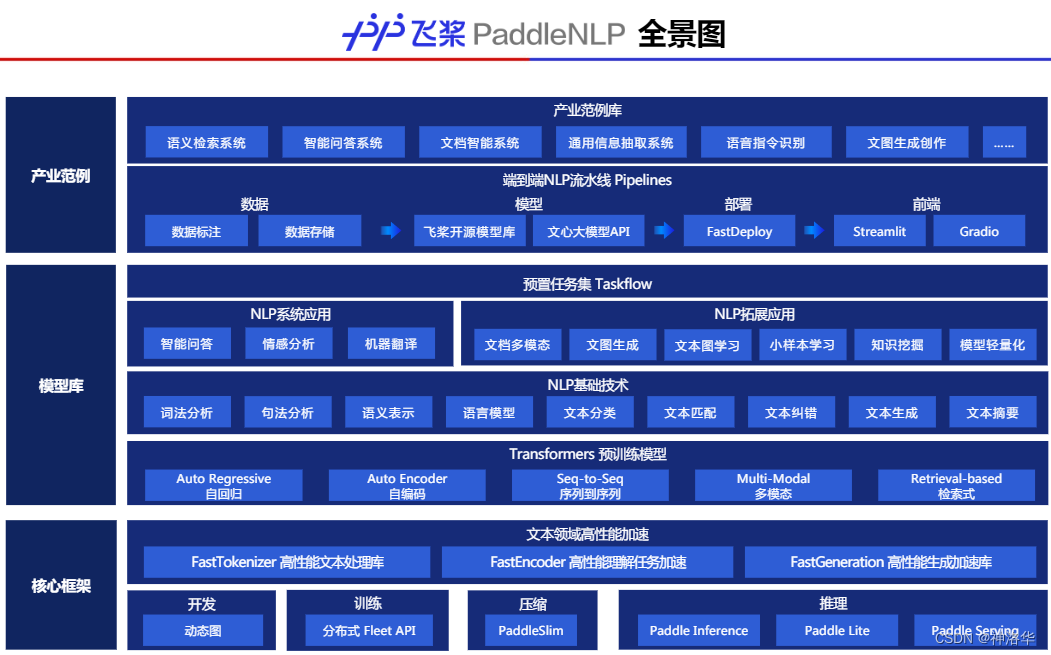
PaddleNLP是百度开发的自然语言处理库,提供了丰富的预训练模型和工具,可用于文本生成、情感分析、知识图谱等多种自然语言处理任务,支持分布式训练和高性能推理,在工业界和学术界都有广泛的应用。
一、特点
1.功能丰富
预训练模型丰富:内置了多种流行的预训练模型,如BERT、RoBERTa、ERNIE、GPT等,覆盖了众多的NLP任务,开发者可以直接调用这些预训练模型进行文本分类、命名实体识别、情感分析、文本生成、问答系统、机器翻译等任务。
全面的任务支持:支持文本分类、神经搜索、问答系统、信息抽取、文档智能、情感分析等从研究到工业应用的广泛NLP任务。
数据处理与工具:提供了用于数据预处理、特征提取和数据加载的工具,如Tokenizer、数据增强等,还包含训练、验证、测试和模型评估的完整工具链,支持多种训练策略和优化算法。
2.技术优势
高效的分布式训练:基于飞桨核心框架领先的自动混合精度优化策略,结合分布式Fleet API,支持4D混合并行策略,可高效地完成大规模预训练模型训练,利用PaddlePaddle框架的优化算法和硬件加速技术,提高了模型的训练和推理性能,支持多GPU训练,提升了模型训练的效率和速度。
大模型自动并行:借助飞桨3.0版本框架的最新特性,通过统一的分布式表示和自动并行技术,大幅简化了组网开发的复杂性,分布式核心代码量减少50%以上,全分布式策略支持的组网使得 Llama 3.1 405B等大模型的SFT与PEFT功能开箱即用。
训推一体优化:依托飞桨框架训推一体特性,在 Policy 模型采样生成复用推理高性能融合算子,使 RLHF 训练加速2.1倍 。还基于飞桨原生的张量并行/流水线并行能力,结合 Offload 训练模式控制显存占用,单机即可完成训练百亿级别 PPO 训练。
多硬件适配:支持英伟达GPU、昆仑芯XPU、昇腾NPU、燧原GCU和海光DCU等多款芯片的大模型训练和推理,仅需适配30余个接口,即可实现大模型的基础适配,低成本完成训练压缩推理全流程,并便捷实现框架与芯片间软硬协同的性能优化。
3.使用便捷
简洁的API设计:提供了一套简洁而全面的API接口,其Pythonic的设计风格,让熟悉Python的开发者能够快速上手,使得模型的加载、微调、评估等操作变得简单易行。
可视化工具:提供了模型训练过程中的可视化工具,帮助用户监控训练进度和性能。
4.社区活跃
开源免费:基于Apache 2.0许可证开源,用户可以自由使用和修改,社区交流活跃,为开发者提供了大量的文档、技术支持和交流平台,用户也可以参与到项目的开发中,贡献自己的代码和想法,推动项目的发展。
持续更新优化:项目团队持续发布新版本,引入新的算法和技术,如RsLoRA+算法、Unified Checkpoint等,不断增强PaddleNLP在大模型训练、精调、对齐和推理方面的能力。
二、技术原理
1.预训练模型:
基于Transformer架构:PaddleNLP中的众多预训练模型大多采用Transformer架构,其核心是多头注意力机制(MultiHead Attention)。这种机制能够让模型在处理文本时,并行地关注不同位置的信息,从而更好地捕捉文本中的长距离依赖关系。例如,在处理一个长句子时,Transformer可以同时关注句子开头和结尾的词语,理解它们之间的语义关联,进而更准确地生成对整个句子的表示。
预训练任务:通过大规模的无监督语料进行预训练,常见的预训练任务包括掩码语言模型(Masked Language Modeling,MLM)和下一句预测(Next Sentence Prediction,NSP)等。在MLM任务中,模型会随机掩盖输入文本中的一些词语,然后预测这些被掩盖的词语,从而学习到文本的语言知识和语义信息;NSP任务则是让模型判断给定的两个句子是否在原文中是相邻的,以此来学习句子之间的逻辑关系,增强模型对文本连贯性的理解。
模型微调:在预训练模型的基础上,针对具体的下游自然语言处理任务进行微调。微调时,会将预训练模型的参数作为初始化,然后在特定任务的有监督数据集上进行进一步训练,使模型能够更好地适应具体任务的特点和需求。例如,在情感分析任务中,通过微调预训练模型,使其能够准确地判断文本所表达的情感倾向是积极、消极还是中性;在命名实体识别任务中,微调后的模型可以准确地识别出文本中的人名、地名、组织机构名等实体。
2.文本表示学习:
词向量表示:将文本中的词语映射为低维向量空间中的向量表示,常用的词向量模型有Word2Vec、GloVe等。这些词向量能够捕捉词语的语义和句法信息,例如,语义相似的词语在向量空间中距离较近。PaddleNLP可以利用这些预训练的词向量作为输入特征,或者在预训练过程中进一步优化词向量的表示,以更好地适应具体任务。
句子和篇章表示:除了词向量,PaddleNLP还能够学习句子和篇章的表示。通过对文本序列进行编码,将整个句子或篇章转换为一个固定维度的向量表示,这个向量能够综合反映文本的语义和结构信息。在文本分类、文本摘要等任务中,这种句子和篇章级别的表示可以作为输入特征,帮助模型做出更准确的决策。
3.注意力机制:注意力机制在PaddleNLP中起着重要作用,它可以帮助模型在处理文本时聚焦于关键信息。在机器翻译任务中,注意力机制能够让模型在生成译文时,根据源语言文本的不同部分分配不同的注意力权重,从而更准确地翻译出每个词语;在文本摘要生成任务中,注意力机制可以帮助模型关注原文中最重要的信息,生成更准确、更精炼的摘要。
4.优化器和训练技巧:
优化器选择:PaddleNLP提供了多种优化器,如随机梯度下降(Stochastic Gradient Descent,SGD)、Adagrad、Adadelta、RMSProp、Adam等。不同的优化器适用于不同的任务和数据集,开发者可以根据具体情况选择合适的优化器来调整模型的参数,以达到更好的训练效果。
训练技巧:为了提高训练效率和模型性能,PaddleNLP还采用了一些训练技巧,如学习率调整策略、梯度裁剪、正则化等。学习率调整策略可以根据训练过程中的情况动态地调整学习率,使模型能够更快地收敛;梯度裁剪可以防止梯度爆炸问题,保证训练的稳定性;正则化方法则可以防止模型过拟合,提高模型的泛化能力。
5.多硬件支持和性能优化:
多硬件训推一体:支持英伟达GPU、昆仑XPU、昇腾NPU、燧原GCU和海光DCU等多个硬件的大模型训练和推理,套件接口支持硬件快速切换,大幅降低硬件切换研发成本。
高效易用的预训练:支持4D高性能训练策略,Trainer支持分布式策略配置化,降低复杂分布式组合带来的使用成本。
高效精调:精调算法深度结合零填充数据流和FlashMask高性能算子,降低训练无效数据填充和计算,大幅提升精调训练吞吐。
无损压缩和高性能推理:大模型套件高性能推理模块内置动态插入和全环节算子融合策略,极大加快并行推理速度 。
三、不足之处
1.模型准确性方面:在某些复杂场景下,PaddleNLP的预训练模型可能无法准确提取用户信息,导致信息丢失或误识别。例如对于一些具有歧义或语义模糊的文本,模型可能难以准确理解其确切含义,从而影响信息抽取和分析的准确性。
2.定制化能力方面:尽管PaddleNLP支持多种模型,但在特定领域或行业内的定制能力仍显不足。当面对一些特有的术语、行业特定的表达方式或小众领域的特殊需求时,可能无法很好地满足定制化要求,需要开发者花费较多精力进行调整和优化。
3.上下文理解方面:在需要深度语义理解的情况下,PaddleNLP可能无法完全把握上下文,从而影响信息抽取和文本生成等任务的效果。比如在处理长篇文本或多轮对话时,可能难以准确地跟踪和利用上下文信息,导致生成的文本连贯性不够或回答不够准确。
4.处理效率方面:对于大规模文本处理时,PaddleNLP在速度和资源消耗上可能不如一些其他竞品。尤其是在处理海量数据或对实时性要求较高的场景下,可能会出现性能瓶颈,需要进一步优化性能以提高处理效率。
5.模型大小和内存占用方面:一些预训练模型体积较大,在加载和运行时会占用较多内存,对硬件资源要求较高,可能在一些内存有限的设备上运行困难,或者导致系统整体性能下降,增加了部署和运行成本。
6.对罕见词和生僻语言现象的处理:对于一些罕见的词汇、新出现的网络用语或特定领域的生僻语言现象,模型可能缺乏足够的训练数据和理解能力,导致对这些内容的处理效果不佳,影响对文本的全面准确理解。
四、应用场景
1.信息抽取
命名实体识别:能够从文本中准确识别出人名、地名、组织机构名等命名实体,可应用于知识图谱构建、信息检索、智能问答等系统,帮助机器更好地理解文本中的关键信息,例如在新闻报道中自动提取出相关人物、地点等信息。
关系抽取:用于抽取文本中实体之间的关系,如人物之间的亲属关系、公司与产品的所属关系等,有助于构建更丰富的知识图谱,为智能搜索、推荐系统等提供更有价值的知识支持。
事件抽取:从文本中识别出特定类型的事件,并提取出事件的相关要素,如时间、地点、人物、事件类型等,可用于舆情监测、新闻报道分析等领域,帮助用户快速了解事件的全貌。
2.文本分类
情感分析:通过对文本的情感倾向进行分析,判断其是积极、消极还是中性情感,广泛应用于社交媒体监控、产品评论分析、市场调研等场景,帮助企业了解用户对产品或服务的态度和评价,从而做出相应的决策。
主题分类:将文本划分到不同的主题类别中,如新闻、科技、娱乐、体育等,可用于新闻推荐、文档管理、内容审核等,提高信息筛选和推荐的效率。
意图识别:在对话系统、智能客服等应用中,识别用户输入文本的意图,如查询信息、提出建议、表达不满等,以便系统能够做出准确的响应,提供更优质的用户体验。
3.问答系统
基于知识的问答:利用知识图谱等知识资源,结合PaddleNLP的文本理解和推理能力,回答用户提出的各种问题,如历史事件、科学知识、人物信息等,为用户提供准确、详细的答案。
阅读理解式问答:对给定的文本段落进行理解和分析,回答与该文本相关的问题,可应用于教育、法律、医疗等领域,帮助用户快速获取文本中的关键信息和答案。
对话式问答:在聊天机器人等对话系统中,实时回答用户的问题,与用户进行自然流畅的对话,需要具备多轮对话管理、上下文理解等能力,PaddleNLP可以为对话式问答系统提供有力的支持,提升系统的性能和用户体验。
4.文本生成
机器翻译:将一种语言的文本自动翻译成另一种语言,借助PaddleNLP的预训练模型和序列到序列学习技术,实现高质量的机器翻译,打破语言障碍,促进不同语言之间的交流和信息共享。
文本摘要生成:能够自动生成文本的摘要,提取出文本的关键信息和主要内容,可应用于新闻报道、学术论文、文档管理等领域,帮助用户快速了解文本的核心要点,提高信息获取的效率。
故事生成:根据给定的主题或上下文,生成连贯、有趣的故事文本,可用于创意写作、娱乐等领域,展现了自然语言处理在创造性文本生成方面的潜力。
5.智能搜索
查询理解:对用户输入的搜索查询进行理解和分析,包括词法分析、句法分析、语义理解等,将用户的查询意图转化为更准确的搜索条件,提高搜索结果的相关性和准确性。
文档检索:对大量的文本文档进行索引和检索,根据用户的查询请求,快速找到与查询相关的文档,并对检索结果进行排序和展示,可应用于搜索引擎、企业文档管理等系统,帮助用户快速找到所需的信息。
问答式搜索:将问答系统与搜索技术相结合,直接回答用户的问题,而不仅仅是返回相关的文档链接,为用户提供更便捷、高效的搜索体验,例如在搜索引擎中直接回答用户关于某个知识点的问题。
6.社交媒体分析
舆情监测:实时监测社交媒体上的信息,对用户的言论、情感倾向、热点话题等进行分析和挖掘,帮助企业、政府等机构及时了解公众对某一事件、产品或政策的看法和态度,以便做出相应的应对措施。
用户画像:通过对用户在社交媒体上发布的文本内容进行分析,提取用户的兴趣爱好、性格特点、消费偏好等信息,构建用户画像,为精准营销、个性化推荐等提供依据。
虚假信息检测:识别社交媒体上的虚假信息、谣言等不实内容,通过对文本的真实性、可信度进行评估,帮助用户辨别信息的真伪,维护网络信息的真实性和可信度。