深度Q网络(Deep Q-Network, DQN)是一种结合了深度学习和强化学习的方法,它由 DeepMind 团队提出,并在多个领域取得了显著的成果。
一、DQN基本概念
1. **强化学习基础**:强化学习是一种让智能体通过与环境的交互来学习最优行为策略的方法。智能体在给定状态下执行动作,环境根据动作给出奖励,智能体的目标是最大化长期累积奖励。
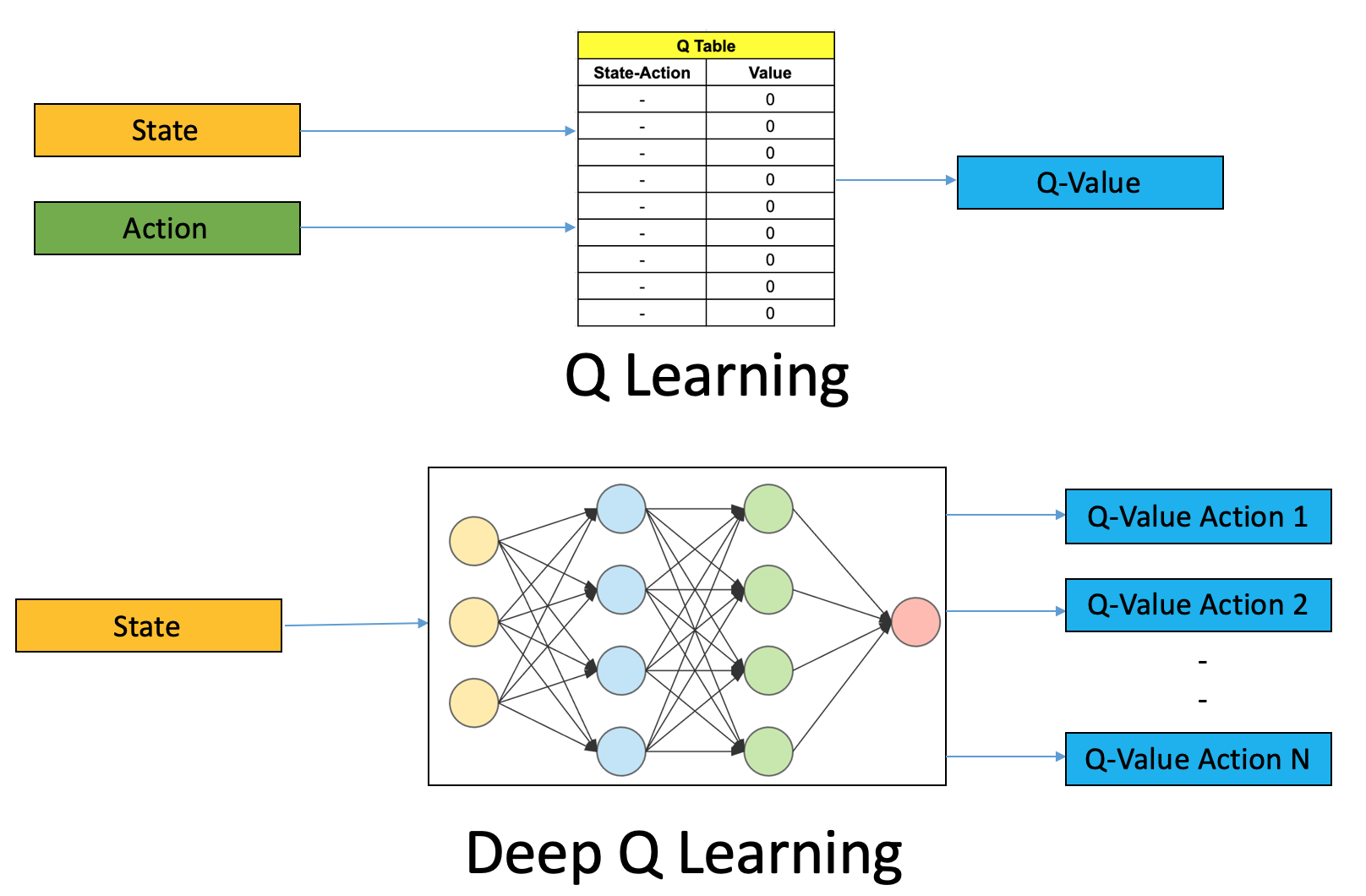
2. **Q-Learning**:Q-Learning是一种无模型的强化学习算法,它通过学习一个状态-动作值函数(Q函数)来预测采取某个动作在某个状态下的期望回报。
3. **DQN的提出**:在状态空间非常大或者连续的情况下,传统的Q-Learning方法难以应用,因为无法为每个状态-动作对存储Q值。DQN通过使用深度神经网络来近似Q函数,解决了这个问题。
4. **经验回放(Experience Replay)**:DQN引入了经验回放机制,通过将过去的经验存储在一个缓冲区中,并在训练过程中随机抽取样本,从而提高了数据的利用率并减少了样本之间的相关性。
5. **目标网络(Target Network)**:为了进一步稳定训练过程,DQN使用了两个结构相同但参数不同的神经网络:一个用于预测Q值(主网络),另一个用于计算目标Q值(目标网络)。目标网络的参数会定期更新,这有助于减少训练过程中的不稳定性。
二、训练过程
1. **初始化网络**:通常使用两个结构相同的深度神经网络,一个是在线更新的网络(evaluate network),另一个是定期复制前者权重的目标网络(target network)。
2. **经验回放**:DQN使用一个称为经验回放的技术来存储和随机抽样过去的经验(状态、动作、奖励和新的状态),以此来打破数据之间的相关性,提高学习效率。
3. **目标网络**:为了提高训练的稳定性和收敛速度,DQN引入了目标网络的概念。目标网络的参数会定期从在线网络复制过来,但在两者之间会有一定的延迟。这样做可以保持目标值的稳定性,防止过拟合。
4. **Q值更新**:在线网络用于计算当前策略选择的Q值以及进行Q值迭代更新和梯度下降反向传播。而目标网络则用来计算TD Target中下一状态的Q值。
5. **epsilon-greedy策略**:这是一种探索与利用的平衡策略,它决定了智能体在每次决策时是选择已知的最佳行动(利用),还是随机选择一个可能不是最优的行动来探索环境(探索)。随着时间的推移,epsilon值逐渐减小,智能体逐渐减少探索,增加利用。
6. **梯度下降和反向传播**:DQN使用梯度下降方法来更新网络权重,并通过反向传播算法来计算梯度,以最小化预测Q值和实际Q值之间的差异。
7. **模型保存**:在训练过程中,可以在特定的时间点保存模型的权重,以便在未来的任务中使用或继续训练。
8. **性能评估**:通常会通过一些指标来评估DQN的性能,如平均奖励、学习曲线等。
9. **超参数调整**:DQN的训练涉及多个超参数,如学习率、折扣因子、epsilon的初始值和衰减速率等,这些超参数的选择对模型的性能有重要影响。
10. **持续迭代**:DQN的训练是一个持续迭代的过程,需要不断地让智能体与环境交互,收集数据,更新网络,直到模型的性能达到满意的水平。
11. **比较与其他算法**:DQN与传统的强化学习算法相比,能够处理更复杂的环境,并在许多情况下显示出更好的性能。
总的来说,DQN的训练过程是一个复杂的过程,涉及到多个组件和技巧的合理运用。通过这些步骤,DQN能够在多种强化学习问题中有效地学习和优化Q值函数,从而实现在复杂环境中的有效决策。
三、商业应用
1. **游戏领域**:DQN最初在Atari 2600游戏机上取得了突破性进展,其中算法能够学习如何玩多种游戏,并达到超人的表现。例如,在《吃豆人》游戏中,DQN能让AI玩家达到人类玩家的水平。
2. **自动驾驶**:DQN也被应用于自动驾驶车辆的控制系统中,帮助车辆在复杂的交通环境中做出决策,如路径规划和避障。
3. **机器人控制**:在机器人领域,DQN用于训练机器人执行任务,如抓取物体、行走或飞行,通过与环境的交互来学习最优策略。
4. **推荐系统**:DQN可以用于推荐系统中,通过强化学习来优化用户的选择和推荐,提高推荐的相关性和用户满意度。
5. **医疗决策支持**:在医疗领域,DQN有潜力辅助医生做出诊断和治疗决策,通过分析大量数据来预测最佳的治疗方案。
6. **能源管理**:DQN可以用于智能电网的管理,优化能源分配和消耗,提高能源效率。
7. **金融交易**:在金融行业,DQN可以用于开发交易策略,通过分析市场数据来预测股票价格走势并做出交易决策。
DQN的成功应用展示了深度强化学习在解决现实世界问题中的潜力,随着技术的进步,未来可能会有更多创新的商业应用出现。
四、使用PyTorch实现DQN
以下是使用PyTorch实现DQN的示例代码:
```python
import torch
import torch.nn as nn
import torch.optim as optim
import numpy as np
class DQN(nn.Module):
def __init__(self, input_dim, output_dim):
super(DQN, self).__init__()
self.fc1 = nn.Linear(input_dim, 64)
self.fc2 = nn.Linear(64, 32)
self.fc3 = nn.Linear(32, output_dim)
def forward(self, x):
x = torch.relu(self.fc1(x))
x = torch.relu(self.fc2(x))
x = self.fc3(x)
return x
class DQNAgent:
def __init__(self, input_dim, output_dim, learning_rate=0.001, discount_factor=0.99, epsilon=1.0, epsilon_decay=0.995, epsilon_min=0.01):
self.input_dim = input_dim
self.output_dim = output_dim
self.learning_rate = learning_rate
self.discount_factor = discount_factor
self.epsilon = epsilon
self.epsilon_decay = epsilon_decay
self.epsilon_min = epsilon_min
self.model = DQN(input_dim, output_dim)
self.optimizer = optim.Adam(self.model.parameters(), lr=learning_rate)
self.loss_fn = nn.MSELoss()
def choose_action(self, state):
if np.random.rand() < self.epsilon:
return np.random.choice(self.output_dim)
else:
state = torch.tensor(state, dtype=torch.float32).unsqueeze(0)
q_values = self.model(state)
return torch.argmax(q_values).item()
def train(self, state, action, reward, next_state, done):
state = torch.tensor(state, dtype=torch.float32).unsqueeze(0)
next_state = torch.tensor(next_state, dtype=torch.float32).unsqueeze(0)
target = self.model(state)[0][action]
if done:
target = reward
else:
next_q_values = self.model(next_state)
target = reward + self.discount_factor * torch.max(next_q_values)
loss = self.loss_fn(target, self.model(state)[0][action])
self.optimizer.zero_grad()
loss.backward()
self.optimizer.step()
if self.epsilon > self.epsilon_min:
self.epsilon *= self.epsilon_decay
```
以上代码实现了一个简单的DQN智能体,其中`DQN`类是神经网络模型,`DQNAgent`类是智能体。在`DQNAgent`类中,`choose_action`方法用于选择动作,`train`方法用于训练模型。在训练过程中,使用MSE损失函数和Adam优化器进行梯度下降更新网络权重。
DQN的提出为强化学习领域带来了革命性的变化,它证明了深度学习与强化学习结合的强大潜力,并为后续的研究和应用奠定了基础。