Encoder-Decoder(编码器-解码器)是深度学习领域中用于处理序列转换任务的核心通用架构,也是Seq2Seq(序列到序列)模型的顶层范式——Seq2Seq本质是Encoder-Decoder架构在时序序列映射场景下的具体实现,广泛应用于自然语言处理、计算机视觉、语音处理等多个领域,核心目标是将一种输入序列(如文本、语音、图像特征序列)映射为另一种输出序列(如翻译文本、摘要、语音波形)。
一、定义
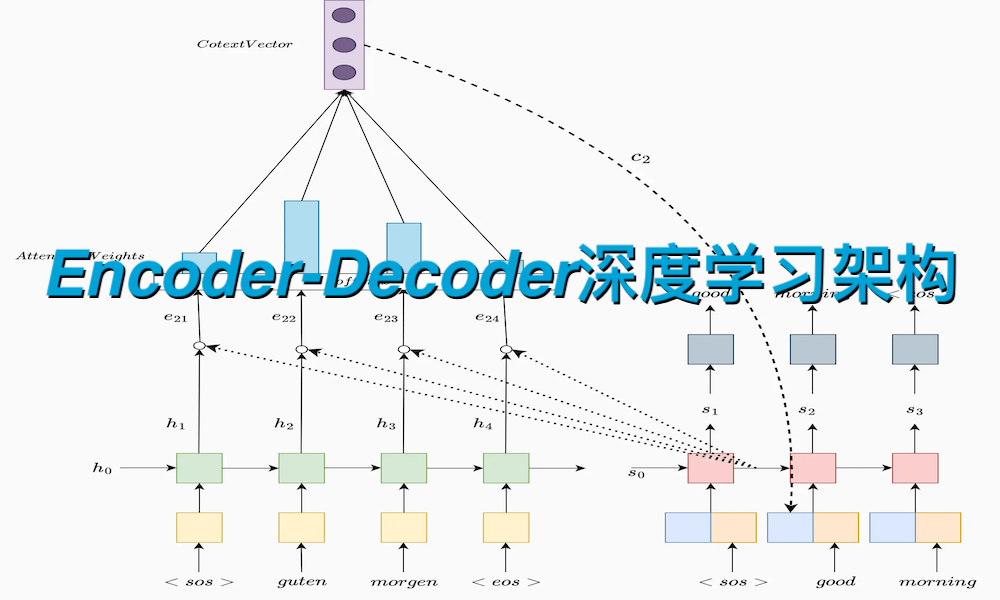
Encoder-Decoder架构的核心思想的是“分两步走”:先通过编码器(Encoder)将输入序列的语义信息进行提取、编码,转化为一个固定长度或动态长度的语义表示(也称为“上下文向量”或“隐状态向量”);再通过解码器(Decoder)接收这个语义表示,逐步生成符合任务需求的输出序列。
设计初衷是解决“输入与输出长度不固定、语义需跨序列传递”的问题——传统的深度学习模型(如单一层全连接、普通RNN)无法直接处理变长序列的转换,而Encoder-Decoder通过“编码-解码”的拆分,实现了对变长输入的统一表征和变长输出的有序生成。
二、Encoder(编码器)
编码器的核心功能是提取输入序列的语义特征,将其转化为可被解码器利用的语义表示,不直接参与输出生成,仅负责“读懂”输入内容并进行抽象编码。其结构可基于不同的基础网络构建,常见类型如下:
1.传统RNN类编码器
早期Encoder-Decoder的主流实现,基于循环神经网络(RNN)及其变体,通过时序迭代的方式处理输入序列,捕捉序列中的顺序依赖关系:
•基础RNN编码器:简单的循环结构,逐词/逐帧处理输入序列,将最后一个时刻的隐状态作为全局语义表示,但存在长距离依赖消失的问题。
•LSTM编码器:引入遗忘门、输入门、输出门,解决RNN的长距离依赖问题,能更好地保留输入序列的长程语义信息,是早期NLP任务(如机器翻译)的标配。
•GRU编码器:简化LSTM的门结构(仅保留重置门和更新门),在保证性能的同时降低计算复杂度,适合算力有限的场景。
2.CNN类编码器
基于一维卷积神经网络(1D-CNN)构建,通过卷积核滑动提取输入序列的局部特征,再通过池化操作整合全局信息,生成语义表示。其优势是并行计算能力强,能同时处理序列中的多个位置,效率高于RNN类编码器,但对序列的顺序依赖捕捉能力较弱,适合短序列转换任务(如短文本改写)。
3.Transformer编码器
基于自注意力机制(Self-Attention)构建,是当前Encoder-Decoder架构的主流选择。通过自注意力机制,编码器能同时关注输入序列中的所有位置,捕捉任意两个位置之间的依赖关系,无需时序迭代,并行效率极高,且能有效解决长距离依赖问题。
典型代表是BERT、RoBERTa等模型的编码器部分,常被用于需要深层语义理解的序列转换任务。
三、Decoder(解码器)
解码器的核心功能是接收编码器输出的语义表示,按照任务需求,逐一步生成输出序列,其生成过程通常是“自回归”的——即每一步生成的输出结果,会作为下一步的输入,直至生成结束标志(如EOS)。常见的解码器结构与编码器对应,主要分为以下三类:
1.RNN/LSTM/GRU解码器
与RNN类编码器配套使用,逐时刻生成输出序列:每一步接收编码器的语义表示和上一步的输出,通过循环结构更新隐状态,再通过softmax层输出当前时刻的预测结果(如一个单词、一个语音帧)。
早期Seq2Seq模型(如机器翻译基线模型)均采用LSTM/GRU解码器,但其缺点是生成速度慢(时序迭代),且对长输出序列的语义连贯性把控较差。
2.Transformer解码器
与Transformer编码器配套使用,核心是“自注意力+交叉注意力”机制:
•自注意力机制:关注已生成的输出序列内部的依赖关系,保证输出序列的连贯性(如避免语法错误)。
•交叉注意力机制:关注编码器输出的语义表示,将输出序列与输入序列进行对齐(如机器翻译中,输出的单词对应输入的某个单词)。
典型代表是GPT系列(Decoder-only架构,本质是简化的Transformer解码器)、T5/BART的解码器部分,是当前文本生成、机器翻译等任务的核心组件。
3.专用解码器变体
针对特定任务优化的解码器,在基础结构上增加特殊机制:
•Pointer Decoder(指针解码器):增加指针机制,可直接从输入序列中“拷贝”元素(如摘要任务中拷贝原文关键词),解决生成内容与输入脱节的问题。
•Coverage Decoder(覆盖解码器):引入覆盖机制,记录解码器每一步对输入序列的关注情况,避免重复生成(如机器翻译中的重复翻译)。
四、Encoder-Decoder 工作流程(以文本翻译为例)
以“英文→中文”机器翻译任务为例,完整工作流程可分为4步,清晰体现“编码-解码”的核心逻辑:
1.输入预处理:将英文输入序列(如“I love deep learning”)转化为模型可处理的向量形式(如词嵌入向量),并补充位置编码(捕捉序列顺序)。
2.编码过程:Encoder(如Transformer编码器)逐位置处理输入向量,通过自注意力机制捕捉单词间的依赖关系(如“love”与“deep learning”的关联),最终输出全局语义表示向量。
3.解码过程:Decoder(如Transformer解码器)从语义表示向量中提取信息,采用自回归方式逐字生成中文输出序列——第一步生成“我”,第二步结合“我”和语义表示生成“爱”,第三步结合“我”“爱”生成“深度”,直至生成“我爱好深度学习”和结束标志EOS。
4.输出后处理:将解码器生成的向量序列转化为中文文本,完成翻译任务。
五、Encoder-Decoder 常见变体与延伸
随着深度学习的发展,Encoder-Decoder架构衍生出多种变体,适配不同任务场景,核心变体如下:
1.Seq2Seq 模型(最经典变体)
Seq2Seq是Encoder-Decoder架构在“序列到序列”任务中的具体实现,通常采用“RNN/LSTM/GRU+Attention”的组合(后期升级为Transformer),是机器翻译、文本摘要、对话生成等任务的基础模型。需要注意:Seq2Seq是Encoder-Decoder的特例,而非独立架构。
2.Encoder-only 架构
仅保留Encoder部分,去除Decoder,主要用于“序列理解”任务(而非序列生成),如文本分类、序列标注、情感分析等。典型代表是BERT、RoBERTa,其核心是通过编码器提取输入序列的深层语义特征,用于后续的分类或标注任务。
3.Decoder-only 架构
仅保留Decoder部分,去除Encoder,通过将输入序列作为“上下文”输入解码器,实现自回归生成。本质是隐式的Encoder-Decoder架构(输入上下文相当于编码后的语义表示),典型代表是GPT系列、Llama、Qwen等大语言模型,擅长文本生成、对话、问答等任务。
4.多模态Encoder-Decoder架构
适配跨模态序列转换任务,编码器负责处理一种模态的序列(如图像、语音),解码器负责生成另一种模态的序列(如文本、语音):
•图像→文本:如Show and Tell模型,用CNN作为编码器(提取图像特征序列),用RNN作为解码器(生成图像描述文本)。
•语音→文本:语音识别模型,用CNN/RNN作为编码器(提取语音特征序列),用Transformer解码器生成文本。
•文本→语音(TTS):用Transformer编码器处理文本序列,用卷积/循环解码器生成语音波形序列。
六、核心应用场景
Encoder-Decoder架构的应用场景均围绕“序列转换”展开,覆盖多个领域,核心场景如下:
1.自然语言处理(NLP):机器翻译、文本摘要、对话生成、语法纠错、文本改写、问答系统(如抽取式问答的编码+生成)。
2.语音处理:语音识别(语音→文本)、语音合成(文本→语音)、语音翻译(语音→语音,中间经过“语音→文本→语音”的编码解码)。
3.计算机视觉(CV):图像描述(图像→文本)、图像caption生成、视频摘要(视频帧序列→文本)。
4.时序预测:时间序列预测(如股价、气温预测),用Encoder编码历史时序序列,用Decoder生成未来时序序列(如Informer模型)。
七、优势与局限性
1.优势
•通用性强:可适配任意变长输入→变长输出的转换任务,跨领域、跨模态适用性广。
•语义捕捉能力强:通过编码器的深层处理,能有效提取输入序列的全局语义信息,保证输出的准确性。
•可扩展性强:可基于不同的基础网络(RNN、CNN、Transformer)构建,也可通过增加注意力、指针等机制优化性能。
2.局限性
•传统RNN类架构存在长距离依赖问题,对长序列(如长文本翻译)的处理效果较差(需依赖LSTM/GRU或Attention优化)。
•自回归解码速度慢:逐时刻生成输出序列,无法并行计算,难以满足实时性要求(可通过非自回归解码优化)。
•语义表示瓶颈(早期架构):传统Encoder-Decoder用固定长度的语义向量,难以承载长输入序列的全部语义信息(可通过动态语义表示、Attention机制解决)。
八、总结
Encoder-Decoder是深度学习中序列转换任务的“基础框架”,其核心价值在于将“输入理解”与“输出生成”拆分为两个独立且可优化的模块,为后续各类序列处理模型提供了统一的设计范式。从早期的RNN+Seq2Seq,到当前的Transformer+大模型,Encoder-Decoder架构不断迭代,克服了长距离依赖、生成速度等局限,成为NLP、语音、CV等领域的核心技术支撑,也是理解Seq2Seq、GPT、T5等主流模型的关键基础。