OpenMAGVIT2由腾讯ARC实验室、清华大学和南京大学共同发起的OpenMAGVIT2项目,旨在民主化自回归视觉生成,提供了从300M到1.5B参数规模的自回归图像生成模型。
一、项目介绍
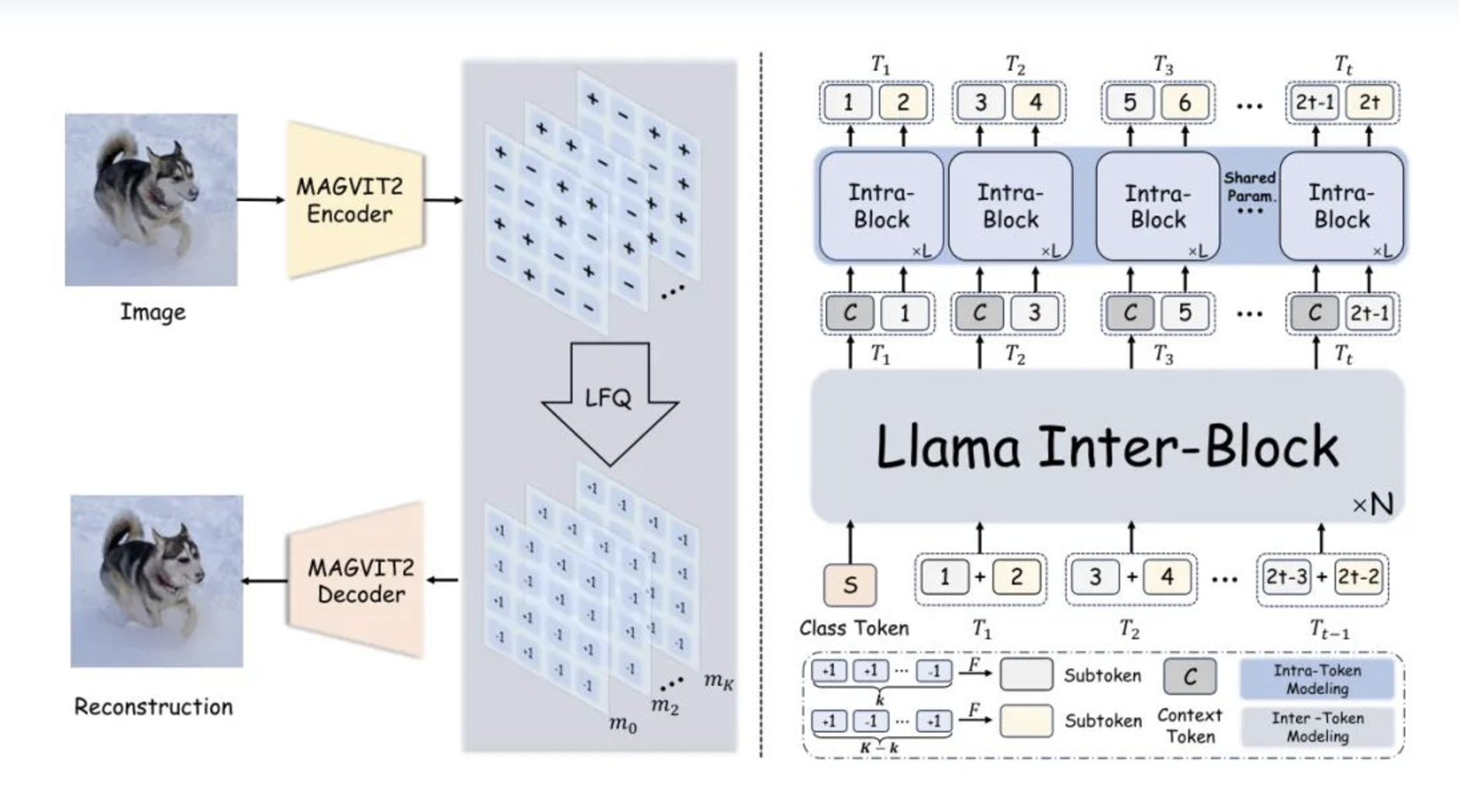
OpenMAGVIT2通过改进原有的VQGAN架构,克服代码本大小限制及利用率低的问题,全面提升自回归视觉生成的质量与效率,实现自动回归视觉生成的民主化。产生了一个开源的Google MAGVITv2分词器的复制,这是一个具有超大规模词汇表(即,$2^{18}$个代码)的分词器,并在ImageNet 256x256上实现了最先进的重建性能(1.17 rFID)。
1.项目地址:[https://gitcode.com/gh_mirrors/op/OpenMAGVIT2](https://gitcode.com/gh_mirrors/op/OpenMAGVIT2)
2.技术分析
核心突破:引入无需查找表(lookupfree)的技术,结合巨大的代码本,显著提升了模型对视觉信息的理解与表达能力。并且选择PatchGAN作为判别器进行训练,而非传统的StyleGAN,提高了模型的稳定性与图像重构质量。
架构改进:在编码器中的降采样采用带有学习核的步长卷积,解码器中的上采样器则是深度到空间的操作;重新实现了一种自适应组合归一化层,将量化的向量与解码器中每个残差块的输出相加。
3.性能表现
项目在不同分辨率下的ImageNet数据集上进行了严格测试,对比VQGAN以及近期热门的TiTok、LlamaGen等模型,均取得了顶尖成绩,在下采样率为8倍的情况下,实现了史上最低的rFID得分——0.39分,充分证明了其优越性。
4.项目特点
创新性:打破传统VQGAN的局限,采用创新的无查找表量化方法,并拥有庞大的代码本规模,是当前最具创新能力的视觉生成工具之一。
无需查找表技术:引入无需查找表(lookupfree)的技术,结合巨大的代码本(高达\\(2^{18}\\)),显著提升了模型对视觉信息的理解与表达能力,使生成的图像和视频在细节和准确性上更出色。选择PatchGAN作为判别器进行训练,而非传统的StyleGAN,提高了模型的稳定性与图像重构质量,有助于生成更清晰、更逼真的视觉内容。在编码器中的降采样采用带有学习核的步长卷积,解码器中的上采样器则是深度到空间的操作;重新实现了一种自适应组合归一化层,将量化的向量与解码器中每个残差块的输出相加,进一步优化了模型的性能。
高性能:得益于先进的架构与训练策略,在多个指标上达到行业领先水平,特别是图像重构质量和代码书利用率方面。在不同分辨率下的ImageNet数据集上进行了严格测试,对比VQGAN以及近期热门的TiTok、LlamaGen等模型,均取得了顶尖成绩,在下采样率为8倍的情况下,实现了史上最低的rFID得分——0.39分,充分证明了其在图像生成质量和准确性方面的优越性。
应用拓展优势:能够广泛应用于各种图像与视频的合成任务,以及图像修复、风格转换、超分辨率处理等视觉理解与增强领域,还可应用于智能设计、医疗、交通等多个领域,为不同行业提供了强大的视觉生成和处理能力,具有很强的实用性和应用价值。
二、生成图像步骤
1. 安装依赖:确保你的系统安装了Python 3.8.8及以上版本和CUDA 11.8 ,然后在项目目录下通过命令`pip install r requirements.txt`安装所需的Python依赖包。
2. 准备数据和配置文件:
数据准备:收集用于训练或生成图像的相关数据,并将其整理到合适的目录结构中,同时记录好数据的路径 。
配置文件修改:在`configs/`目录下找到相应的配置文件,通常为`.yaml`或`.json`格式,根据你的具体需求和数据情况,修改配置文件中的参数,如模型的超参数、数据路径、训练参数等,例如设置图像的分辨率、训练的轮数、批次大小、学习率等。
3. 训练视觉分词器:使用`scripts/train_tokenizer/`目录下的脚本训练视觉分词器,通过命令`python main.py config configs/your_tokenizer_config.yaml mode train_tokenizer`来启动训练,其中`your_tokenizer_config.yaml`是你配置好的视觉分词器训练配置文件路径.
4. 训练自回归模型:在视觉分词器训练完成后,使用`scripts/train_autogressive/`目录下的脚本训练自回归模型,执行命令`python main.py config configs/your_autoregressive_config.yaml mode train_autogressive`,这里的`your_autoregressive_config.yaml`是自回归模型的训练配置文件路径。
5. 生成图像:完成模型训练后,使用`generate.py`脚本生成图像,运行命令`python generate.py config configs/your_generation_config.yaml`,在配置文件中指定生成图像的相关参数,如生成图像的数量、初始条件等。
在生成图像的过程中,还可以通过调整配置文件中的参数来控制生成图像的质量、多样性等,以满足不同的需求 。
三、不足之处
1.计算资源与时间成本
硬件要求高:OpenMAGVIT2模型规模较大,训练和生成图像时对硬件计算资源的需求较高,通常需要强大的GPU集群来支持,这对于普通用户和研究机构来说,硬件成本可能是一个较大的限制因素。
训练和推理时间长:由于模型结构复杂,训练过程耗时较长,尤其是在处理大规模数据集时,需要大量的时间来进行参数优化和收敛。在推理阶段,生成高质量图像也需要一定的时间,难以满足实时性要求较高的应用场景。
2.模型复杂度与可解释性
架构复杂:OpenMAGVIT2的模型架构相对复杂,包含多个组件和层次,如编码器、解码器、量化器、自回归Transformer等,这使得模型的理解、调试和改进难度较大,对于研究人员深入探究其内部工作原理和进行针对性优化带来了挑战。
可解释性差:与许多深度学习模型一样,OpenMAGVIT2的可解释性较弱,难以直观地理解模型是如何根据输入生成特定的图像内容,以及模型各个部分在生成过程中的具体作用和贡献,这在一定程度上限制了其在一些对可解释性要求较高领域的应用。
3.数据依赖性与泛化能力
数据量要求大:为了训练出高性能的OpenMAGVIT2模型,需要大量的图像数据来学习丰富的视觉模式和语义信息。在数据量不足的情况下,模型可能无法充分学习到各种图像特征,导致生成效果不佳。
泛化能力有限:尽管OpenMAGVIT2在一些标准数据集上取得了较好的成绩,但在面对不同分布、不同领域或具有特殊特征的图像数据时,其泛化能力可能会受到限制,生成的图像质量和准确性可能会下降,难以适应多样化的实际应用场景。
4.生成结果的局限性
图像细节与真实性:虽然OpenMAGVIT2能够生成高质量的图像,但在一些复杂场景和细节丰富的图像生成任务中,仍然可能存在细节不够准确、真实感不足的问题,与真实图像相比,在精细度和自然度上还有一定的差距。
多样性不足:生成图像的多样性相对有限,可能会出现生成结果较为相似或模式化的情况,难以满足用户对于生成具有高度多样性和独特性图像的需求。
5.对比优势的相对性
与扩散模型比较:尽管OpenMAGVIT2在某些方面取得了领先性能,但与扩散模型相比,在图像生成的整体质量、多样性和稳定性上,并不具有绝对的优势,扩散模型在一些场景下仍然能够生成更具视觉吸引力和真实感的图像。
四、应用场景
1.图像与视频生成领域 :
艺术创作:艺术家可以利用OpenMAGVIT2生成独特的绘画、插画等创意图像,为艺术作品增添新的元素和风格,激发创作灵感。比如生成具有梦幻色彩、超现实风格的图像,作为绘画的参考或直接作为数字艺术作品展示。
娱乐产业:在影视制作中,可以生成虚拟场景、特效元素等,降低制作成本和时间。例如生成古代宫殿、未来城市等复杂场景,或者奇幻生物、外星生物等特效形象,为影视作品增添视觉效果。在游戏开发中,可用于生成游戏中的角色形象、道具、场景等,丰富游戏内容,提升游戏的视觉体验。
广告与营销:能够快速生成吸引人的广告图片和视频,根据不同的产品特点和目标受众,定制个性化的广告内容。比如为某款时尚产品生成时尚模特穿着该产品的不同场景图片,或为某品牌饮料生成在各种户外场景中饮用的视频,提高广告的吸引力和转化率。
教育科普:可以生成教学所需的图像和视频资料,如生物课上的细胞结构动画、地理课上的地质演变过程视频等,使教学内容更加生动形象,帮助学生更好地理解和记忆知识。
2.视觉理解与增强领域 :
图像修复:对于破损、有瑕疵的老照片或图像,OpenMAGVIT2能够根据图像的上下文信息,自动修复和还原图像的缺失部分,使图像更加完整和清晰。
风格转换:可以将一种图像风格转换为另一种风格,如将写实照片转换为油画风格、水墨画风格等,满足用户对不同艺术风格的需求,为图像赋予新的艺术价值。
超分辨率处理:将低分辨率的图像提升为高分辨率图像,使图像细节更加丰富,可用于监控视频的增强、卫星图像的优化等,提高图像的可用性和分析价值。
3.智能设计领域:
服装设计:根据设计师提供的草图或设计理念,生成不同款式、颜色、图案的服装效果图,帮助设计师快速预览和筛选设计方案,提高设计效率。
建筑设计:生成建筑外观、内部空间布局等效果图,让设计师和客户更直观地感受设计效果,提前发现和修改潜在问题,减少实际建设中的风险和成本。
4.医疗领域 :
医学影像分析:辅助医生对医学影像进行分析和诊断,例如生成病变区域的标注图像,帮助医生更准确地识别和定位病灶,提高诊断的准确性和效率。
手术规划:根据患者的医学影像数据,生成三维重建模型,为手术方案的制定提供更直观的参考,帮助医生更好地规划手术路径和操作步骤。
5.交通领域 :
交通流量监测:通过对交通监控视频的分析,生成交通流量的可视化图像和数据,帮助交通管理部门更好地了解交通状况,及时调整交通信号灯和疏导交通。
自动驾驶辅助:为自动驾驶汽车提供更准确的环境感知和图像识别能力,例如生成道路场景的语义分割图像,帮助车辆识别道路、车辆、行人等物体,提高自动驾驶的安全性和可靠性 。