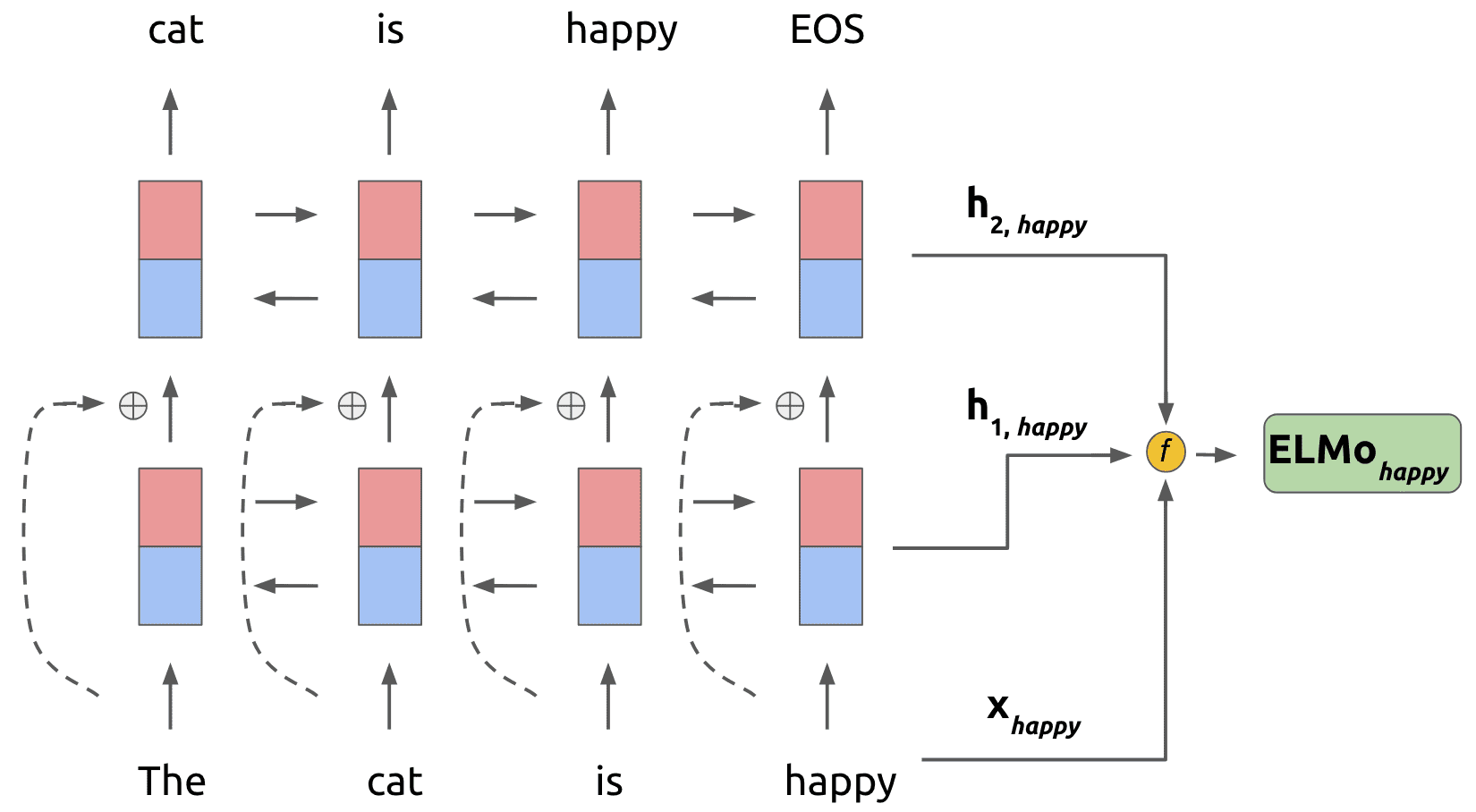
ELMo(Embeddings from Language Models)是由艾伦人工智能研究所(Allen Institute for AI)开发的一种深度双向语言模型。它在自然语言处理(NLP)领域是一个重要的进展,主要用于生成词向量,这些词向量能够更好地捕捉单词在上下文中的语义信息。在ELMo出现之前,传统的词向量(如Word2Vec和GloVe)是静态的,即一个单词在任何语境下都有相同的向量表示,这无法很好地适应单词在不同句子中的语义变化。
一、架构特点
1.基于LSTM的架构:ELMo使用了多层双向长短期记忆网络(LSTM)。LSTM是一种特殊的循环神经网络(RNN),它能够有效地处理序列数据中的长短期依赖关系。在自然语言处理中,句子就是一个序列,单词之间存在语法和语义上的依赖关系。例如,在句子“因为下雨,所以我带了伞”中,“下雨”和“带伞”之间存在因果关系,LSTM可以通过其内部的记忆单元来捕捉这种关系。
2.深度双向语言模型:ELMo从两个方向(正向和反向)对文本进行处理。正向LSTM从句子的开头开始处理单词,预测下一个单词;反向LSTM从句子的末尾开始处理单词,预测前一个单词。例如,对于句子“我爱读书”,正向LSTM在处理“我爱”时预测“读书”,反向LSTM在处理“读书”时预测“我爱”。然后,ELMo将这两个方向的LSTM输出进行组合,为每个单词生成一个综合的向量表示。
3.多层表示融合:ELMo包含多个LSTM层,不同层可以捕捉到不同层次的语义信息。例如,较低层可能更关注单词的语法特征,如词性;较高层可能更关注句子的整体语义。ELMo通过对不同层的输出进行加权组合,来得到最终的单词表示。这种方式使得单词表示能够融合不同层次的语义信息,更灵活地适应不同的语境。
二、预训练和应用方式
1.预训练任务:ELMo的预训练主要基于语言模型任务。语言模型的目标是预测序列中的下一个单词(正向)或前一个单词(反向)。在大量的文本语料上进行这样的预训练,使得ELMo能够学习到语言的统计规律和语义信息。例如,在预训练过程中,它会学习到在“美丽的”后面更可能出现“风景”等词汇。
2.应用于下游任务:在下游任务(如词性标注、命名实体识别、情感分析等)中,ELMo将预训练得到的单词表示作为输入特征提供给任务模型。例如,在词性标注任务中,任务模型可以利用ELMo提供的单词在上下文中的动态表示,更准确地判断单词的词性,如判断“跑步”在“我喜欢跑步”中是动词。通常,ELMo的词向量与任务模型的其他输入特征(如手工特征)相结合,共同完成下游任务。
三、缺陷
1. 计算效率方面
顺序计算的局限性:ELMo基于长短时记忆网络(LSTM)架构,LSTM是顺序处理数据的。这意味着在处理文本序列时,它必须按照单词的顺序依次计算,无法像Transformer架构那样进行并行计算。例如,当处理一个很长的句子时,随着句子长度的增加,计算时间会显著增长。这种顺序计算的方式在处理大规模文本数据时效率较低,尤其是在预训练阶段,需要大量的时间来处理语料库中的文本。
硬件资源占用问题:由于LSTM的递归性质,在训练过程中需要存储每个时间步(即每个单词处理阶段)的中间状态信息,这对硬件内存(如GPU内存)有较高的要求。特别是当模型层数增加或者处理长文本时,内存占用问题会更加突出。这可能会限制模型的规模或者需要更强大的硬件设备来支持训练,增加了训练成本。
2. 语义理解方面
复杂语义关系的处理不足:尽管ELMo是双向语言模型,能够在一定程度上结合上下文信息,但对于一些复杂的语义关系,如隐喻、反讽等,理解起来仍然存在困难。例如,在句子“他的笑容像阳光,却冷得让人发抖”中,其中包含的反讽语义对于ELMo来说是一个挑战。它主要基于单词的顺序和统计规律来理解语义,对于这种深层次的语义转折和情感冲突,很难准确把握。
对长距离依赖的捕捉有限:虽然LSTM设计目的是处理长短期依赖关系,但在实际应用中,对于非常长的文本序列中的长距离依赖,其效果可能会受到影响。例如,在处理长篇小说或者技术文档等长文本时,文本开头的信息可能对结尾部分的理解有重要作用,但ELMo可能会在捕捉这种长距离依赖关系时丢失部分信息,从而影响对整个文本语义的准确理解。
3. 模型架构方面
缺乏并行性的架构限制:如前面提到的,ELMo的LSTM架构缺乏并行性,这不仅影响计算效率,也限制了模型在处理大规模数据时的扩展性。相比之下,Transformer架构的BERT等模型能够通过多头注意力机制实现并行计算,在相同的硬件条件下可以处理更多的数据或者构建更大规模的模型,以获取更强大的语言表示能力。
深度双向架构的潜在问题:ELMo的深度双向架构虽然能够有效利用上下文信息,但在某些情况下可能会导致信息冗余或混淆。例如,在处理具有复杂语法结构的句子时,正向和反向的信息融合可能会引入一些噪声,使得模型在确定单词的准确语义表示时出现偏差。而且,随着模型深度的增加,这种信息冗余和混淆的可能性也会增加。
4. 预训练和微调方面
预训练任务的局限性:ELMo的预训练主要基于语言模型任务,即预测下一个单词(正向)或前一个单词(反向)。这种预训练任务相对比较单一,可能无法充分学习到文本的所有语义信息。与BERT的掩码语言模型(MLM)和下一句预测(NSP)等多种预训练任务相比,ELMo在预训练阶段获取的语言知识可能不够全面。
微调效果的不稳定性:在将ELMo应用于下游任务并进行微调时,其性能可能会受到多种因素的影响,如微调数据集的大小、数据分布等。由于ELMo的架构特点和预训练方式,它可能需要更多的微调数据和更精细的微调策略才能达到较好的效果。而且,在不同的下游任务和数据集之间,微调后的性能稳定性可能不如其他一些先进的语言模型。
四、应用领域
1. 词性标注
原理深入:
ELMo的双向语言模型架构是其在词性标注应用中的关键优势。在自然语言句子中,单词的词性并非固定不变,而是受周围词汇和句子结构的影响。例如,“run”这个词,在“He is on a run”中是名词,意思是“跑步;行程”,而在“He likes to run”中是动词,意思是“跑”。ELMo通过正向和反向的LSTM来处理句子,能够充分考虑前后文信息。正向LSTM从句子开头逐步处理单词,学习单词序列中的正向语法和语义信息;反向LSTM从句子末尾反向处理,学习反向的信息。这两个方向的信息在每一个单词位置上进行融合,生成一个与上下文紧密相关的词向量。对于词性标注任务,这种上下文敏感的词向量能够更好地反映单词在特定语境下的词性特征。
应用细节:
在实际应用中,假设我们有一个包含大量句子的语料库用于词性标注。当使用ELMo时,对于每个句子中的单词,先通过ELMo模型得到其上下文相关的词向量。然后将这些词向量作为输入特征,输入到一个分类器中,这个分类器可以是基于传统机器学习算法(如支持向量机)或者深度学习算法(如神经网络)构建的。以神经网络分类器为例,它可以是一个简单的多层感知机,将ELMo词向量映射到不同词性类别对应的概率分布上。例如,对于英语中的常见词性,如名词、动词、形容词、副词等,分类器会输出每个单词属于这些词性的概率,最终确定单词的词性。与传统的基于词表的词性标注方法相比,ELMo能够显著提高标注的准确性,尤其是在处理具有复杂语法结构或多义词的句子时。
2. 命名实体识别(NER)
原理深入:
在命名实体识别中,准确识别文本中的人名、地名、组织机构名等实体是关键。ELMo的深度双向架构使其能够很好地处理实体边界和类型识别问题。从架构上看,ELMo的多层LSTM可以捕捉到不同层次的语义信息。对于命名实体,通常会在文本中以特定的词汇组合形式出现,并且其周围的词汇也会提供线索。例如,在识别组织机构名时,像“Microsoft Corporation”这个实体,其前后可能会出现与商业活动相关的词汇,如“develops”(开发)、“products”(产品)等。ELMo通过双向处理,能够将这些线索整合到对实体的识别过程中。在较低层的LSTM中,可能会捕捉到单词的基本语法和局部语义信息,比如识别单词是名词;在较高层的LSTM中,会结合更广泛的上下文信息,将这些名词组合判断为一个命名实体。
应用细节:
在实际的NER系统中,ELMo词向量可以与其他特征(如字符级特征)结合使用。例如,对于一个包含大量新闻文章的数据集,首先通过ELMo模型为每个单词生成上下文相关的词向量。然后,将这些词向量与字符级特征(如单词的首字母大写、是否包含数字等)拼接在一起,作为一个更丰富的输入特征向量。这个特征向量被输入到一个命名实体识别模型中,这个模型可以是基于条件随机场(CRF)或者双向LSTM CRF架构构建的。在训练过程中,模型学习根据这些综合特征来准确地识别实体边界和类型。与单独使用字符级特征或传统词向量的方法相比,融入ELMo词向量能够提高对复杂实体(如嵌套实体、模糊实体边界的实体)的识别能力。例如,在医学文献中,对于复杂的疾病名称和药物名称组合的实体识别,ELMo能够更好地利用上下文信息,减少错误识别。
3. 语义角色标注(SRL)
原理深入:
语义角色标注要求确定句子中每个单词所扮演的语义角色,如施事者(agent)、受事者(patient)、工具(instrument)等。ELMo的多层双向LSTM结构在这个任务中有很大的优势。在句子结构和语义理解方面,不同层次的LSTM能够捕捉到不同深度的语义关系。例如,在句子“The boy hit the ball with a bat”中,最底层的LSTM可能会识别单词的基本语法角色,如“hit”是动词;中层的LSTM会开始考虑单词之间的关系,识别出“boy”和“hit”之间的主谓关系;高层的LSTM则会结合更广泛的上下文,包括“with a bat”这个工具状语,完整地确定每个单词的语义角色,即“boy”是施事者,“ball”是受事者,“bat”是工具。ELMo通过对句子的双向处理,能够从前后两个方向捕捉这些语义线索,并且将不同层次的语义信息融合到最终的词向量中,为语义角色标注提供全面的语义支持。
应用细节:
在构建语义角色标注系统时,ELMo词向量作为输入特征发挥着关键作用。以一个包含各种类型句子的语义角色标注任务为例,对于每个句子,先通过ELMo模型生成单词的上下文相关词向量。这些词向量被输入到一个基于深度学习架构的语义角色标注模型中,如基于Transformer或者双向LSTM 注意力机制(Attention Mechanism)的模型。在训练过程中,模型学习根据ELMo提供的词向量以及句子的其他结构特征(如句子的语法树结构,如果有的话)来确定每个单词的语义角色。在处理复杂句子时,比如包含多个从句或隐喻的句子,ELMo的优势更加明显。例如,在文学作品中,句子“He was a wolf in sheep's clothing”这样的隐喻句,ELMo可以帮助模型更好地理解句子的整体语义,从而准确地标注出每个单词的语义角色,如“he”是具有“wolf”特征的主体。
4. 机器翻译
原理深入:
在机器翻译中,理解源语言句子的语义对于生成高质量的目标语言句子至关重要。ELMo的动态词向量能够为源语言句子的理解提供丰富的上下文语义信息。其双向处理机制可以充分挖掘单词在句子中的语义。以翻译一个具有多种含义的源语言单词为例,如法语中的“livre”,它有“书”和“英镑”两个意思。在句子“J'ai acheté un livre”(我买了一本书)和“Le livre est fort contre le dollar”(英镑对美元很强劲)中,ELMo通过对句子的正向和反向处理,结合句子中的其他词汇(如“acheté”(买)和“dollar”(美元)),能够准确判断“livre”在不同句子中的意思。对于翻译模型,这种准确的语义理解是生成正确目标语言句子的基础。ELMo还可以捕捉句子中的语法结构信息,例如句子中的主谓宾关系等,这对于按照目标语言的语法规则进行翻译也非常重要。
应用细节:
在实际的神经机器翻译系统中,ELMo通常被集成到编码器部分。对于源语言句子,先通过ELMo模型生成单词的上下文相关词向量,这些词向量替代或补充传统的词向量作为编码器的输入。编码器根据这些丰富的输入信息,将源语言句子转换为一个语义表示向量。这个语义表示向量再通过解码器生成目标语言句子。在训练过程中,翻译系统会根据大量的双语平行语料进行训练,同时优化ELMo的参数和翻译模型的其他参数。例如,在英法机器翻译任务中,使用ELMo可以帮助翻译系统更好地处理具有文化差异和语义模糊的词汇,生成更符合目标语言表达习惯的句子。同时,在处理句子结构差异较大的语言对时,ELMo所提供的语法结构信息也能够帮助翻译模型进行更合理的句子结构调整,从而减少翻译错误。
5. 情感分析
原理深入:
情感分析任务的目标是判断文本所表达的情感倾向,如正面、负面或中性。ELMo的上下文相关词向量能够有效捕捉文本中的情感线索。在句子中,情感词的含义往往会受到上下文的影响。例如,“这个产品虽然价格高,但是质量很好”,其中“价格高”可能带有负面倾向,但“质量很好”又有正面倾向。ELMo通过双向处理句子,能够综合考虑这些正负情感线索。它从正向处理句子时可以捕捉到情感词出现的先后顺序和相互关系,从反向处理时又能进一步强化对这些关系的理解。而且,ELMo的多层架构能够挖掘不同层次的情感信息,比如较低层可能捕捉到单个情感词的基本情感倾向,较高层则结合句子整体的结构和其他词汇来综合判断情感。
应用细节:
在实际的情感分析应用中,对于社交媒体评论、产品评论等文本,先通过ELMo模型为每个单词生成上下文相关词向量。这些词向量可以作为输入特征,输入到一个情感分类模型中。这个模型可以是基于深度学习的神经网络,如循环神经网络(RNN)或Transformer架构的模型。在训练过程中,模型学习根据ELMo词向量来判断文本的情感倾向。与传统的基于词袋模型(Bag of Words)的情感分析方法相比,ELMo能够更好地处理评论中的复杂情感表达,如讽刺、委婉等。例如,在分析电商平台上的产品评论时,ELMo可以识别出评论“这个产品的包装真是‘别具一格’”中的讽刺意味,从而准确判断评论者的负面情感,为商家提供更准确的消费者反馈信息。