,具有较好的结构,能够与其他遵循该协议的工具和系统进行良好的交互和集成。
一、核心功能
元数据收集:收集关于数据源、数据转换和输出的元数据,并将这些信息存储在一个集中式存储库中,帮助用户清晰地了解数据资产的来龙去脉。
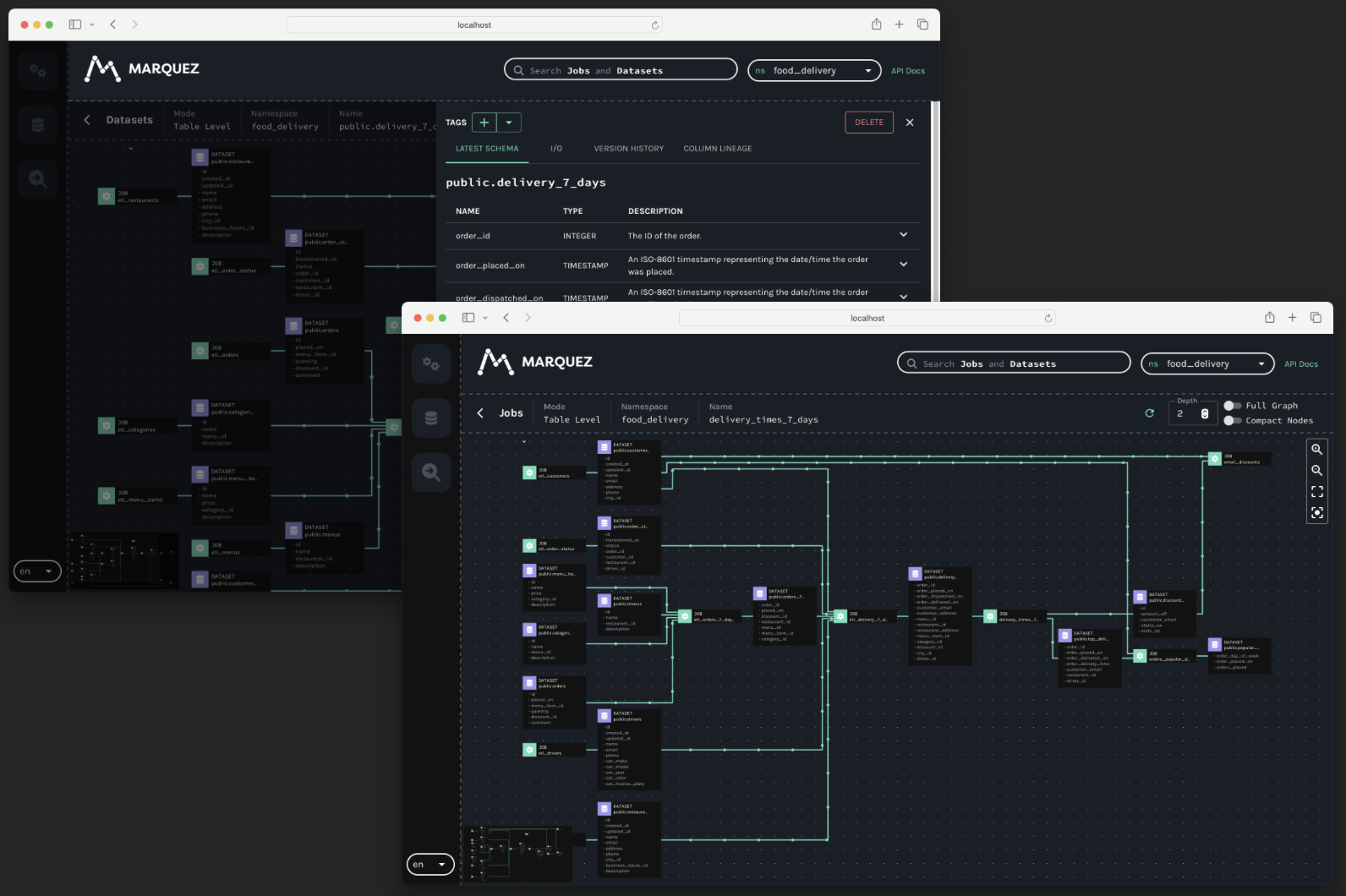
数据血缘可视化:可以直观地展示数据的血缘关系,即数据从哪里来、经过了哪些处理和转换,最终到哪里去。这对于理解数据的流向、追踪数据的变化以及排查数据问题非常有帮助。
数据发现与治理:作为数据发现的核心工具,方便用户查找和访问数据集。同时,在数据治理方面,它可以帮助团队更好地管理和监控数据资产,确保数据的质量和合规性。
二、工作原理
1. 元数据收集:
主动收集:支持与各种数据源进行连接,数据源可以是数据库(如 MySQL、PostgreSQL、Hive 等)、数据仓库、数据处理框架(如 Spark)、ETL 工具等。Marquez 通过与这些数据源的接口或日志文件进行交互,主动获取关于数据的元数据信息,例如表结构、字段定义、数据类型、创建时间、修改时间等。
接收推送:除了主动收集,也支持数据源主动向 Marquez 推送元数据信息。一些现代的数据处理系统和工具可以在数据处理过程中生成元数据事件,并将这些事件发送给 Marquez,这种方式能够确保元数据的实时性和准确性。
2. 元数据存储:
集中存储:将收集到的元数据存储在一个集中式的存储库中。这个存储库可以是关系型数据库,也可以是其他专门的存储系统,用于长期保存和管理元数据。集中存储使得用户可以在一个统一的位置访问和查询所有的数据资产元数据。
索引建立:为了提高元数据的查询效率,Marquez 会在存储的元数据基础上建立索引。索引可以根据元数据的不同属性,如数据源名称、表名、字段名等进行创建,以便快速地定位和检索所需的元数据信息。
3. 数据血缘分析:
依赖关系解析:当从数据源收集到元数据后,Marquez 会对数据之间的依赖关系进行解析。例如,对于一个数据处理流程,它会分析输入数据来自哪些源表,经过了哪些转换操作(如 SQL 查询、数据清洗、聚合等),最终生成了哪些输出数据。通过这种方式,建立起数据的血缘关系图。
可视化展示:将解析出的数据血缘关系以可视化的方式呈现给用户。用户可以通过图形界面直观地查看数据的流向和依赖关系,便于理解数据的产生过程和影响范围。这对于数据溯源、问题排查和影响分析非常有帮助。
4. 数据发现与访问:
数据目录构建:基于存储的元数据,Marquez 构建一个数据目录,类似于图书馆的目录系统,用于帮助用户快速找到所需的数据资产。数据目录中包含了数据源的列表、表的详细信息、字段的描述等,用户可以通过搜索、筛选等功能在数据目录中查找感兴趣的数据。
访问控制与共享:提供访问控制功能,确保只有经过授权的用户能够访问敏感的数据资产。同时,支持用户之间的数据共享和协作,用户可以将自己发现的数据资产分享给团队成员,或者对数据进行注释和标记,方便团队成员之间的交流和协作。
三、不足之处
1. 功能深度方面:
数据资产管理功能不够全面:虽然在数据血缘可视化方面表现出色,但在其他数据资产管理的关键功能上,如数据质量评估和监控、数据安全管理等方面的功能相对较弱。对于企业级的数据资产管理需求来说,这些功能的缺失可能导致无法形成完整的数据治理体系。例如,在对数据的准确性、完整性、一致性等质量维度进行监测和评估时,Marquez 可能无法提供足够强大的工具和机制,需要与其他专门的数据质量工具进行集成。
缺乏深度的数据加工处理支持:在数据处理和转换过程中,对于复杂的数据加工逻辑和算法的支持不足。当企业需要对数据进行深度清洗、转换、聚合等操作时,Marquez 可能无法提供高效的工具和接口,使得数据处理过程不够便捷和高效。
2. 性能与扩展性方面:
性能瓶颈:在处理大规模数据和复杂数据结构时,可能会出现性能下降的情况。随着企业数据量的不断增长,Marquez 在元数据收集、存储和查询等操作上的性能可能无法满足企业的实时性要求。例如,在对大型数据仓库中的海量数据表进行血缘分析时,可能会出现查询响应时间过长的问题。
扩展性受限:对于一些特殊的数据存储系统或数据处理框架的支持可能不够灵活,导致在与企业现有数据架构进行集成时存在一定的困难。如果企业使用了一些较为小众或自定义的数据处理系统,Marquez 可能无法很好地与之对接,限制了其在企业中的广泛应用。
3. 用户体验方面:
界面功能的局限性:尽管界面美观且操作细节设计较好,但在一些高级功能的操作界面上,可能存在操作流程不够简洁、功能选项不够直观等问题,增加了用户的学习成本和使用难度。例如,在设置数据血缘的复杂过滤条件或进行多数据源的关联查询时,用户可能需要花费较多的时间去熟悉和操作界面。
缺乏个性化定制能力:对于不同用户的个性化需求,Marquez 在界面定制、功能定制和报表定制等方面的支持不够强大。每个企业的数据资产管理需求都有其独特性,而 Marquez 可能无法很好地满足用户对于个性化定制的需求,导致用户在使用过程中无法根据自己的实际情况进行灵活的配置和调整。
四、应用场景
数据资产管理工具 Marquez 的应用场景如下:
1. 企业数据治理:
数据血缘追踪:在复杂的数据处理环境中,企业拥有众多的数据处理流程和系统。Marquez 可以清晰地展示数据的来源、转换过程和去向,帮助数据治理团队理解数据的流转情况。例如,在银行的业务系统中,客户的交易数据经过多个系统的处理和转换,Marquez 能够准确追踪这些数据的血缘关系,便于发现数据质量问题的根源以及评估数据变更的影响。
数据质量监控:通过对元数据的收集和分析,Marquez 可以帮助企业建立数据质量监控机制。企业可以定义数据质量规则,并利用 Marquez 监测数据是否符合这些规则。如果发现数据质量问题,能够快速定位问题所在的数据源头或处理环节,及时进行修复和改进。
数据合规性管理:在一些行业,如金融、医疗等,数据的合规性要求非常高。Marquez 可以帮助企业管理数据的合规性,记录数据的使用情况和访问权限,确保数据的使用符合相关法规和政策。例如,医疗行业中患者的个人信息数据,Marquez 可以跟踪数据的访问和使用情况,保证数据的隐私和安全。
2. 数据仓库与数据集市建设:
数据资产盘点:在构建数据仓库或数据集市时,企业需要对现有的数据资产进行盘点和梳理。Marquez 可以帮助企业收集和整理数据仓库中的元数据信息,包括表结构、字段定义、数据类型等,使企业能够清楚地了解数据仓库中存储的数据资产,为数据仓库的设计和优化提供依据。
ETL 流程管理:ETL(Extract, Transform, Load)是数据仓库建设中的关键环节。Marquez 可以监控 ETL 流程的执行情况,记录每个作业的运行状态、输入输出数据等信息,帮助企业优化 ETL 流程,提高数据加载的效率和准确性。
3. 数据科学与机器学习项目:
特征工程管理:在数据科学和机器学习项目中,特征工程是非常重要的环节。Marquez 可以帮助数据科学家管理特征工程过程中的元数据,记录特征的提取方法、来源数据等信息,便于团队成员之间的协作和特征的复用。例如,在一个预测用户购买行为的机器学习项目中,数据科学家使用 Marquez 记录每个特征的计算方式和数据来源,方便其他成员理解和使用这些特征。
模型可解释性:对于机器学习模型的可解释性,数据血缘信息是非常重要的。Marquez 可以提供模型训练过程中使用的数据的血缘关系,帮助数据科学家和业务人员理解模型的决策依据,提高模型的可信度和可解释性。
4. 数据团队协作与知识共享:
数据资产发现与共享:数据团队成员可以使用 Marquez 快速发现企业中的数据资产,了解数据的基本信息和使用情况。同时,成员可以将自己使用的数据资产分享给其他成员,促进数据的共享和复用,提高团队的工作效率。例如,一个数据分析团队中的成员发现了一个有价值的数据集,通过 Marquez 将其分享给其他成员,其他成员可以在这个数据集的基础上进行进一步的分析和挖掘。
项目协作与沟通:在数据项目的实施过程中,团队成员需要进行频繁的沟通和协作。Marquez 可以作为一个统一的元数据管理平台,为团队成员提供数据的相关信息和背景知识,减少沟通成本,提高协作效率。例如,在一个数据迁移项目中,团队成员可以通过 Marquez 了解源数据和目标数据的结构和关系,更好地进行数据迁移工作。
企业数据管理:适用于企业内部的数据管理,帮助企业更好地理解和管理其数据资产,提高数据的可见性和可管理性,为企业的数据驱动决策提供支持。
数据团队协作:方便数据团队成员之间的协作和沟通,团队成员可以通过Marquez共享数据洞察和更新,共同维护和管理数据资产。
数据工程与分析:对于数据工程师和分析师来说,Marquez是一个强大的工具,可以帮助他们快速了解数据的来源和处理过程,提高数据处理和分析的效率。
总的来说,Marquez是一个功能强大、易于使用的数据资产工具,特别适合需要对数据资产进行有效管理、追踪数据血缘和实现数据发现的组织和团队。但它也有一些不足,比如在数据资产管理的一些功能上,还需要进一步的开发工作来完善。