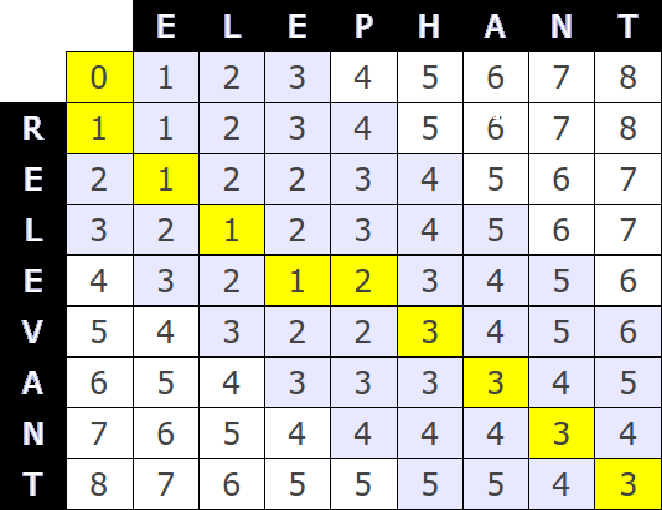
Levenshtein距离,又称为编辑距离,是一种度量两个字符串之间差异的方法。它是由俄国科学家Vladimir Levenshtein在1965年提出的。Levenshtein距离定义为将一个字符串转换为另一个字符串所需的最少单字符编辑操作次数,这些编辑操作包括插入、删除或替换字符。
一、算法详述:
1. 初始化:
- 创建一个大小为(m+1) x (n+1)的矩阵,其中m和n分别是两个字符串的长度。矩阵的第一行和第一列分别初始化为从0到m和从0到n的整数,表示从空字符串到目标字符串的编辑距离。
2. 填充矩阵:
- 遍历矩阵,对于每个单元格`(i, j)`,执行以下步骤:
- 如果`i`为0,则表示第一个字符串为空,需要插入`j`个字符来匹配第二个字符串,因此`matrix[i][j] = j`。
- 如果`j`为0,则表示第二个字符串为空,需要删除`i`个字符来匹配第一个字符串,因此`matrix[i][j] = i`。
- 如果两个字符串的当前字符相同(即`str1[i-1] == str2[j-1]`),则当前单元格的值等于左上角单元格的值,即`matrix[i][j] = matrix[i-1][j-1]`。
- 如果当前字符不同,则当前单元格的值等于左上角单元格的值加上1,或者等于左侧单元格的值加1(删除操作),或者等于上侧单元格的值加1(插入操作),取这三种情况的最小值,即:
matrix[i][j] = min(matrix[i-1][j-1], matrix[i][j-1] + 1, matrix[i-1][j] + 1)
3. 获取结果:
- 矩阵的最后一个单元格`(m, n)`的值即为两个字符串的Levenshtein距离。
4. 算法复杂度:
- 时间复杂度:O(m x n) ,其中`m`和`n`是两个字符串的长度。
- 空间复杂度:O(m x n) ,用于存储矩阵。
二、应用场景
编辑距离(Levenshtein Distance)算法的应用场景非常广泛,以下是一些常见的应用领域:
1. 拼写检查:在文本编辑器或搜索引擎中,通过计算用户输入与标准词库中单词的编辑距离,可以提示可能的拼写错误,并给出正确的建议。
2. 模糊搜索:在搜索引擎中,即使用户输入的查询词与数据库中的词存在拼写差异,通过编辑距离算法也能找出相似的搜索结果。
3. DNA序列分析:在生物信息学中,编辑距离可以用来比较DNA序列之间的相似性,帮助研究基因变异和进化。
4. 抄袭侦测:在学术领域,编辑距离可以用来检测论文或文献之间的相似度,以识别可能的抄袭行为。
5. 语音识别:在自动语音识别系统中,编辑距离可以用于评估识别结果与实际文本的差异,从而优化识别算法。
6. 数据匹配:在数据清洗和整合过程中,编辑距离可以用来匹配和对齐不同来源的数据记录,尤其是在处理脱敏数据与原始数据匹配时。
7. 自然语言处理(NLP):在机器翻译、文本摘要、情感分析等NLP任务中,编辑距离可以用来评估生成文本与参考文本的相似度。
8. 推荐系统:在推荐系统中,编辑距离可以用来评估用户查询与商品描述之间的相关性,以提供更准确的推荐。
9. 文本分类:在文本分类任务中,编辑距离可以用来衡量文本样本与类别标签之间的相似度,辅助分类决策。
10. 错误侦测与纠正:在数据传输和存储过程中,编辑距离可以用于错误侦测和自动纠正,提高数据的准确性和可靠性。
编辑距离算法因其直观和有效性,在需要评估字符串相似度的各种场景中都有着重要的作用。
三、优缺点
编辑距离(Levenshtein)算法,用于计算两个字符串之间转换所需的最少单字符编辑操作次数,具有以下优缺点:
### 优点:
1. 直观性:算法基于直观的编辑操作(插入、删除、替换),容易理解和实现。
2. 有效性:能够准确地量化两个字符串之间的差异,是许多应用中评估字符串相似度的有效工具。
3. 广泛应用:在拼写检查、DNA序列分析、抄袭侦测、语音识别等多个领域都有应用。
4. 动态规划实现:通过动态规划方法,避免了不必要的重复计算,提高了计算效率。
### 缺点:
1. 计算成本:对于较长的字符串,算法的时间复杂度为O(mn),其中m和n是两个字符串的长度,可能导致计算成本较高。
2. 空间消耗:需要存储一个大小为(m+1) x (n+1)的矩阵,对于长字符串,空间消耗较大。
3. 语义信息缺失:算法基于字符编辑操作,不考虑字符串的语义信息,可能导致语义相似但表面形式不同的字符串被判定为不相似。
4. 优化空间:尽管可以使用一些技术减少空间复杂度(如只使用两个行向量),但在处理特别长的字符串时,算法仍然存在优化空间。
四、Python应用
编辑距离(Levenshtein Distance)算法在Python中的应用非常广泛:
### 示例代码:
以下是一个简单的Python函数,用于计算两个字符串之间的Levenshtein距离:
```python
def levenshtein_distance(s1, s2):
if len(s1) < len(s2):
return levenshtein_distance(s2, s1)
if len(s2) == 0:
return len(s1)
previous_row = range(len(s2) + 1)
for i, c1 in enumerate(s1):
current_row = [i + 1]
for j, c2 in enumerate(s2):
insertions = previous_row[j + 1] + 1
deletions = current_row[j] + 1
substitutions = previous_row[j] + (c1 != c2)
current_row.append(min(insertions, deletions, substitutions))
previous_row = current_row
return previous_row[-1]
# 使用示例
str1 = \"kitten\"
str2 = \"sitting\"
print(f\"The Levenshtein distance between '{str1}' and '{str2}' is {levenshtein_distance(str1, str2)}\")
```
### 优化版本:
为了减少空间复杂度,可以使用两个列表来代替整个矩阵:
```python
def levenshtein_distance_optimized(s1, s2):
if not s1: return len(s2)
if not s2: return len(s1)
if len(s1) > len(s2):
s1, s2 = s2, s1
size_x = len(s1) + 1
size_y = len(s2) + 1
row = [i for i in range(size_x)]
for i in range(1, size_y):
prev_row, row = row, [i] + [0] (size_x - 1)
for j in range(1, size_x):
cost = 0 if s1[j-1] == s2[i-1] else 1
row[j] = min(prev_row[j] + 1, row[j-1] + 1, prev_row[j-1] + cost)
return row[-1]
# 使用示例
str1 = \"kitten\"
str2 = \"sitting\"
print(f\"The optimized Levenshtein distance between '{str1}' and '{str2}' is {levenshtein_distance_optimized(str1, str2)}\")
```
这些示例展示了如何在Python中实现和使用Levenshtein距离算法。在实际应用中,可以根据具体需求调整和优化算法。
编辑距离算法的这些优缺点决定了它在特定应用场景下的有效性和适用性。在需要精确字符串匹配的场景中非常有用,但在处理大数据量或需要考虑语义信息的场景下可能需要与其他技术结合使用。
Levenshtein距离是一种非常有用的度量方法,广泛应用于计算机科学、生物学和语言学等领域。