BERT和ELMo作为自然语言处理领域两个大神,自诞生以来,便以其独特的技术架构与卓越的表现,在推动该领域发展的进程中扮演着举足轻重的角色。
在BERT横空出世之前,自然语言处理领域虽已取得一定进展,但传统词嵌入方法,如Word2Vec和GloVe,却有着难以忽视的短板。它们赋予每个单词的是静态的向量表示,无法依据单词所处上下文的不同而灵动变化,这使得模型在面对复杂语义场景时往往力不从心。
几乎同一时期,ELMo也以其独特的魅力崭露头角。在ELMo诞生前,语言模型的发展历经了从传统统计方法到基于深度学习的RNN、LSTM等模型的转变。BERT和ELMo虽然在技术路径上各有千秋,但它们共同推动了自然语言处理领域迈向预训练模型的新时代,为后续更多强大模型的诞生与发展奠定了坚实基础,使得自然语言处理技术在智能交互、信息检索、文本生成等诸多实际应用场景中不断取得突破与创新。
一、发展过程
1.BERT的发展过程
诞生背景:在BERT之前,自然语言处理领域已经有了一定的发展,但对于语言的理解和表示仍存在局限性。传统的词嵌入方法如Word2Vec和GloVe等,虽然能够将单词映射到向量空间,但无法很好地捕捉单词在不同上下文中的语义变化。2017年,Transformer架构的提出为自然语言处理带来了新的思路和方法,为BERT的诞生奠定了基础。
模型提出与发布:2018年,Google发布了BERT模型,开启了预训练时代的序幕。BERT采用双向注意力机制进行语言建模,通过掩码预训练任务和下一句预测任务获得了强大的语言理解能力,在多个自然语言处理任务上刷新了记录。
开源与推广:在论文发布后,Google很快开源了BERT的代码,并提供了在大规模数据集上预训练好的模型供大家下载和使用。这使得BERT能够被广泛应用和进一步研究,推动了整个自然语言处理领域的发展。此后,研究人员基于BERT进行了大量的改进和扩展工作,如优化模型结构、改进预训练任务、增加模型规模等,不断提升BERT在各种任务上的性能。
2.ELMo的发展过程
早期语言模型的发展基础:在ELMo出现之前,语言模型已经在自然语言处理领域得到了广泛的研究和应用。传统的语言模型主要基于统计方法,如ngram模型,通过计算单词序列的概率来预测下一个单词。随着深度学习的兴起,循环神经网络(RNN)特别是长短期记忆网络(LSTM)被应用于语言模型中,取得了更好的效果。这些工作为ELMo的提出奠定了基础。
模型提出与创新:2018年,由Matthew Peters等人提出了ELMo。ELMo的核心创新是采用了深度双向语言模型(Deep Bidirectional Language Model,BiLM),能够学习到单词的上下文相关表示。它通过在大规模文本语料上预训练双向LSTM模型,为每个单词生成基于上下文的词嵌入。这些词嵌入能够根据单词在句子中的位置和上下文动态变化,从而更好地捕捉语义信息。
应用与影响:ELMo在提出后,迅速在自然语言处理领域引起了广泛的关注和应用。它在词性标注、语法分析、语义角色标注等多个自然语言处理任务上取得了显著的改进,证明了深度双向语言模型在自然语言处理中的有效性。ELMo的出现也推动了自然语言处理领域对于预训练模型和上下文相关词嵌入的研究,为后续BERT等更强大的预训练模型的发展提供了借鉴和启示。
二、双方比较
1. 架构特点
BERT:
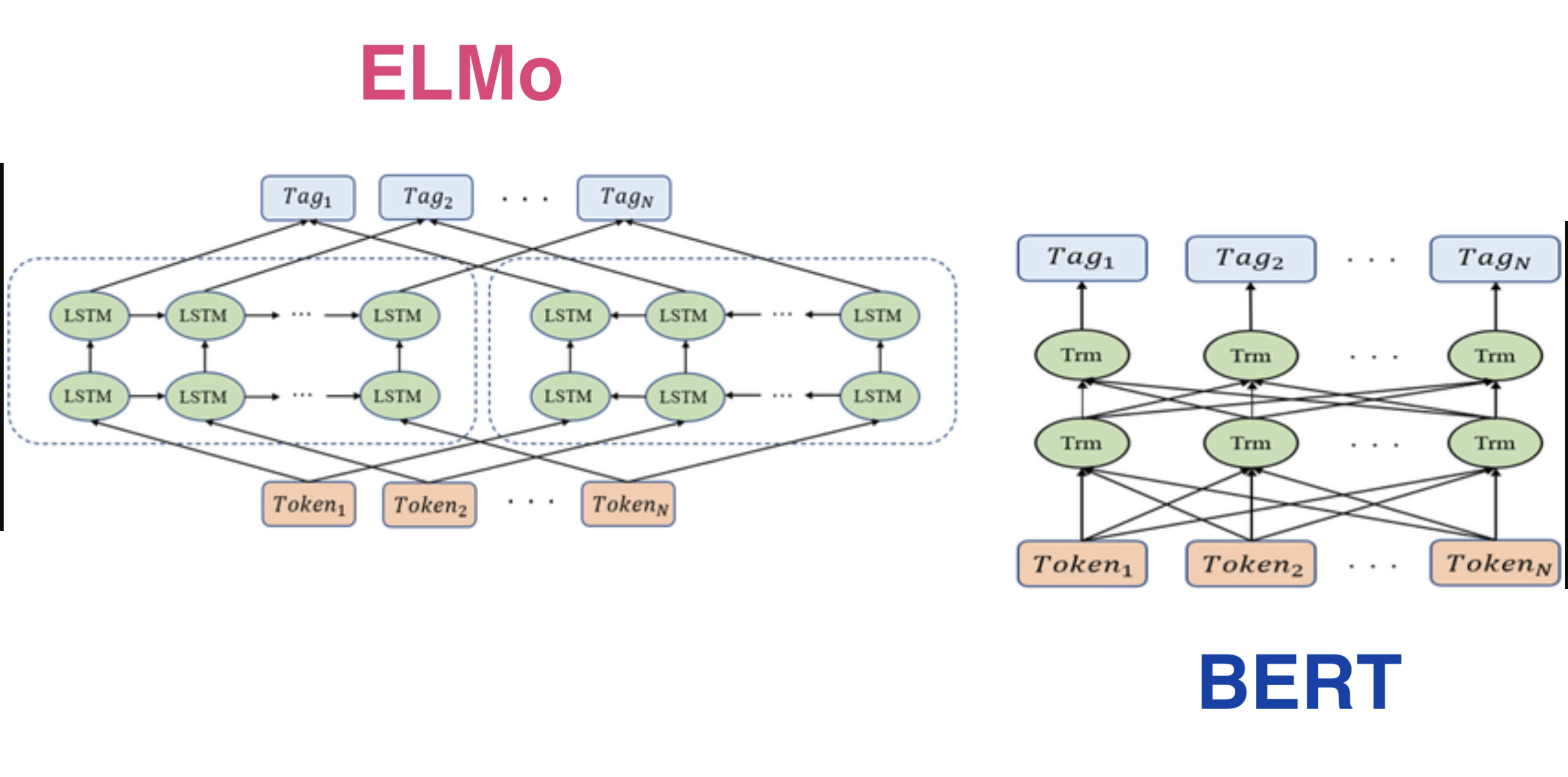
基于Transformer架构:Transformer架构的核心是多头注意力(Multi Head Attention)机制。这种机制可以让模型在不同的表示子空间中同时关注输入序列的不同部分。例如,在处理一个句子时,模型可以通过多头注意力机制将句子中的主语和宾语联系起来,就像在“猫追老鼠”这个句子中,注意力机制能够很好地关联“猫”和“老鼠”这两个语义相关的部分。这种并行计算的特性使得BERT在处理长序列文本时效率更高,能够有效捕捉文本中的语义关系。
无递归结构:与ELMo所基于的LSTM架构不同,BERT没有递归结构,不需要按顺序处理文本序列,从而避免了LSTM在处理长序列时可能出现的梯度消失或梯度爆炸问题。这使得BERT能够更好地处理长文本中的长距离依赖关系。
ELMo:
基于LSTM架构:LSTM是一种特殊的循环神经网络(RNN),它能够处理序列数据中的长短期依赖关系。在ELMo中,通过多层双向LSTM来处理文本。例如,在处理一个句子时,正向的LSTM从句子开头开始,依次处理每个单词,学习单词序列中的正向语法和语义信息;反向的LSTM从句子末尾开始,反向处理单词,学习反向的信息。然后将两个方向的信息进行组合,为每个单词生成一个综合的向量表示。
顺序处理特性:由于LSTM的递归性质,ELMo在处理文本时是顺序的,即一个单词一个单词地处理。这种顺序处理方式在处理长文本时效率相对较低,而且在处理过程中需要存储每个时间步(每个单词处理阶段)的中间状态信息,对硬件内存(如GPU内存)有较高的要求。
2. 预训练任务和目标
BERT:
掩码语言模型(MLM):这是BERT的核心预训练任务之一。在输入文本中,会随机地将一些单词替换为特殊的[MASK]标记。例如,对于句子“我[MASK]北京”,模型需要根据上下文(如“我”和“北京”)来猜测被掩码的单词可能是“去”“在”等。并且,为了避免模型在预训练和微调阶段的差异过大(因为在实际应用中没有[MASK]标记),在选择要掩码的单词时,实际上只有80%的概率会替换为[MASK],10%的概率会替换为其他随机单词,10%的概率保持原单词不变。
下一句预测(NSP):同时输入两个句子,让模型判断第二个句子是否是第一个句子的下一句。例如,对于句子对“我喜欢阅读。我经常去图书馆”和“我喜欢阅读。我喜欢跑步”,模型需要判断哪一对句子是连续的。这个任务有助于模型理解句子之间的连贯性和语义关系。
目标:学习到文本中单词的双向上下文表示,以便更好地用于各种下游任务,如文本分类、问答系统等。
ELMo:
语言模型预测任务:主要基于语言模型的预测任务,即给定一个单词序列,预测下一个单词(正向)或前一个单词(反向)。例如,对于句子“我爱读书”,正向预测任务是在“我爱”的基础上预测“读书”,反向预测任务是在“读书”的基础上预测“我爱”。
目标:提供基于字符的词嵌入,这种词嵌入能够根据单词在句子中的位置和上下文动态变化,从而更好地捕捉语义信息,用于下游的自然语言处理任务。
3. 语义理解能力
BERT:
深度双向理解优势:由于其双向训练的方式和Transformer架构的多头注意力机制,BERT能够很好地理解句子的整体语义。在处理复杂语义关系时,如隐喻、反讽等,相对ELMo有更好的表现。例如,在句子“他的笑容像阳光,却冷得让人发抖”中,BERT能够更好地捕捉这种语义转折和反讽的情感。
对长距离依赖的处理:能够有效地处理文本中的长距离依赖关系。通过多头注意力机制,即使在长文本中,也可以将相隔较远的语义相关部分联系起来,从而更准确地理解文本的完整语义。
ELMo:
上下文相关的词向量:ELMo通过双向LSTM为每个单词生成上下文相关的词向量,能够在一定程度上捕捉上下文信息来理解语义。然而,对于复杂语义关系的理解能力相对较弱,特别是对于一些需要深度语义理解的场景,如理解隐喻和反讽等语言现象时,表现可能不如BERT。
长距离依赖的局限性:虽然LSTM可以处理长短期依赖关系,但在实际应用中,对于非常长的文本序列中的长距离依赖,其效果可能会受到影响。随着文本长度的增加,信息在长距离传输过程中可能会出现丢失或衰减的情况。
4. 计算资源和效率
BERT:
训练效率相对较高:由于Transformer架构的并行计算特性,BERT在训练阶段相对高效。然而,BERT模型通常具有大量的参数,例如BERT base有110M参数,这导致它在预训练和微调过程中对计算资源(如GPU内存)的需求较高。
推理阶段考虑因素:在推理阶段,虽然Transformer架构可以并行计算,但对于长文本可能会因为模型的复杂性而导致推理时间较长。不过,通过一些优化技术,如模型量化和剪枝等,可以在一定程度上缓解这个问题。
ELMo:
训练效率较低:基于LSTM的架构在训练过程中是顺序计算的,相对较慢。尤其是在处理长序列文本时,由于LSTM的递归特性,计算时间会随着序列长度增加而增加。
资源需求特点:模型参数相对较少,对计算资源的要求没有BERT那么高,但在处理大规模数据和复杂任务时,效率可能不如BERT。
三、应用效果
BERT和ELMo在自然语言处理领域都取得了显著进展,但由于架构、预训练方式等方面的差异,它们在实际应用效果上存在一些不同。
BERT在许多自然语言处理任务中取得了优异的性能,特别是在需要理解句子之间关系和文本语义的任务中。例如,在问答系统中,BERT能够更准确地理解问题和文本内容之间的关系,找到更精准的答案;在文本分类任务中,能够更好地捕捉文本的情感倾向和主题类别。在命名实体识别任务中,可以准确地识别出文本中的人名、地名等实体信息。例如,在新闻报道中,能够高效地提取人物姓名和相关组织名称等。
ELMo在一些任务中也有不错的表现,尤其是在语法分析相关的任务中,由于LSTM对序列的处理能力,它能够很好地捕捉语法结构信息。例如,在词性标注任务中,ELMo可以利用句子的上下文来确定单词的词性。
应用场景主要包括词性标注、语法分析、语义角色标注等。例如,在语义角色标注任务中,ELMo可以帮助确定句子中每个单词所扮演的语义角色,如主语、宾语等。但在一些需要深度语义理解的任务中,如复杂的问答系统和情感分析,其性能可能相对较弱。
1. 文本分类
BERT:
优势:在多种文本分类任务上表现出色,尤其在需要理解长文本语义和复杂语义关系的场景中。例如新闻分类、情感分析等任务,BERT能凭借其双向编码器和大规模预训练学习到丰富的语义信息,准确捕捉文本中的情感倾向、主题类别等关键特征。如在电商产品评论的情感分析中,能精准判断评论是积极、消极还是中性,对包含复杂语义表达(如讽刺、委婉批评)的评论也能较好处理。
原因:BERT的Transformer架构并行计算能力强,可同时关注文本不同部分,多层Transformer块能深度挖掘文本语义;掩码语言模型和下一句预测的预训练任务使其对文本语义和句子间关系理解深刻。
ELMo:
表现:在文本分类任务中也能取得不错效果,但整体性能稍逊于BERT。在一些简单文本分类任务中,ELMo能利用上下文相关词向量提供有效特征,但面对复杂语义和长文本时,理解能力不如BERT。例如在分析包含隐喻、双关等修辞手法的文本时,ELMo可能难以准确把握语义。
原因:基于LSTM架构,顺序处理文本,对长文本处理效率低且长距离依赖捕捉能力有限;预训练仅基于语言模型预测任务,对语义理解深度不如BERT多样化的预训练任务。
### 2. 命名实体识别(NER)
BERT:
优势:在NER任务中表现优异,能高精度识别文本中的人名、地名、组织机构名等实体。即使在实体边界模糊、嵌套实体等复杂情况下,也能凭借强大的上下文理解能力准确判断。例如在处理医学文献中复杂的疾病名称、药物名称识别时,BERT能有效整合上下文信息,减少误判。
原因:Transformer架构的多头注意力机制可捕捉文本长距离依赖,更好识别实体间关系;预训练使BERT对各类文本有广泛语义理解,适应不同领域文本的NER任务。
ELMo:
表现:能完成NER任务,但在处理复杂实体和长文本时,效果不如BERT。例如在处理包含大量专业术语和复杂句式的科技文献时,ELMo可能会因对长距离依赖信息捕捉不足,导致实体识别错误或遗漏。
原因:LSTM顺序处理文本,在处理长文本时信息传递存在衰减,影响对复杂实体结构的理解;其预训练方式侧重于局部上下文和语言模型预测,对特定领域实体识别的针对性不如BERT。
3. 语义角色标注(SRL)
BERT:
优势:在SRL任务中,能准确标注句子中每个单词的语义角色,如施事者、受事者、工具等。通过对句子整体语义的深度理解,可处理复杂句式和语义关系。例如在分析包含多个从句、修饰成分复杂的句子时,BERT能清晰梳理语义结构,准确标注角色。
原因:强大的双向语义理解能力,可全面捕捉句子中单词间语义关系;多层Transformer块能从不同层次抽象语义特征,有助于确定语义角色。
ELMo:
表现:可以进行语义角色标注,但在处理复杂语义结构时,准确性不如BERT。例如在面对具有隐喻、省略等复杂语义现象的句子时,ELMo可能难以准确判断语义角色。
原因:尽管ELMo能利用双向LSTM捕捉一定上下文信息,但对深层次语义理解和复杂语义结构处理能力有限,难以像BERT那样全面把握句子语义。
4. 机器翻译
BERT:
优势:可作为编码器为机器翻译系统提供强大的语义理解能力,提升翻译质量。在处理长句、复杂句翻译时,能更好理解源语言语义,生成更符合目标语言表达习惯的译文。例如在英法、汉英等语言对的翻译中,BERT能有效处理不同语言间的语法差异和语义转换。
原因:Transformer架构适合处理长序列数据,多头注意力机制有助于捕捉源语言句子中长距离依赖关系,准确传递语义信息;大规模预训练使其对多种语言现象有广泛理解。
ELMo:
表现:在机器翻译中应用相对较少,主要作为词嵌入为模型提供语义信息。由于其顺序处理文本的特点,在处理长句翻译时效率较低,且对源语言语义理解深度可能不足,导致翻译质量提升有限。
原因:LSTM架构的顺序计算特性限制了处理长句效率,且在捕捉复杂语义关系和长距离依赖方面不如Transformer架构,难以满足机器翻译对语义理解和转换的高要求。
四、发展趋势
1.BERT的发展趋势
模型优化与轻量化:研究人员会持续探索模型轻量化的方法,如采用量化技术、剪枝技术等,在不降低性能的前提下,减小模型规模和计算复杂度,使其更易于部署和应用在资源受限的设备上,如移动设备和边缘计算设备等。
多模态融合:随着多模态数据处理技术的发展,BERT可能会与图像、音频等其他模态的信息进行融合,以实现更全面和深入的语义理解。例如,在图文理解、视频内容理解等任务中,结合图像和文本的信息进行联合学习和推理,从而更好地理解和生成内容。
预训练任务的改进与创新:不断优化和创新预训练任务,以更好地捕捉语言的语义、句法和语用信息。除了现有的掩码语言模型和下一句预测任务外,可能会引入更多样化的预训练任务,如语义角色标注、文本蕴含推理等,进一步提升模型的语言理解能力。
领域自适应与微调优化:针对不同的应用领域和特定任务,进行更精细的领域自适应和微调优化。通过在特定领域的大规模数据集上进行微调,使BERT能够更好地适应专业领域的术语、语义和上下文,提高在特定领域任务中的性能,如医学、法律、金融等领域。
与强化学习结合:与强化学习技术相结合,使模型能够在与环境的交互中不断学习和优化。例如,在对话系统、智能体等应用中,通过强化学习来训练BERT模型,使其能够根据环境反馈做出更合适的决策和生成更准确的回复。
2.ELMo的发展趋势
与先进架构融合或改进:由于其基于LSTM的架构在处理长序列和并行计算方面存在一定局限性,可能会借鉴Transformer的优势对自身架构进行改进或与Transformer结合,以提升模型的性能和效率,更好地适应大规模文本处理和复杂语义理解的需求。
在特定领域的深度应用:在一些对上下文理解要求较高的特定领域,如文学创作、历史研究、法律文书分析等,ELMo可以进一步深入应用。通过在这些领域的大规模专业文本上进行预训练和微调,为特定领域的文本处理提供更精准的语义表示和分析能力。
作为辅助工具与其他模型结合:ELMo可以作为一种有效的辅助工具与其他先进的NLP模型结合使用。例如,将ELMo生成的上下文相关词向量作为额外的特征输入到其他模型中,以增强模型对语义的理解和表示能力,或者与新兴的预训练模型进行融合,发挥各自的优势。
语义理解的深化与拓展:不断深化对语义的理解和表示能力,不仅仅局限于当前的上下文信息,还可能考虑更广泛的语义背景和语用信息。通过引入更多的语义知识和语言规则,进一步提升ELMo对复杂语义现象的处理能力,如隐喻、双关语、语义歧义等。