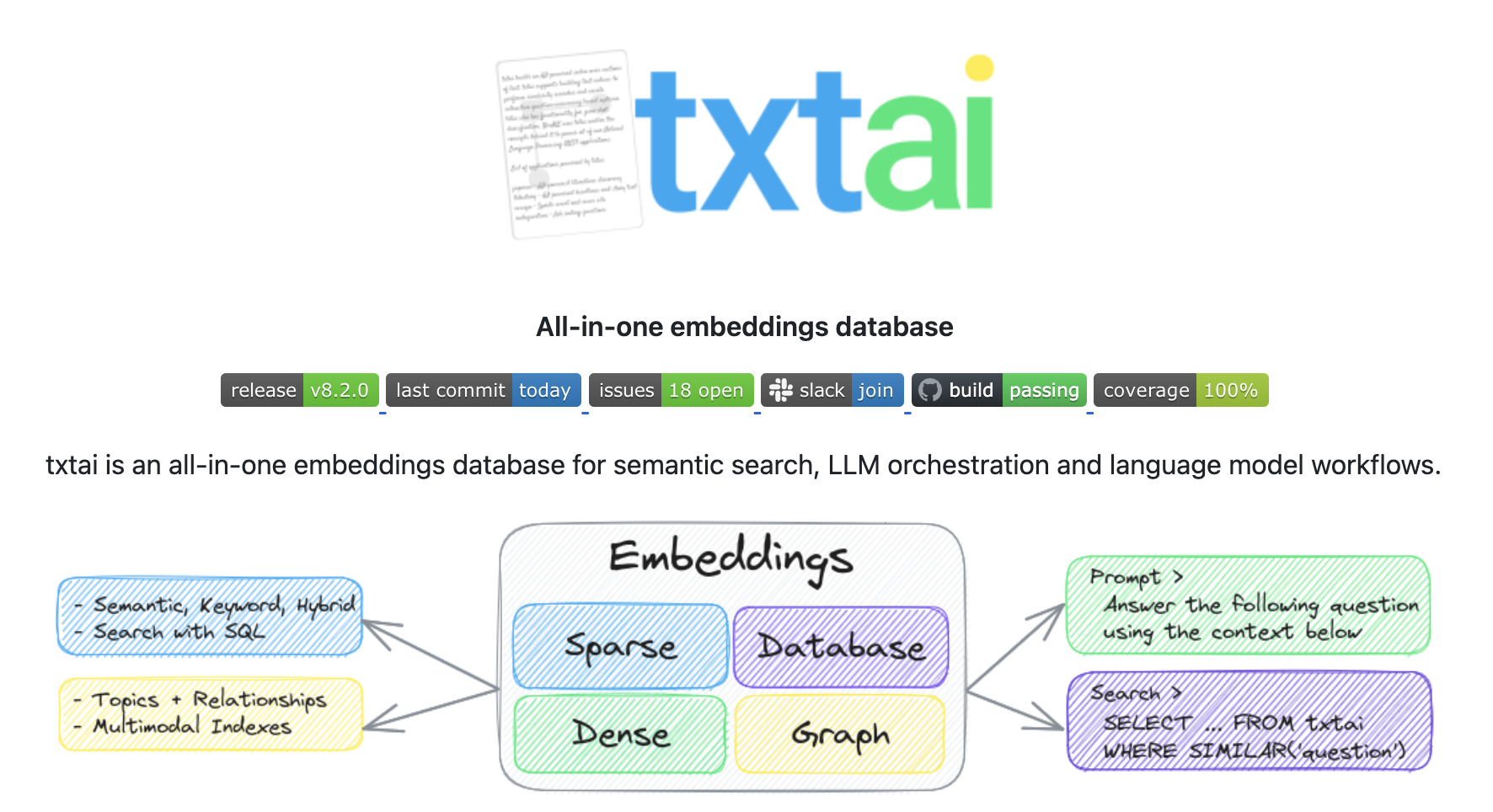
txtai是一个功能丰富的人工智能数据处理平台,提供了一整套工具,用于构建语义搜索、语言模型工作流和文档处理流水线。其核心功能包括用于高效相似性搜索的嵌入式数据库,方便集成语言模型和其他人工智能服务的API,支持自定义工作流的可扩展架构,以及多语言和多数据格式支持。它为开发人员提供了一套强大的工具,可以高效地构建与文本相关的应用程序,如语义搜索、文本分类和知识图谱构建等。其设计理念是简单易用,同时又能提供高性能的文本处理功能。适合需要在单一框架内实现多种人工智能功能的组织,特别是那些需要处理多种数据类型和语言的场景。
项目地址:https://github.com/neuml/txtai
一、功能特点
1.语义搜索
txtai采用先进的深度学习模型来理解文本的语义。例如,在一个文档库中,它可以根据用户查询的意图,而不仅仅是关键词匹配,来返回最相关的文档。这就好比在一个知识丰富的图书馆中,它不是简单地根据书名中的词汇来查找书籍,而是真正理解读者想要的知识主题,然后找到最合适的内容。它通过对文本进行向量化表示,计算查询向量和文档向量之间的相似度,实现精准的语义搜索。
2.文本分类
对于大量的文本数据,txtai可以进行自动分类。它可以根据预先定义的类别标签,将新闻文章分类到不同的主题类别,如政治、经济、体育等。这一功能是基于机器学习算法,通过对大量已标注的文本数据进行训练,学习到不同类别文本的特征模式,从而对新的文本进行准确分类。例如,当有一篇新的财经新闻时,它能够准确地将其归类到经济类别中。
3.知识图谱构建
它能够从文本数据中提取实体和关系,用于构建知识图谱。比如,在医学文献中,它可以提取疾病、症状、治疗方法等实体,以及它们之间的关联关系,如“某种疾病可能出现某种症状”“某种治疗方法对某种疾病有效”等。这些知识图谱可以用于智能问答系统、知识推理等应用场景,为用户提供更深入的知识服务。
二、技术架构
1.深度学习模型
txtai利用了多种深度学习模型,如Transformer架构相关的模型。Transformer架构以其在自然语言处理中的卓越性能而闻名,它能够很好地处理长序列文本数据,学习文本中的语义和语法信息。通过预训练和微调等方式,txtai中的模型可以适应不同的文本处理任务。
2.数据存储与索引
在数据存储方面,txtai采用了高效的数据结构来存储文本数据和相关的索引信息。它可以处理大规模的文本数据集,并且通过优化的索引机制,能够快速地检索到相关的数据。例如,在处理一个包含数百万篇文档的知识库时,它的索引系统能够确保快速的查询响应,就像在一个大型图书馆中通过一套高效的图书索引系统快速找到所需书籍一样。
三、算法应用
1. Transformer架构相关算法
BERT(Bidirectional Encoder Representations from Transformers)及其变体
预训练任务应用:BERT在预训练阶段采用了两个关键任务,即掩码语言模型(Masked Language Model,MLM)和下一句预测(Next Sentence Prediction,NSP)。在txtai中利用这两个任务训练得到的模型能够更好地理解文本语义。例如,在掩码语言模型任务中,模型会随机掩盖输入文本中的一些单词,然后通过预测这些被掩盖单词来学习语言的结构和语义。对于句子“我[掩码]在公园里散步”,模型会根据上下文“我”和“在公园里散步”来推测掩码处可能是“正在”等词汇。下一句预测任务则有助于理解句子之间的连贯性,比如判断两个句子“我早上吃了早餐”和“然后我去上班了”是连贯的。
微调用于下游任务:经过预训练的BERT模型可以通过微调用于txtai中的各种下游任务,如文本分类、语义搜索和问答系统等。以文本分类为例,将文本输入BERT模型,模型会输出一个文本表示向量,这个向量可以通过添加一个简单的分类器(如全连接层)来判断文本所属的类别。比如,在新闻分类任务中,将新闻文本输入微调后的BERT模型,就可以判断新闻是属于体育、娱乐还是其他类别。
Transformer XL(Extra Long)
处理长序列文本优势:Transformer XL是Transformer架构的扩展,它在处理长序列文本方面有显著优势。在txtai应用场景中,如处理长篇小说、学术论文等长文本时非常有用。它通过递归机制能够记住长序列文本中的信息,克服了普通Transformer架构在处理长文本时可能出现的信息遗忘问题。例如,在分析一部长篇历史小说时,Transformer XL可以更好地理解小说中人物关系、情节发展等贯穿全文的线索,而不会因为文本过长丢失之前章节的信息。
2. 词向量算法
Word2Vec(Skip Gram和CBOW)
语义相似性学习:Word2Vec是一种用于生成词向量的经典算法,其中Skip Gram和CBOW是两种主要的训练模式。在txtai中,这些算法可以帮助学习单词之间的语义相似性。例如,Skip Gram模式以目标单词为中心,预测其上下文单词。通过大量文本的训练,它会发现“国王”和“王后”等语义相关的单词在向量空间中距离很近。这种语义相似性信息对于文本的预处理和一些简单的文本理解任务很有帮助,比如在文本分类中,相似语义的单词可以作为一个特征组来考虑。
词向量在文本处理中的基础作用:生成的词向量可以作为其他深度学习模型的输入,为整个文本处理系统提供基础的语义表示。在txtai的文本搜索应用中,词向量可以用于计算文本之间的初始相似度,为后续更精细的语义搜索(如基于Transformer架构的语义搜索)提供参考。例如,在一个文档库中,首先可以通过词向量快速筛选出一些可能与查询相关的文档,然后再通过更复杂的模型进行深度语义匹配。
3. 聚类算法
K Means聚类或层次聚类
文本分类与主题发现:在txtai中,聚类算法可用于文本分类和主题发现。以K Means聚类为例,它将文本数据划分为K个簇。在没有预先定义文本类别的情况下,通过对文本向量(可以是通过Transformer模型或Word2Vec得到的向量)进行聚类,发现文本中的自然分组。例如,在一个包含大量新闻文章的数据集里,K Means聚类可以将文章根据主题(如政治、经济、娱乐等)自动分成不同的簇。层次聚类则可以构建文本主题的层次结构,从更宽泛的主题逐渐细分到具体的子主题,这对于知识图谱构建等任务很有帮助。
数据预处理与探索性分析:聚类算法还可用于数据预处理和探索性分析。在处理大规模文本数据时,通过聚类可以初步了解文本数据的分布情况,比如是否存在明显的主题集中区域或者数据是否分散。这有助于确定后续文本处理的策略,如是否需要对某些主题区域的数据进行更详细的分析或者对分散的数据进行重新采样等。
4. 相似度计算算法
余弦相似度(Cosine Similarity)
语义搜索中的应用:在txtai的语义搜索功能中,余弦相似度是一种常用的计算文本之间相似度的算法。它通过计算两个文本向量之间的夹角余弦值来衡量相似度。在向量空间中,两篇语义相近的文本其向量夹角较小,余弦相似度值接近1。例如,在一个知识库中,用户查询一个关于人工智能在医疗影像诊断中的应用的问题,txtai会将查询向量与知识库中的文档向量进行余弦相似度计算,将相似度高的文档返回给用户,从而实现精准的语义搜索。
文本匹配与推荐中的作用:除了语义搜索,余弦相似度还用于文本匹配和推荐系统。在文本匹配方面,它可以判断两个文本片段是否在语义上匹配,如在问答系统中判断用户问题和知识库答案是否匹配。在推荐系统中,它可以根据用户已阅读的文本和待推荐文本之间的相似度来进行推荐,比如为阅读了科技类文章的用户推荐其他科技相关文章。
四、应用场景
1. 文档搜索与知识管理
企业内部知识共享:在大型企业中,存在海量的文档,包括公司政策、项目文档、技术手册等。txtai可以对这些文档进行语义理解和索引,使员工能够通过自然语言查询快速找到所需信息。例如,员工可以输入“我们去年在X项目中采用的新技术细节”,txtai就能在众多文档中精准定位相关内容,提高企业内部知识共享的效率。
学术研究资源搜索:对于学术机构和科研人员,txtai可以用于学术文献的搜索。它可以跨越不同的数据库,理解学术论文的内容主题。比如,研究人员查找“关于基因编辑技术在作物改良方面的最新研究综述”,txtai可以分析论文的语义,而不仅仅是标题和关键词,为研究人员提供更符合需求的文献,促进学术交流和研究进展。
2. 内容推荐与个性化服务
新闻媒体推荐:新闻媒体平台可以利用txtai对新闻文章进行分类和分析。根据用户的阅读历史、浏览习惯和兴趣偏好,为用户推荐他们可能感兴趣的新闻。例如,如果用户经常阅读科技类新闻,txtai可以识别新闻文章中的科技相关主题,如人工智能、新能源等,然后将最新的科技新闻推荐给用户,提高用户的阅读体验和平台的粘性。
图书与文献推荐:在图书馆或在线图书平台,txtai可以根据书籍内容进行推荐。它可以分析书籍的主题、风格和受众群体,为读者推荐适合他们阅读口味的书籍。比如,对于喜欢科幻小说的读者,txtai可以通过分析书籍中的科幻元素,如星际旅行、外星生物等,推荐其他具有相似元素的科幻图书。
3. 文本分类与审核
社交媒体内容分类:社交媒体平台每天产生大量的内容,包括帖子、评论等。txtai可以对这些内容进行分类,例如分为生活分享、产品推荐、新闻资讯等类别。同时,它还可以用于审核内容,识别有害信息,如暴力、色情、虚假信息等。例如,当用户发布含有违法信息的内容时,txtai可以快速识别并标记,帮助平台维护健康的社交环境。
新闻媒体内容审核:新闻媒体机构需要确保发布内容的准确性和合法性。txtai可以帮助审核新闻稿件,对新闻的类别、真实性进行初步判断。比如,对于一篇声称是医疗突破的新闻,txtai可以通过与已知的医学知识和权威信息进行对比,辅助编辑判断新闻的可靠性,从而提高新闻质量。
4. 智能问答与客服系统
电商客服支持:在电子商务领域,txtai可以用于构建智能客服系统。它可以理解顾客提出的问题,如产品功能、价格、售后服务等,并从知识库中提取准确的答案。例如,顾客询问“这款手机的防水等级是多少”,txtai可以快速在产品知识库中查找相关信息并回答顾客,减少人工客服的工作量,提高客服响应速度。
企业内部问答系统:企业内部经常会有员工对各种业务流程、技术问题等进行提问。txtai可以构建企业内部问答系统,汇总常见问题和答案,当员工提问时,能够快速提供解决方案。比如,员工询问“如何申请办公用品”,txtai可以从企业内部流程文档中找到答案并告知员工,方便员工的日常工作。
5. 文本生成辅助
内容创作灵感激发:对于文案创作者,txtai可以作为灵感激发工具。它可以根据给定的主题或关键词,生成相关的内容片段或创意。例如,对于一个旅游文案创作者,当给定“巴黎旅游攻略”这个主题时,txtai可以生成一些关于巴黎著名景点、美食、住宿等方面的内容片段,帮助创作者开拓思路。
自动摘要生成:在新闻报道和学术研究等领域,txtai可以用于生成文本摘要。它可以提取文本的关键内容,生成简洁明了的摘要。例如,对于一篇长篇的学术论文,txtai可以生成一个包含研究目的、方法、主要结论的摘要,方便读者快速了解论文的核心内容。