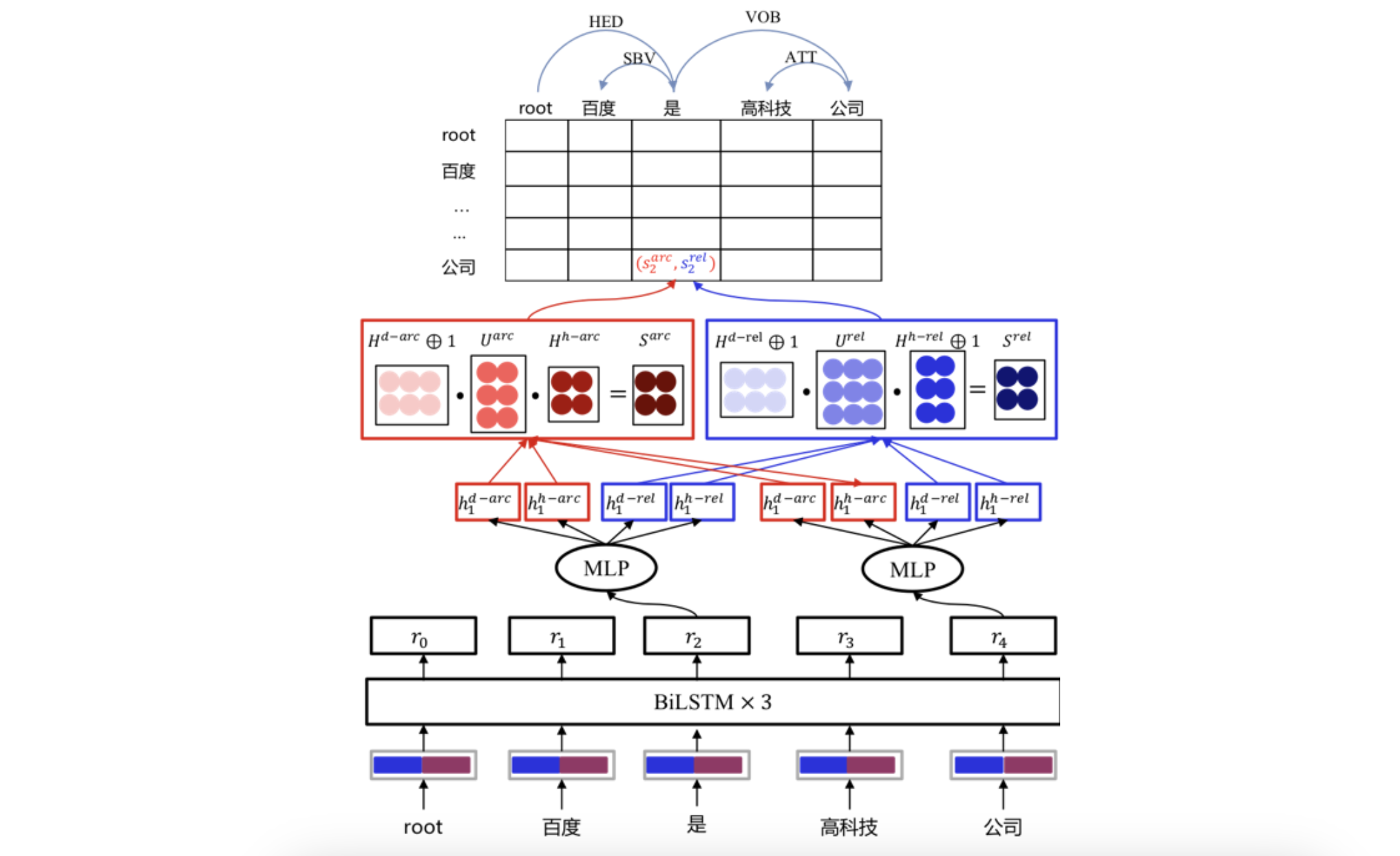
DDParser由百度基于大规模标注数据和深度学习平台飞桨研发的中文依存句法分析工具。它采用简单易理解的标注体系,支持一键安装部署及调用,适合开发者快速学习及使用。
能够直接获取输入文本中的关联词对、长距离依赖词对等信息。其训练数据丰富,覆盖多种场景,在随机数据上的准确率较高,并且输入层加入了词的字符级别表示,缓解了因粒度不同带来的效果下降问题。
支持 Python 一键安装,使用方便。用户可以通过 `pip install ddparser` 进行安装,然后使用 `from ddparser import ddparser` 导入并创建实例来解析文本,如 `ddp = ddparser()`,最后使用 `ddp.parse(\"百度是一家高科技公司\")` 来进行句法分析。
一、概念
1.依存关系定义:依存关系是指句子中的一个词(称为支配词)和另一个词(称为从属词)之间存在的一种语法或语义上的关联。比如在句子“小明吃苹果”中,“吃”是支配词,“小明”和“苹果”是从属词,“小明”与“吃”存在施事(动作执行者)的依存关系,“苹果”与“吃”存在受事(动作对象)的依存关系。
2.依存关系类型:DDParser能够识别多种依存关系类型。常见的包括主谓关系(SBV),如“太阳升起”中的“太阳”和“升起”;动宾关系(VOB),像“写文章”中的“写”和“文章”;定中关系(ATT),例如“美丽的花朵”中的“美丽”和“花朵”。这些关系类型有助于深入挖掘句子的结构和语义。
在机器翻译中,理解源语言句子的依存关系有助于生成更符合目标语言语法和语义的句子。例如,在将中文句子翻译成英文时,通过分析中文句子中的主谓宾等依存关系,能够更准确地在英文中安排单词的顺序和语法结构,使翻译结果更加自然流畅。
依存句法分析可以辅助语义角色标注。语义角色标注是确定句子中各个成分所扮演的语义角色,如施事、受事、时间、地点等。DDParser分析出的依存关系能够为语义角色标注提供重要线索,帮助确定每个词语在句子中的语义角色。例如,在“小李在图书馆看书”这个句子中,依存句法分析可以帮助确定“小李”是施事,“书”是受事,“图书馆”是地点,从而更好地进行语义角色标注。
在从文本中提取特定信息时,依存句法分析能够帮助定位关键信息及其相互关系。例如,在处理企业财务报表文本时,可以通过依存关系找到财务指标和相关主体之间的关系,从而提取出重要的财务信息。
二、工作原理
1.基于深度学习模型:DDParser很可能是基于深度学习架构来实现的,比如Transformer架构或者其变体。这些模型通过大量的文本数据进行训练,学习句子的语法和语义模式。以Transformer为例,它的多头注意力机制可以同时关注句子的不同部分,捕捉词语之间的远距离依存关系。例如,在处理长句子时,能够有效地发现句子开头的主语和句子末尾的宾语之间的关系。
2.训练数据的使用:在训练过程中,使用了大量标注有依存关系的语料库。这些语料库包含了各种类型的句子,涵盖不同的领域和语言风格。通过对这些标注数据的学习,DDParser能够归纳出词语之间依存关系的规律。例如,对于新闻领域的句子,它可以学习到新闻标题和正文内容在语法结构上的常见模式。
三、特点和优势
1.高精度分析:DDParser能够提供较为准确的依存句法分析结果。这得益于其基于深度学习的强大模型和大量的训练数据。在处理复杂句子结构和多种语言表达时,能够有效地识别词语之间的依存关系,为后续的自然语言处理任务提供可靠的语法和语义信息。
2.支持多种语言:该工具可能支持多种语言的依存句法分析。在跨语言自然语言处理应用中具有很大的优势。例如,对于一个跨国公司的多语言文档处理系统,可以使用DDParser同时对中文、英文、法文等多种语言的句子进行依存句法分析,方便信息提取和知识共享。
3.易于集成:它可能具有良好的接口,易于集成到其他自然语言处理系统或应用程序中。开发者可以方便地将DDParser的功能嵌入到自己的软件中,用于增强语言处理能力。例如,在一个文本编辑软件中集成DDParser,可以为用户提供语法检查和语义提示等功能。
四、应用场景
1. 智能写作辅助
语法检查与纠错:在写作过程中,DDParser可以分析句子的依存关系,帮助用户检查语法错误。例如,对于句子“我看见了在天空中飞翔的鸟”,它可以识别出词语之间的正确依存关系,如“我 看见(主谓关系)”、“看见 鸟(动宾关系)”、“鸟 飞翔(主谓关系)”等。如果用户写成“我看见了鸟飞翔在天空中”,DDParser能够发现这种不符合正常语法依存关系的情况,提醒用户进行修改。
风格优化与词汇推荐:通过分析句子的结构,它还可以为写作风格优化提供建议。比如,在学术写作中,它可以根据依存关系判断句子是否符合学术规范的表达习惯。同时,根据已有的依存关系和语义,为用户推荐更合适的词汇。例如,在一个科技论文写作场景中,如果用户经常使用比较简单的词汇来描述技术概念,DDParser可以结合句子依存关系,推荐一些更专业、更准确的技术词汇来替换。
2. 智能问答系统
问题理解:当用户提出一个问题时,DDParser可以对问题句子进行依存关系分析,帮助系统更好地理解问题的核心。例如,对于问题“如何提高网站的流量?”,它可以识别出“提高”和“流量”的动宾关系,以及“如何”对“提高”的修饰关系,这样系统就能明确用户是在询问提高流量的方法。
答案提取与生成:在答案提取方面,DDParser可以用于分析答案文档中的句子结构。在文档中找到与问题中依存关系相匹配的内容作为答案。例如,在一个包含网站运营知识的文档中,通过分析句子的依存关系,找到“通过搜索引擎优化可以提高网站流量”这样的句子,提取其中的有效信息作为答案。对于需要生成答案的情况,依存句法分析可以确保生成的答案在语法和语义上是合理的,符合自然语言的表达习惯。
3. 文本翻译
源语言分析:在机器翻译过程中,DDParser首先对源语言句子进行依存关系分析。例如,对于中文句子“他送给她一束鲜花”,分析出“他 送(主谓关系)”、“送 她(双宾关系)”、“送 鲜花(动宾关系)”等依存关系。这些信息对于理解句子的语义和语法结构非常关键,尤其是对于一些具有复杂语法结构的句子,如含有多个宾语或修饰成分的句子。
目标语言生成:根据源语言句子的依存关系,在生成目标语言句子时可以更合理地安排单词顺序和语法结构。以将上述中文句子翻译成英文“He sent her a bunch of fresh flowers”为例,依存句法分析的结果有助于确定各个单词在英文句子中的位置和语法关系,使得翻译后的句子更符合英语的表达习惯,提高翻译质量。
4. 信息抽取与知识图谱构建
实体关系抽取:在文本中抽取实体及其相互关系是信息抽取的重要任务。DDParser可以通过分析句子的依存关系来识别实体和关系。例如,在新闻报道“苹果公司发布了新款iPhone”中,通过依存关系分析可以确定“苹果公司”和“新款iPhone”这两个实体,以及它们之间“发布”的关系,从而方便地将这些信息抽取出来,用于构建知识图谱或其他信息存储系统。
知识图谱更新与维护:对于已经构建的知识图谱,DDParser可以帮助检查和更新图谱中的实体关系。当有新的文本信息输入时,它可以分析其中的依存关系,判断是否有新的实体或关系需要添加到知识图谱中,或者是否需要对已有的关系进行修改,以保证知识图谱的准确性和完整性。
5. 文本分类与情感分析
文本分类辅助:在文本分类任务中,依存句法分析可以提供额外的特征。例如,在新闻分类中,通过分析句子的依存关系可以判断新闻的主题方向。对于一篇科技新闻,DDParser可以通过分析句子中关于技术产品、研发等相关词语的依存关系,帮助确定这篇新闻属于科技类别,而不是体育或娱乐类别。
情感分析深度洞察:在情感分析中,依存句法分析可以帮助深入了解情感表达的结构。例如,在影评中,通过分析句子中评价性词语(如“精彩”、“糟糕”)与电影相关实体(如电影名称、演员名字)之间的依存关系,可以更准确地判断评论者的情感倾向是正面还是负面,以及这种情感是针对电影的哪个方面(如剧情、表演)。