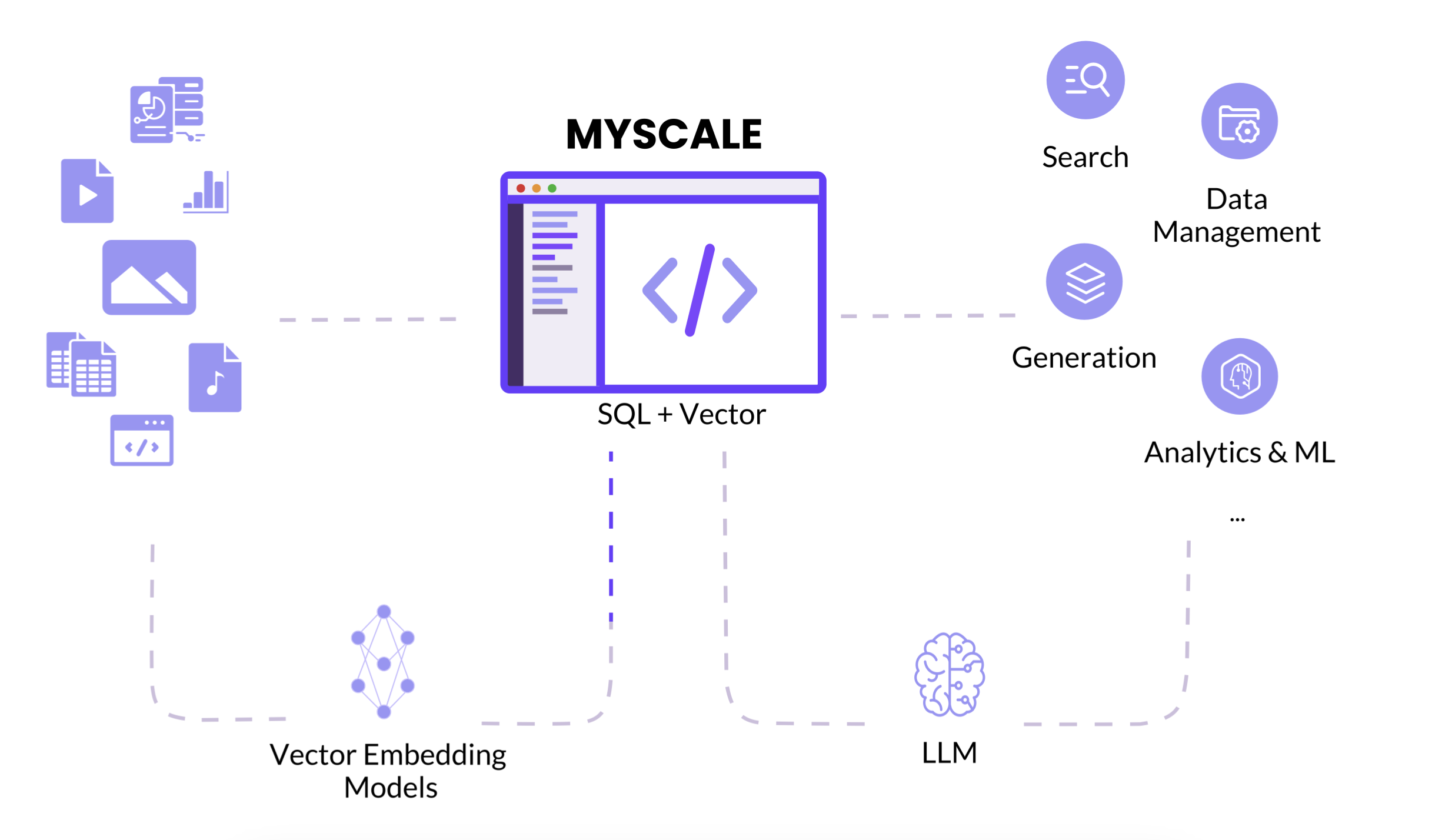
墨奇科技团队在数据库技术选型时,意识到传统专有向量数据库如Pinecone、Zilliz、Chroma等虽向量检索性能优秀,但处理通用数据能力不足;而传统数据库加外挂模块如pgvector等,通用性有一定提升,但向量性能欠佳。团队敏锐洞察到市场痛点,最终选择以高性能的列存分析数据库ClickHouse作为基础进行改造。同时对向量化的算法、系统以及 SQL 与向量的联合查询和存储进行了深入优化。
自主研发多尺度树图(MSTG)向量索引算法,允许将向量数据缓存在本地 NVMe SSD 盘中,区别于大部分选择纯内存 HNSW 向量索引算法的向量数据库。
经过近 6 年的开发和数次版本迭代,MyScale 集成了关键词倒排表功能,进一步增强其自然语言查询能力。
MyScale 支持完整的 SQL 语法,实现了向量与结构化数据查询的深度融合,还支持任意过滤比例的查询功能,可根据结构化、字符串等属性对海量向量数据进行过滤和筛选。
项目地址:https://github.com/myscale/myscaledb
一、产品特点
1.基于ClickHouse开发:MyScale以开源的在线分析处理(OLAP)数据库ClickHouse为基础,继承了ClickHouse强大的结构化数据分析和查询能力,可高效处理大规模结构化数据。
2.自研MSTG向量索引算法:集成自主研发的多尺度树图(MSTG)向量索引算法,相比大部分选择纯内存HNSW向量索引算法的向量数据库,允许将向量数据缓存在本地NVMe SSD盘中,在提供高性能向量搜索的同时,大大节约了内存使用。
3.支持SQL语法:支持完整的SQL语法,用户可以使用熟悉的SQL语句进行向量数据的管理和查询,实现了向量与结构化数据查询的深度融合,为用户带来极大的灵活性和便利性。
4.高数据密度与索引速度:高数据密度设计使相同存储容量下能存储更多数据,降低企业硬件和运维成本。构建索引速度大幅提升,如上传1000万向量,MyScale仅需三十四分钟,而pgvector可能需要几个小时甚至十几个小时。
5.支持复杂过滤查询:支持任意过滤比例的查询功能,可根据结构化、字符串等属性对海量向量数据进行过滤和筛选,再进行近似向量查询,实现高速高精度的混合信息检索。
6.集成关键词倒排表功能:引入关键词倒排表功能,增强了其自然语言查询能力,能更好地支撑复杂的大模型RAG应用和多样化查询需求。
7.与LangChain集成:与LangChain完全集成,可轻松为自查询检索器创建向量存储,有助于提升大语言模型(LLM)应用的性能和扩展范围。
二、技术架构
MyScale 构建在 ClickHouse 之上,对其进行了拓展和优化,形成了一个能高效处理向量数据与传统结构化数据的综合性数据库架构。
1.存储层
列式存储与数据压缩:继承 ClickHouse 的列式存储特性,数据按列存储而非按行,这种方式有利于在进行数据分析和查询时,仅读取所需的列,减少 I/O 开销,提高查询性能。同时,支持高级的数据压缩算法,能够显著减少数据的存储空间,降低存储成本,加快数据的读写速度。
向量数据存储优化:针对向量数据的特点,采用了特殊的存储方式。MyScale 自研的多尺度树图(MSTG)向量索引算法允许将向量数据缓存在本地 NVMe SSD 盘中,打破了传统向量数据库大多依赖纯内存存储的局限,在保证向量搜索性能的同时,大大节约了内存使用。
结构化与向量数据融合存储:能够将结构化数据(如文本、数值、日期等)和向量数据进行融合存储。这使得在实际应用中,可以方便地将数据的语义信息(通过向量表示)与传统的业务属性信息(结构化数据)关联起来,为复杂的数据分析和查询提供支持。
2.索引层
MSTG 向量索引:多尺度树图(MSTG)向量索引是 MyScale 的核心索引技术之一。它通过构建高效的索引结构,能够在大规模向量数据集中快速定位与查询向量最相似的向量。MSTG 索引不仅在搜索速度上表现出色,而且在处理高维向量时也具有较好的性能,能够适应不同场景下的向量搜索需求。
跳跃索引与辅助索引:借鉴 ClickHouse 的跳跃索引机制,对于结构化数据,可以快速跳过不相关的数据块,减少不必要的数据扫描。此外,还支持其他辅助索引,如哈希索引、B 树索引等,进一步提高数据的查询效率,特别是在处理复杂的查询条件时。
3.查询处理层
SQL 支持与查询优化:MyScale 支持完整的 SQL 语法,用户可以使用熟悉的 SQL 语句进行向量数据和结构化数据的查询、插入、更新和删除操作。数据库内部具有强大的查询优化器,能够对 SQL 查询进行解析、优化和执行计划生成,确保查询以最高效的方式执行。
向量与结构化数据联合查询:这是 MyScale 的一个重要特性,它允许在同一个查询中同时处理向量数据和结构化数据。例如,可以先根据结构化数据的条件进行过滤,然后在过滤后的结果中进行向量相似性搜索,或者反之。这种联合查询的能力使得数据库在实际应用中更加灵活,能够满足复杂的业务需求。
分布式查询处理:MyScale 具备分布式查询处理能力,能够将查询任务分发到多个节点上并行执行,然后将结果进行合并。这种分布式架构使得数据库能够处理大规模的数据和高并发的查询请求,提高系统的整体性能和可扩展性。
4.接口层
标准 SQL 接口:提供标准的 SQL 接口,方便用户使用各种支持 SQL 的工具和编程语言与数据库进行交互。无论是专业的数据库管理工具,还是 Python、Java 等编程语言,都可以通过 SQL 接口轻松地连接到 MyScale 数据库,进行数据的操作和管理。
RESTful API 接口:除了 SQL 接口,MyScale 还提供 RESTful API 接口,使得开发者可以通过 HTTP 请求的方式与数据库进行通信。RESTful API 接口具有良好的跨平台性和易用性,方便与其他系统进行集成,例如与前端应用、机器学习模型等进行对接。
5.管理与监控层
集群管理:支持集群的创建、配置、扩展和收缩等管理操作。用户可以根据业务需求灵活调整集群的规模,以适应不同的数据量和查询负载。集群管理功能还包括节点的添加、删除、故障恢复等,确保数据库系统的高可用性和稳定性。
性能监控与调优:提供丰富的性能监控指标,如查询响应时间、吞吐量、资源利用率等。通过对这些指标的实时监控,管理员可以及时发现系统的性能瓶颈,并进行相应的调优操作,如调整索引策略、优化查询语句、增加硬件资源等,以保证数据库系统始终保持良好的性能。
三、优势
MyScale的技术架构相比其他向量数据库,在存储能力、索引性能、查询功能、接口兼容性等方面具有诸多优势。
1.存储架构优势
存储成本与容量优势:许多向量数据库依赖纯内存存储向量数据,内存成本高且容量有限。MyScale自研的MSTG向量索引算法允许将向量数据缓存在本地NVMe SSD盘中,大大降低了存储成本,同时突破了内存容量限制,能处理海量向量数据。
数据融合存储优势:与一些仅专注于向量存储或对结构化数据支持较弱的向量数据库不同,MyScale基于ClickHouse能很好地实现结构化数据和向量数据的融合存储,方便在实际应用中关联和处理不同类型的数据。
2.索引技术优势
索引效率优势:MyScale的MSTG向量索引在高维向量搜索中表现出色,在大规模数据集下能快速定位相似向量,相比一些传统的向量索引算法,如FLANN等,具有更高的搜索效率和准确性。
索引灵活性优势:结合了ClickHouse的跳跃索引等机制,对于结构化数据的索引和查询也非常高效,在处理既有向量查询又有结构化数据过滤的复杂场景时,比单纯依靠向量索引的数据库更灵活。
3.查询处理优势
查询语言优势:全面支持SQL语法,这与很多向量数据库使用特定的、非标准查询语言不同。用户可以使用熟悉的SQL进行各种操作,降低了学习成本,且能方便地与现有的数据处理和分析工具集成。
联合查询优势:能在一个查询中无缝地进行向量与结构化数据的联合查询,这是很多其他向量数据库所不具备的强大功能。例如在图像检索应用中,不仅可以根据图像的向量特征进行相似性搜索,还能同时根据图像的元数据(如拍摄时间、地点等)进行过滤查询,而其他数据库可能需要进行多次查询和结果合并。
分布式查询性能优势:在分布式查询处理方面,MyScale能够高效地将查询任务分发到多个节点并行执行,并快速合并结果。与一些分布式向量数据库相比,MyScale在处理大规模数据和高并发查询时,具有更好的性能和可扩展性,能保证系统在高负载下的稳定运行。
4.接口与生态优势
接口兼容性优势:除了标准SQL接口,还提供RESTful API接口,相比一些只提供单一接口的向量数据库,能更好地满足不同应用场景和开发需求,方便与各种系统进行集成。
生态整合优势:基于ClickHouse的生态,MyScale可以利用ClickHouse丰富的工具和生态系统,如数据迁移工具、可视化工具等,而一些新兴的向量数据库可能缺乏完善的生态支持。
四、不足
尽管向量数据库MyScale具有诸多优势,但也存在一些不足之处。
1.技术适配性
技术栈依赖问题:MyScale以ClickHouse为基础构建,这意味着使用它需要用户对ClickHouse的技术栈有一定了解。对于那些没有ClickHouse使用经验或者技术储备的用户来说,学习和上手的成本较高。而且,与一些其他技术栈的融合可能存在一定的挑战,例如在与特定的业务系统或者遗留系统集成时,可能需要额外的开发和调试工作。
复杂场景下的性能调优难度:虽然MyScale在大多数场景下性能表现良好,但在一些极端复杂的场景中,如涉及超大规模数据集、超高并发查询以及复杂的多表关联和嵌套查询时,性能调优可能会比较困难。这需要用户具备较高的数据库管理和性能优化技能,否则可能无法充分发挥MyScale的性能优势。
2.生态系统
第三方工具集成有限:相较于一些成熟的传统数据库或广泛使用的向量数据库,MyScale的生态系统相对不够完善。在与第三方工具和平台的集成方面,可选择的选项相对较少。例如,在数据可视化方面,可能缺乏一些现成的、高度适配MyScale的可视化工具,用户需要花费更多的精力去寻找和开发合适的解决方案。
社区支持和资源丰富度不足:MyScale作为一个相对较新的向量数据库,其社区规模和活跃度可能不如一些老牌数据库。这导致在遇到问题时,用户可能难以从社区中快速获取有效的帮助和解决方案。同时,相关的技术文档、教程、案例等资源也相对有限,不利于用户的学习和使用。
3.成本与服务
云服务成本:如果用户选择使用MyScale的云服务,随着数据量的增长和使用量的增加,成本可能会逐渐上升。尤其是对于一些小型企业或初创公司来说,云服务费用可能会成为一项较大的负担。而且,与一些提供更灵活定价策略的数据库相比,MyScale的云服务定价可能不够灵活,难以满足不同用户的多样化需求。
定制化服务能力有限:在面对一些具有特殊业务需求的用户时,MyScale可能在定制化服务方面存在一定的局限性。由于其技术架构和产品特性已经相对固定,要根据用户的特定需求进行深度定制开发可能会比较困难,这可能会影响到一些对定制化要求较高的企业的使用体验。
五、应用场景
可用于各类文本、图像等数据的智能检索。在企业文档管理、学术数据库、电商商品搜索等场景中,通过向量化技术,能快速准确地从海量数据中找到相关信息,提高搜索效率。
凭借其OLAP架构,可对大规模数据集进行实时分析,为商业智能决策提供支持。企业可以利用MyScale对业务数据进行深入挖掘,发现数据中的潜在规律和趋势。
1.人工智能与自然语言处理
智能客服:在智能客服系统中,MyScale可存储大量的常见问题与答案的向量表示。当用户提出问题时,系统能快速将用户问题向量化,并在数据库中进行相似性搜索,找到最匹配的答案,实现快速准确的自动回复,提高客服效率和用户满意度。
文本生成:在文本生成任务中,如故事创作、文案生成等,MyScale可以存储各种文本片段的向量,为生成模型提供丰富的素材。模型可以根据输入的主题或提示,从数据库中检索相关的向量文本,以此为基础生成更连贯、更有针对性的文本内容。
2.智能搜索
学术搜索:在学术研究领域,MyScale可以对学术论文、研究报告等进行向量化处理。用户能够通过输入关键词或研究主题,快速检索到相关的学术文献,不仅能找到字面匹配的内容,还能根据语义相似性找到相关度更高的研究成果,帮助研究人员更高效地获取信息。
图片搜索:对于图片库管理,MyScale可以将图片的特征向量存储起来。用户可以通过输入描述图片内容的关键词或上传相似图片,利用MyScale进行向量搜索,快速找到与之相似的图片,广泛应用于图像搜索引擎、设计素材库等场景。
3.推荐系统
电商推荐:在电商平台中,MyScale可以结合商品的属性信息、用户的行为数据等生成商品和用户的向量。通过计算向量之间的相似度,为用户推荐符合其兴趣和购买偏好的商品,提高商品的曝光率和销售转化率。
音乐推荐:在音乐平台中,MyScale可根据音乐的风格、旋律、歌词等特征以及用户的收听历史和喜好,为用户推荐相似风格或相关主题的音乐,帮助用户发现更多符合自己口味的音乐作品,提升用户对平台的粘性。
4.数据分析与商业智能
市场趋势分析:企业可以将市场数据、行业报告、消费者反馈等信息进行向量化存储在MyScale中。通过对这些向量数据的分析和挖掘,发现市场的潜在趋势、消费者需求的变化等,为企业的战略决策、产品研发和市场推广提供数据支持。
用户行为分析:在互联网产品中,MyScale可以存储用户的行为数据向量,如用户的操作路径、停留时间、购买频率等。通过对这些向量数据的分析,企业可以深入了解用户的行为模式和偏好,为用户画像、精准营销等提供依据。