HNSW(Hierarchical Navigable Small World)图即分层可导航小世界图,是一种用于在高维空间中进行近似最近邻搜索(Approximate Nearest Neighbor Search, ANN)的数据结构和算法,在向量数据库等领域有着广泛应用HNSW图的设计灵感来源于小世界网络理论。在小世界网络中,大多数节点彼此并不相邻,但任意两个节点之间的平均路径长度却相对较短。HNSW图通过构建多层图结构,将高维空间中的向量组织成一个具有层次结构的图,使得在图中可以高效地搜索到与查询向量最相似的向量。
一、构建过程
1. 初始化:从空图开始,将第一个向量作为图的初始节点。
2. 插入节点:对于后续的每个向量,将其作为一个新节点插入到图中。插入过程如下:
确定插入层次:通过一个概率函数随机确定新节点所在的层次。较高层次的节点数量较少,代表更全局的连接;较低层次的节点数量较多,代表更局部的连接。
搜索插入位置:从图的最高层开始,使用贪心搜索策略找到与新节点在当前层最接近的节点。然后,沿着该节点向下一层继续搜索,直到到达最底层。
建立连接:在最底层找到合适的插入位置后,将新节点与周围的一些邻居节点建立连接。同时,根据新节点所在的层次,在更高层也建立相应的连接。
3. 重复插入:不断重复上述插入节点的过程,直到所有向量都插入到图中。
二、搜索过程
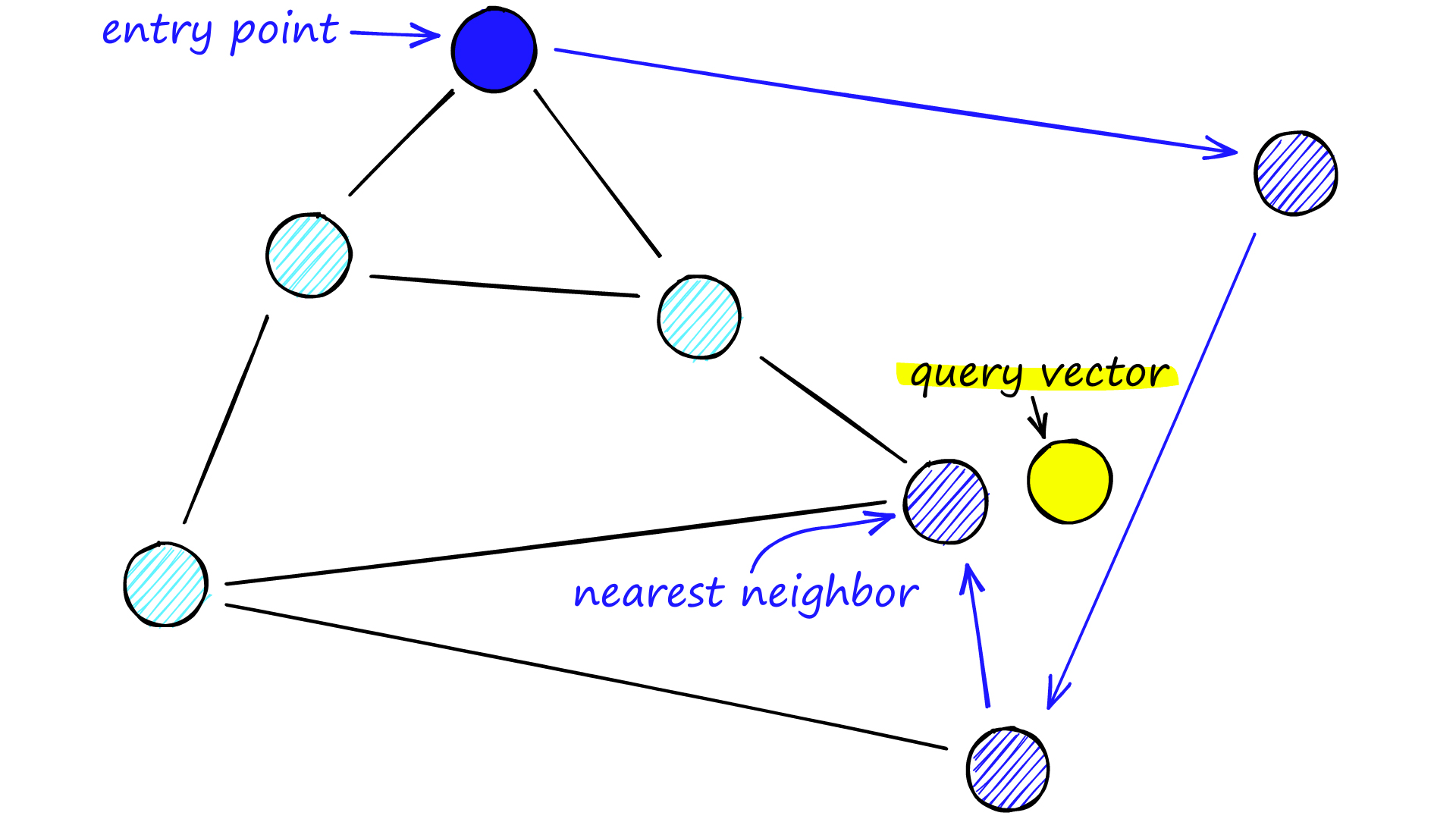
1. 初始化:从图的最高层开始,选择一个起始节点。
2. 贪心搜索:在当前层,从起始节点开始,不断选择与查询向量最接近的邻居节点,直到无法找到更近的邻居为止。
3. 向下移动:记录当前层找到的最接近节点,然后移动到下一层,以该节点作为新的起始节点,继续进行贪心搜索。
4. 终止条件:重复步骤2和3,直到到达最底层。在最底层找到的最接近节点即为查询向量的近似最近邻。
三、特点
1.高效性:HNSW图在高维空间中具有较高的搜索效率,尤其是在处理大规模数据集时,能够在较短的时间内找到近似最近邻。这是因为它通过分层结构和局部连接,减少了搜索的范围和复杂度。
2.准确性:与其他近似最近邻搜索算法相比,HNSW图能够提供较高的搜索准确性。通过在不同层次上进行搜索,它可以在全局和局部范围内同时寻找最近邻,从而提高了搜索结果的质量。
3.可扩展性:HNSW图支持动态插入和删除节点,这使得它可以适应数据的动态变化。在实际应用中,当有新的向量需要添加到数据库中,或者已有向量需要删除时,可以方便地对HNSW图进行更新。
4.参数可调:HNSW图有一些参数可以进行调整,如每层的最大连接数、节点插入的层次概率等。通过调整这些参数,可以在搜索效率和准确性之间进行权衡,以满足不同应用场景的需求。
四、性能评估
1.搜索准确性
召回率(Recall)
定义:召回率是指在搜索结果中,真正的最近邻被正确检索出来的比例。它衡量了HNSW图找到所有相关最近邻的能力。
计算方式:召回率 = (检索到的真正最近邻数量 / 所有真正最近邻数量)× 100%。例如,在一个包含100个最近邻的查询中,HNSW图检索到了80个,那么召回率就是80%。较高的召回率表示HNSW图能够更全面地找到最近邻,搜索结果更准确。
准确率(Precision)
定义:准确率是指在搜索结果中,真正的最近邻所占的比例。它反映了搜索结果的质量,即检索出的结果中有多少是真正需要的最近邻。
计算方式:准确率 = (检索到的真正最近邻数量 / 检索出的结果总数)× 100%。例如,检索出了20个结果,其中15个是真正的最近邻,那么准确率就是75%。
2.搜索效率
查询响应时间
定义:查询响应时间是指从提交查询到得到搜索结果所花费的时间。它是衡量HNSW图搜索效率的一个重要指标,对于实时性要求较高的应用场景尤为关键。
评估方法:可以通过多次执行相同或不同的查询,记录每次查询的响应时间,然后计算平均响应时间、最小响应时间和最大响应时间等统计指标。响应时间越短,说明HNSW图的搜索效率越高。
每秒查询率(QPS,Queries Per Second)
定义:每秒查询率表示HNSW图在单位时间内能够处理的查询数量。它反映了系统的并发处理能力和整体性能。
评估方法:在一定时间内,向HNSW图发送大量的查询请求,统计成功处理的查询数量,然后计算每秒的查询率。QPS越高,说明HNSW图能够处理更多的查询,搜索效率越好。
3.内存使用
内存占用量
定义:内存占用量是指HNSW图在运行过程中所占用的内存空间大小。对于大规模数据集和资源受限的环境,控制内存使用是非常重要的。
评估方法:可以使用操作系统提供的内存监控工具,在HNSW图构建和查询过程中实时监测其内存占用情况。或者在程序中使用特定的内存测量函数来获取内存使用信息。内存占用量越小,说明HNSW图的内存使用效率越高。
4.可扩展性
数据规模扩展性
定义:数据规模扩展性是指随着数据集规模的增加,HNSW图的性能(如搜索准确性、搜索效率等)的变化情况。一个好的HNSW图应该能够在数据规模增大时,仍然保持较好的性能。
评估方法:可以通过在不同规模的数据集上进行实验,记录搜索准确性、查询响应时间等指标的变化。如果随着数据规模的增加,这些指标的变化较小,说明HNSW图具有较好的数据规模扩展性。
并发扩展性
定义:并发扩展性是指在多个查询并发执行时,HNSW图的性能表现。在实际应用中,往往会有多个用户同时发起查询请求,因此需要评估HNSW图在并发情况下的处理能力。
评估方法:使用并发测试工具,模拟多个用户同时向HNSW图发送查询请求,记录系统的响应时间、每秒查询率等指标。如果在并发查询时,这些指标的下降幅度较小,说明HNSW图具有较好的并发扩展性。
五、应用场景
HNSW图凭借其在高维空间中高效进行近似最近邻搜索的特性,在众多领域都有广泛的应用场景:
1.信息检索领域
图像搜索:在图像数据库中,每幅图像通过特征提取算法(如卷积神经网络)转化为高维向量。HNSW图可用于存储这些图像向量,并快速找到与查询图像最相似的图像。例如,在一个拥有数百万张图片的图像库中,当用户上传一张图片进行搜索时,HNSW图能在短时间内从海量数据中找出相似的图片,为用户提供相关的图像搜索结果,广泛应用于电商平台的商品图片搜索、图片素材网站的搜索服务等场景。
文本搜索:对于大规模的文本数据,可将文本转换为向量表示(如使用词嵌入模型)。HNSW图可以对这些文本向量进行高效的组织和搜索。在搜索引擎、文档管理系统中,当用户输入查询文本时,系统将其转换为向量,利用HNSW图快速找到与查询文本语义最相近的文档,实现语义搜索功能,提高搜索的准确性和效率。
2.推荐系统领域
商品推荐:电商平台会收集用户的浏览历史、购买记录等信息,并将这些信息转化为用户向量,同时将商品的特征(如类别、价格、品牌等)表示为商品向量。HNSW图可以存储这些向量,通过计算用户向量和商品向量之间的相似度,快速找出与用户兴趣最匹配的商品,为用户提供个性化的商品推荐,增加用户的购买转化率和平台的销售额。
内容推荐:在社交媒体、新闻资讯、视频平台等领域,根据用户的行为数据(如点赞、评论、观看记录等)生成用户向量,将文章、视频等内容转化为内容向量。HNSW图能够在海量的内容向量中迅速找到与用户向量相似的内容,为用户推荐符合其兴趣的文章、视频等,提高用户的使用体验和平台的用户粘性。
3.机器学习与数据挖掘领域
聚类分析:在聚类算法中,需要快速找到数据点之间的最近邻。HNSW图可以用于加速聚类过程,提高聚类算法的效率。例如,在基于密度的聚类算法中,通过HNSW图快速找到每个数据点的邻居,从而确定数据点的密度和聚类结构。
异常检测:在异常检测任务中,将正常数据点的特征表示为向量并构建HNSW图。当有新的数据点出现时,通过计算其与HNSW图中向量的距离,判断该数据点是否为异常点。如果距离超过一定阈值,则认为该数据点可能是异常点。这种方法可以快速有效地检测出数据中的异常情况,应用于网络安全、金融风险监测等领域。
4.生物信息学领域
基因序列比对:在生物信息学中,基因序列可以表示为高维向量。HNSW图可以用于快速比对基因序列,找到相似的基因序列。在基因研究、疾病诊断等方面,通过快速准确地比对基因序列,有助于发现基因的功能、疾病的遗传机制等,为生物医学研究提供有力支持。
蛋白质结构预测:蛋白质的结构信息也可以转化为向量表示。HNSW图可以帮助在蛋白质结构数据库中快速搜索相似的蛋白质结构,对于理解蛋白质的功能、药物研发等具有重要意义。通过找到相似的蛋白质结构,可以推测未知蛋白质的功能,为药物设计提供参考。