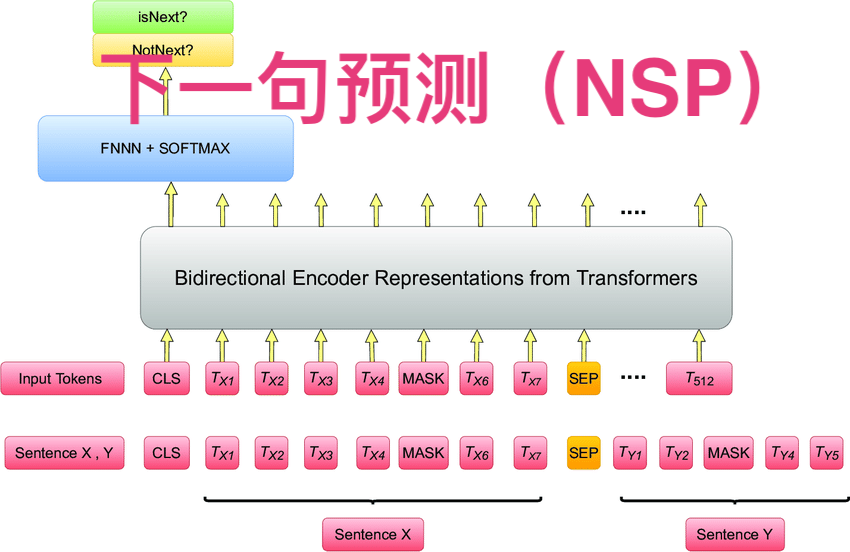
下一句预测(Next Sentence Prediction,NSP)是自然语言处理(NLP)中的一个任务。它主要是判断给定的两个句子在原文中是否是相邻的句子。例如,对于句子A和句子B,模型需要预测句子B是否是句子A在文本中的下一句。
早期NLP任务主要关注单词层面的预测和理解,如传统的词袋模型、ngram模型等,随着对语言理解的深入,研究人员开始意识到句子之间的关系对于理解文本整体含义的重要性。
2017年,Transformer架构的提出为NSP任务的发展提供了强大的基础,其自注意力机制能够更好地捕捉句子中的长距离依赖关系,使得模型能够更有效地处理句子对之间的语义关系。
2018年,谷歌推出的BERT模型中正式提出了NSP任务作为预训练任务之一。在BERT的预训练过程中,NSP任务与遮蔽语言模型(MLM)任务相结合,通过大量的无监督文本数据进行训练,使得模型能够学习到句子之间的连贯性和语义关系。
BERT在多项自然语言处理任务上取得了突破性的成绩,如问答系统、情感分析、文本分类等,NSP任务在其中发挥了重要作用,它帮助模型更好地理解文本的整体结构和上下文信息,从而提高了模型在下游任务中的性能。
2024年,香港理工大学的研究人员通过使用NSP任务对语言理解进行建模,研究话语级理解的机制,发现NSP预训练增强了模型与大脑数据的一致性,尤其是在右半球和多需求网络中,突出了非经典语言区域对高级语言理解的贡献,为解决语言神经科学中的问题提供了新视角。
一、在预训练语言模型中的应用
在像BERT(Bidirectional Encoder Representations from Transformers)这样的预训练语言模型中,NSP是其中一个重要的训练任务。在预训练阶段,模型会同时学习两个目标,一个是遮蔽语言模型(Masked Language Model,MLM)任务,另一个就是NSP任务。
通过NSP任务,模型可以学习到句子之间的语义和逻辑关系。比如在新闻文本中,“美国总统发表了演讲”和“演讲内容主要涉及经济改革”这两个句子在逻辑上是相邻的,NSP任务能够帮助模型捕捉到这种关联。
二、NSP的作用和优势
帮助理解文本结构:使模型能够更好地理解文本的叙事结构、逻辑顺序等。比如在故事生成、文本摘要等任务中,对句子顺序的正确把握非常重要,NSP任务训练后的模型可以更好地完成这些任务。
增强语义理解:除了理解单个句子的语义,还能理解句子之间的语义衔接。例如在机器翻译任务中,NSP有助于生成更符合目标语言表达习惯的句子顺序,从而提高翻译质量。
三、训练过程
假设我们有一个文本语料库,在训练NSP时,会从语料库中选取句子对。这些句子对分为两种情况:一种是正例,即第二个句子确实是第一个句子在原文中的下一句;另一种是负例,两个句子是随机选取的,在原文中不是相邻的。
例如,正例句子对可以是“太阳升起,照亮了大地”。模型会学习到这两个句子之间的连贯性。负例句子对可能是“鱼儿在水中游,飞机在天空翱翔”,这两个句子在正常文本中不太可能是相邻的,模型通过对比正例和负例来学习如何区分句子之间的关系。
1. 数据准备阶段
构建句子对数据集:
首先需要从大规模的文本语料库中收集句子。这些文本可以包括新闻文章、小说、学术论文等各种类型的文本。然后将这些句子组合成句子对。句子对分为正例和负例,正例是文本中相邻的句子,能够体现自然的语义连贯和逻辑顺序;负例则是随机组合的句子,它们在原始文本中通常不是相邻的。
例如,对于一篇新闻报道“今天上午,市政府召开了紧急会议。会议讨论了城市交通拥堵的解决方案。”这两个句子可以构成一个正例句子对。而从不同文章中抽取的句子,如“花园里的花朵盛开了。科学家在实验室里取得了新突破。”可以构成一个负例句子对。
标记句子对类别:
对构建好的句子对进行标记,正例标记为“1”,表示下一句是正确的;负例标记为“0”,表示下一句不是正确的后续句子。这种标记为后续的模型训练提供了监督信号,使模型能够学习区分正确和错误的句子序列。
2. 模型选择与初始化
选择合适的模型架构:
可以使用Transformer架构(如BERT等)或其他深度学习模型(如LSTM等)来进行下一句预测。Transformer架构由于其自注意力机制,在处理句子间关系方面表现出色。以BERT为例,它在预训练阶段就包含了下一句预测任务。
模型在初始化时会设置各种参数,例如权重矩阵通常会随机初始化。这些参数会在后续的训练过程中根据数据进行调整。
3. 前向传播阶段
句子对编码:
将句子对中的两个句子分别输入到模型中进行编码。在Transformer架构中,通过词嵌入将句子中的单词转换为向量表示,然后利用多头自注意力机制和前馈神经网络对句子进行特征提取。例如,对于输入的句子对(句子A,句子B),句子A和句子B会分别被转换为向量序列,然后经过多层的自注意力和前馈网络处理,得到句子A和句子B的编码表示。
这些编码表示会捕获句子的语义和语法等信息,并且能够考虑句子之间的相互关系,为后续的下一句预测提供基础。
预测下一句概率:
基于句子对的编码表示,模型会通过一个分类层来预测句子B是句子A下一句的概率。这个分类层通常是一个全连接层,它将句子对的编码输出映射到一个概率值。例如,使用Sigmoid函数将输出映射到0到1之间的概率,接近1表示模型认为句子B是句子A的下一句的可能性很高,接近0则表示可能性很低。
4. 损失计算与反向传播阶段
计算损失函数:
常用的损失函数是二元交叉熵损失(Binary Cross Entropy Loss)。通过比较模型预测的下一句概率和实际标记的类别(正例为1,负例为0)来计算损失。如果模型预测的概率与实际类别相差较大,损失值就会较大,反之损失值较小。
例如,如果一个正例句子对被模型预测为下一句的概率很低(接近0),那么根据二元交叉熵损失函数计算出来的损失就会很大,这表明模型在这个句子对上出现了较大的错误。
反向传播更新参数:
根据计算得到的损失,使用反向传播算法来更新模型的参数。反向传播会从损失函数开始,沿着模型的计算图反向传播梯度,将梯度乘以一个学习率后,更新模型中的权重和偏置等参数。
通过多次迭代这个过程,模型会不断调整参数,使得损失函数逐渐减小,从而提高下一句预测的准确性。在每一次迭代中,模型都会处理大量的句子对,经过多个轮次(Epoch)的训练,模型能够学习到句子之间的逻辑关系和语义连贯,从而更好地完成下一句预测任务。
四、局限性
在一些复杂的文本场景中,如文学作品中的意识流写作,句子之间的逻辑关系比较模糊,NSP可能会出现误判。例如,在一些诗歌或者具有跳跃性思维的散文中,句子之间的连接可能不遵循常规的逻辑顺序,NSP任务对于这样的文本可能难以准确预测句子的先后关系。
1. 语义理解的局限性
语义模糊性处理困难:在面对语义模糊的句子时,NSP可能会失效。例如在文学作品、诗歌或隐喻性较强的文本中,句子之间的逻辑关系不遵循常规模式。像“黑夜给了我黑色的眼睛,我却用它寻找光明”,这样富有隐喻的句子,其前后句的语义关联不是基于常见的事实逻辑,NSP很难准确把握这种特殊的语义衔接关系。
文化背景和语境依赖挑战:NSP高度依赖语义理解,但对于涉及不同文化背景和复杂语境的句子,可能会出现误判。例如,某些文化特有的习语或谚语,如英文中的“raining cats and dogs”(倾盆大雨),如果模型没有对这种文化背景知识进行学习,就很难准确预测包含这类表达的句子的下一句。
2. 句子结构和语法的局限性
复杂句子结构误判:当遇到复杂的句子结构,如多重嵌套的从句、省略句、倒装句等,NSP可能会出现错误判断。以一个复杂的嵌套从句为例,“The book that I bought, which was recommended by my teacher, who is an expert in literature, is very interesting.”,理解这样句子之间的关联以及预测下一句对于NSP来说是具有挑战性的。
语法变体和不规则语法处理不力:对于一些语法变体(如方言中的特殊语法)和不规则语法现象,NSP可能无法很好地适应。例如,在一些英语口语方言中,会出现“ain't”这样不符合标准语法的词汇,NSP可能会因为缺乏对这类语法现象的足够了解而无法准确预测包含它们的句子的下一句。
3. 长距离和跨段落关系处理的局限性
长距离句子关系捕捉不足:NSP主要关注相邻句子之间的关系,对于长距离句子关系的捕捉能力较弱。在长篇小说、学术论文等长文本中,开头和结尾段落的句子之间可能存在重要的呼应关系,但NSP很难跨越大量中间句子去有效捕捉这种长距离关系。
跨段落连贯性理解困难:在处理跨段落的句子时,NSP面临挑战。由于段落之间可能会有主题的转换或者逻辑的跳跃,NSP可能会因为缺乏对段落整体结构和转换逻辑的理解,而无法准确预测下一句,特别是当段落之间的衔接比较隐晦时。
4. 数据和模型依赖的局限性
数据偏差影响:NSP的性能很大程度上依赖于训练数据。如果训练数据存在偏差,例如某一领域的文本过多而其他领域的文本过少,那么模型在面对数据稀缺领域的句子预测时就会表现不佳。例如,若训练数据主要是科技文献,当遇到文艺作品中的句子预测时,就可能因为缺乏相关数据而出现错误。
模型结构限制:不同的NSP模型有其自身的结构限制。例如,一些简单的基于规则的NSP模型无法像深度学习模型那样有效地处理复杂的语义和句子关系。而即使是深度学习模型,如Transformer架构的某些局限性(如计算资源消耗大、可能存在过拟合等)也会影响NSP的准确性和效率。
五、应用领域
1. 自然语言处理基础任务
文本分类:在新闻分类中,NSP可以帮助理解新闻内容的连贯性。例如,对于一篇科技新闻,通过判断句子之间的逻辑关系来更好地确定新闻主题是关于新技术研发、产品发布还是行业动态等。在情感分类任务中,NSP能够协助分析句子之间情感的衔接,比如判断一段影评中,前后句子是如何连贯地表达正面或负面情感的。
命名实体识别(NER):当识别文本中的人名、地名、组织机构名等实体时,NSP有助于理解句子之间关于这些实体的指代关系。例如,在一个文档中,前一个句子提到“苹果公司”,后一个句子用“它”指代,NSP可以帮助模型更好地确定“它”的指代对象,从而更准确地进行命名实体识别。
词性标注(POS):NSP可以辅助理解句子之间的语法和语义关系,进而更准确地标注单词的词性。例如,在相邻句子中,一个动词的时态可能会根据上下文发生变化,NSP任务可以帮助模型更好地把握这种变化,从而正确标注词性。
2. 信息检索与问答系统
搜索引擎优化:搜索引擎在理解用户查询和网页内容时,可以利用NSP来更好地匹配相关信息。例如,当用户搜索“如何制作蛋糕”,搜索引擎可以通过NSP判断网页内容中句子之间的关系,找出包含连贯制作步骤的网页,提高搜索结果的质量。
问答系统构建:在问答系统中,NSP可以帮助理解问题和答案之间的关联,以及答案句子之间的连贯性。例如,对于一个历史问题“唐朝的建立时间和主要事件”,问答系统可以通过NSP来筛选出答案中关于唐朝建立时间的句子和相关主要事件的句子,并将它们以合理的顺序呈现给用户。
3. 文本生成
在故事生成、摘要生成等任务中,NSP是关键。以故事生成为例,模型需要根据前面的句子来合理地预测下一个句子,从而构建出连贯的故事情节。在摘要生成时,NSP帮助确定原始文本中哪些句子是连贯且重要的,以便生成高质量的摘要。
4.机器翻译:在翻译过程中,NSP可以帮助确定目标语言句子的最佳顺序。不同语言的句子顺序可能不同,通过理解源语言句子之间的关系,模型可以更好地在目标语言中生成符合逻辑和表达习惯的句子顺序,提高翻译的准确性和流畅性。
例如,在英语中,定语从句通常跟在被修饰的名词之后,而在日语中,定语从句往往位于被修饰名词之前。下一句预测(NSP)可以帮助机器翻译系统理解源语言句子之间的逻辑顺序,从而在翻译到目标语言时,对句子顺序进行合理的调整。
以翻译“我看到了一个昨天刚开业的商店。”(英语句子为“I saw a store that just opened yesterday.”)为例,在从中文翻译到英语时,NSP可以帮助系统识别出“昨天刚开业的”是用来修饰“商店”的,并且按照英语的表达习惯将定语从句后置。
NSP有助于确保翻译后的句子在语义上是连贯的。在翻译长文本时,机器需要考虑句子之间的衔接关系。例如,在翻译科技文献时,原文可能包含一系列有因果、递进等逻辑关系的句子。
比如原文是“这种新材料具有高强度的特性。因此,它在航空航天领域得到了广泛应用。”在翻译时,NSP可以帮助机器翻译系统理解这种因果关系,从而在目标语言中也能生成语义连贯的句子,如“The new material has high strength characteristics. Therefore, it is widely used in the aerospace field.”
处理文本中的代词指代关系是机器翻译的一个难点。NSP可以帮助翻译系统理解句子之间关于代词的指代内容,从而在翻译时选择正确的代词或者明确指代对象。例如,在“小明喜欢读书。他每天都会花一个小时阅读。”中,NSP可以帮助系统理解“他”指代“小明”,在翻译到英语“He Xiaoming likes reading books. He spends an hour reading every day.”时,能够正确处理代词,避免指代不明的情况。
NSP可以作为一种评估翻译质量的工具。通过比较源语言句子之间的逻辑关系和翻译后句子之间的逻辑关系,可以判断翻译是否准确地传达了原文的意思。
例如,如果源语言句子是按照时间顺序排列的,如“首先,他打开了电脑。然后,他开始工作。”,翻译后的句子也应该保持这种时间顺序,如果翻译后的句子顺序混乱或者语义不连贯,就可以通过NSP相关技术来发现这种翻译质量问题。
5. 对话系统与智能客服
对话系统:在聊天机器人等对话系统中,NSP用于理解对话轮次之间的关系。例如,当用户提出一个问题,聊天机器人需要根据之前的对话内容和当前问题来预测下一个合适的回答句子,使对话能够自然、连贯地进行。
智能客服:智能客服系统可以利用NSP来理解客户咨询和回复内容之间的连贯性。例如,当客户询问产品的功能,客服系统需要根据NSP来生成连贯的回答句子,包括产品功能的介绍、可能的解决方案等,以提供更好的服务体验。