视频理解工具是用于从视频内容中提取有意义的信息,如物体识别、动作识别、场景理解、情感分析等诸多方面的软件或技术。
项目构建于“SomethingSomething”数据集之上的庞大注释库,涵盖了对超过18万段视频中每一帧内对象和手部互动的细致框选,为动作识别和空间时间网络的研究提供了丰富的数据支持。
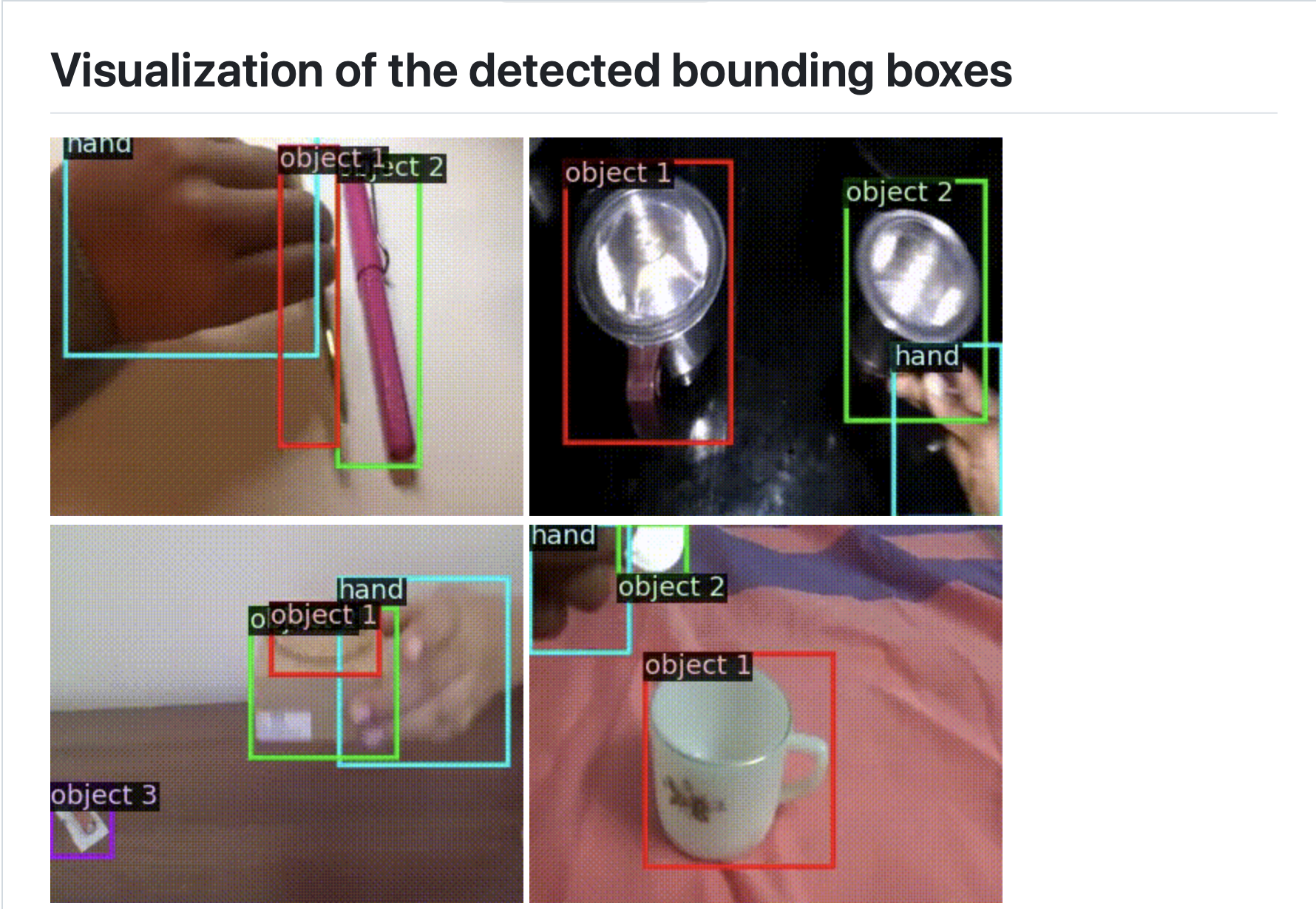
其核心价值在于详尽且高精度的手工标注数据,每帧数据以字典形式储存,还提供了关键脚本,如用于可视化真实值边界框或检测结果的 annotate_videos.py,方便研究者进行实验设计与成果展示。
项目地址:https://github.com/joaanna/something_else
一、项目特点
项目包含数据目录、源代码目录、测试代码目录等,其中数据目录存放标注文件和视频文件,源代码目录包含项目启动文件、配置文件、模型相关代码和工具函数。
它能够对每一帧进行细致的手动或半自动标注,确保数据的准确性,并且能够验证视频序列中对象行为的时序一致性,利于模型学习动态变化。
1.大规模与细粒度:超过18万条视频记录,每帧都有详细注解,覆盖广泛的人类日常活动。
2.科学严谨:与学术论文紧密关联,保证了数据的科研价值和可信度。
3.易接入:提供清晰的下载链接和说明,开发者可快速集成到自己的研究或项目中。
4.可视化工具:附带的代码示例使用户能轻松地可视化标注结果,直观感受数据质量。
5.基线模型支持:附带训练脚本和预训练模型,加速新研究的起点,减少入门门槛。
二、技术原理
1.数据标注与存储
精细标注:通过人工标注或半自动标注的方式,对视频的每一帧进行细致处理,标注出视频中的各种对象,如物体的类别、位置,以及人手的位置等信息。例如,明确标注出某一帧中出现的物体是“pillow”(枕头)以及其对应的边界框坐标。
JSON格式存储:将标注信息以JSON格式进行存储,这种格式具有良好的可读性和可扩展性,方便数据的管理和后续处理。标注数据以字典形式存在,其中包含了对象类别、位置信息等键值对,使得数据能够被计算机高效地读取和解析。
2.时空交互理解
时序一致性验证:注重视频序列中对象行为逻辑的一致性,确保在不同帧之间,对象的运动和变化符合自然规律和常识。这有助于模型学习到对象的动态变化模式,从而更好地理解视频中的时空交互关系。例如,在一个动作场景中,人物的动作应该是连贯流畅的,不会出现突然的跳跃或不合理的停顿,通过对这种时序一致性的验证和学习,模型能够更准确地识别和理解复杂的动作。
空间关系分析:对视频帧中物体和人手等元素的空间位置关系进行精确分析和标注。通过这种方式,模型可以学习到不同物体之间的相对位置、接触关系等空间信息,进而理解它们在动作中的相互作用。比如,在一个人拿起杯子的动作中,模型需要知道手与杯子的空间位置关系,以及两者如何随着时间变化而产生交互,从而准确地识别出这一“拿起”动作。
3.模型训练与应用
基于标注数据训练模型:利用大量标注好的数据对机器学习或深度学习模型进行训练,使模型能够学习到不同对象、动作和时空关系的特征模式。在训练过程中,模型通过不断调整参数,以最小化预测结果与标注数据之间的差异,从而逐渐提高对视频内容的理解和预测能力。
动作识别与理解:经过训练的模型可以应用于各种实际场景中的动作识别任务,能够准确地识别出视频中人物或物体所执行的复杂动作。例如,在监控视频中自动识别出异常行为,如打斗、偷窃等;在智能家居场景中,理解用户的手势动作,实现对设备的控制。
辅助技术研发:为针对障碍人士的智能辅助设备开发提供支持,帮助设备理解特定的动作指令,以便更好地为用户提供帮助。比如,通过识别肢体动作不便的用户的特定手势,辅助设备可以自动执行相应的操作,如开门、开灯等。
三、不足之处
1. 数据集限制:虽然“Something-Else Annotations”提供了大规模和细粒度的标注数据,但这些数据可能主要集中于特定类型的视频内容,如人类日常活动,这可能限制了其在其他视频内容或更广泛场景下的应用。
2. 计算资源需求:高精度的视频理解通常需要大量的计算资源,特别是在处理大规模视频数据集时。这可能限制了资源受限的研究团队或个人使用该工具的能力。
3. 模型泛化能力:虽然“Something-Else Annotations”提供了基线模型和预训练模型,但这些模型可能在特定数据集上表现良好,而在新的、不同的数据集上可能需要额外的调整和训练以提高泛化能力。
4. 实时处理能力:视频理解工具在处理实时视频流时可能面临挑战,尤其是在需要快速响应的应用场景中,如实时监控或交互式应用,这可能需要更高效的算法和优化。
5. 用户界面和体验:虽然提供了代码示例和文档,但用户界面和体验可能还有改进空间,特别是在可视化标注结果和用户交互方面,以便非专业用户也能轻松使用。
四、应用场景
主要应用于计算机视觉尤其是视频理解领域的研究和开发,也可用于机器人学与自动化控制等领域,帮助机器人更好地理解人体语言,从而做出更智能的响应。
1.学术研究领域
动作识别研究:作为一个庞大且标注精细的注释库,为研究人员提供了丰富的数据资源,可用于探索和改进动作识别算法,提升模型对复杂动作的理解和分类能力,推动计算机视觉领域中动作识别技术的发展。
时空交互网络研究:其详细的对象和手部互动框选标注,有助于深入研究时空交互网络,分析视频中物体和动作在时间与空间上的关系,为构建更高效的时空模型提供实证基础,促进相关理论和技术的创新。
2.机器人与自动化领域
人机交互:通过提供大量的人类行为注释数据,帮助机器人更好地理解人类的动作、手势和意图,从而实现更自然、更智能的人机交互。例如,机器人可以根据人类的手部动作来判断是否需要递接物品等。
行为预测与决策:基于对视频中人类行为模式的学习和理解,机器人能够预测人类的下一步行动,提前做出相应的决策和规划,更好地配合人类的活动,提高机器人在各种场景下的自主性和适应性。
3.视频内容分析与管理领域
视频分类与标注:协助视频内容管理平台对海量视频进行快速、准确的分类和标注,根据视频中的对象、动作等信息自动生成标签,方便用户搜索和浏览视频资源,提高视频内容的管理效率和可发现性。
内容审核:可用于自动检测视频中是否包含特定的对象或动作,帮助审核人员快速筛选出可能存在违规内容的视频,如暴力、色情、侵权等,减轻人工审核的负担,提高审核的速度和准确性。
4.智能安防领域
异常行为检测:通过对监控视频的分析,识别出与正常行为模式不符的异常行为,如人员的突然奔跑、打斗、物品的异常移动等,及时发出警报,提高安防监控系统的预警能力,保障公共安全和场所的安全监控。
事件分析与追溯:在发生安全事件后,能够帮助安防人员快速回顾和分析相关视频,了解事件的全貌,包括事件的起因、经过和参与人员等信息,为事件的调查和处理提供有力支持。
5.教育与培训领域
教学资源开发:教育工作者可以利用该工具对教学视频进行分析和标注,提取出关键的知识点、教学动作等信息,用于制作更具针对性和高效的教学资源,如自动生成教学摘要、知识点索引等,辅助教学活动的开展。
学习行为分析:通过分析学生在观看教学视频过程中的行为表现,如注意力集中程度、学习进度等,为个性化学习提供依据,教师可以根据学生的学习情况调整教学策略,提高教学效果。
6.医疗保健领域
医疗视频分析:在医疗领域,可用于分析手术视频、康复训练视频等,辅助医生进行病情诊断、手术操作评估和康复效果监测。例如,通过识别手术中的关键动作和器械使用情况,为医学研究和教学提供参考依据。
患者行为监测:对患者在医院内的活动视频进行监测和分析,了解患者的行为模式和生活习惯,及时发现患者的异常行为或需求,提高医院的护理质量和患者的安全性。
7.娱乐与文化产业领域
视频推荐与个性化服务:结合用户的观看历史和兴趣偏好,利用该工具对视频内容进行深度理解,为用户提供更精准、个性化的视频推荐,提升用户的观看体验,增加视频平台的用户粘性。
影视制作与后期:在影视制作过程中,帮助编辑人员快速定位和筛选视频素材,根据故事情节和角色动作等要求找到合适的片段。同时,也可用于视频特效制作、场景重建等方面,提高影视制作的效率和质量.