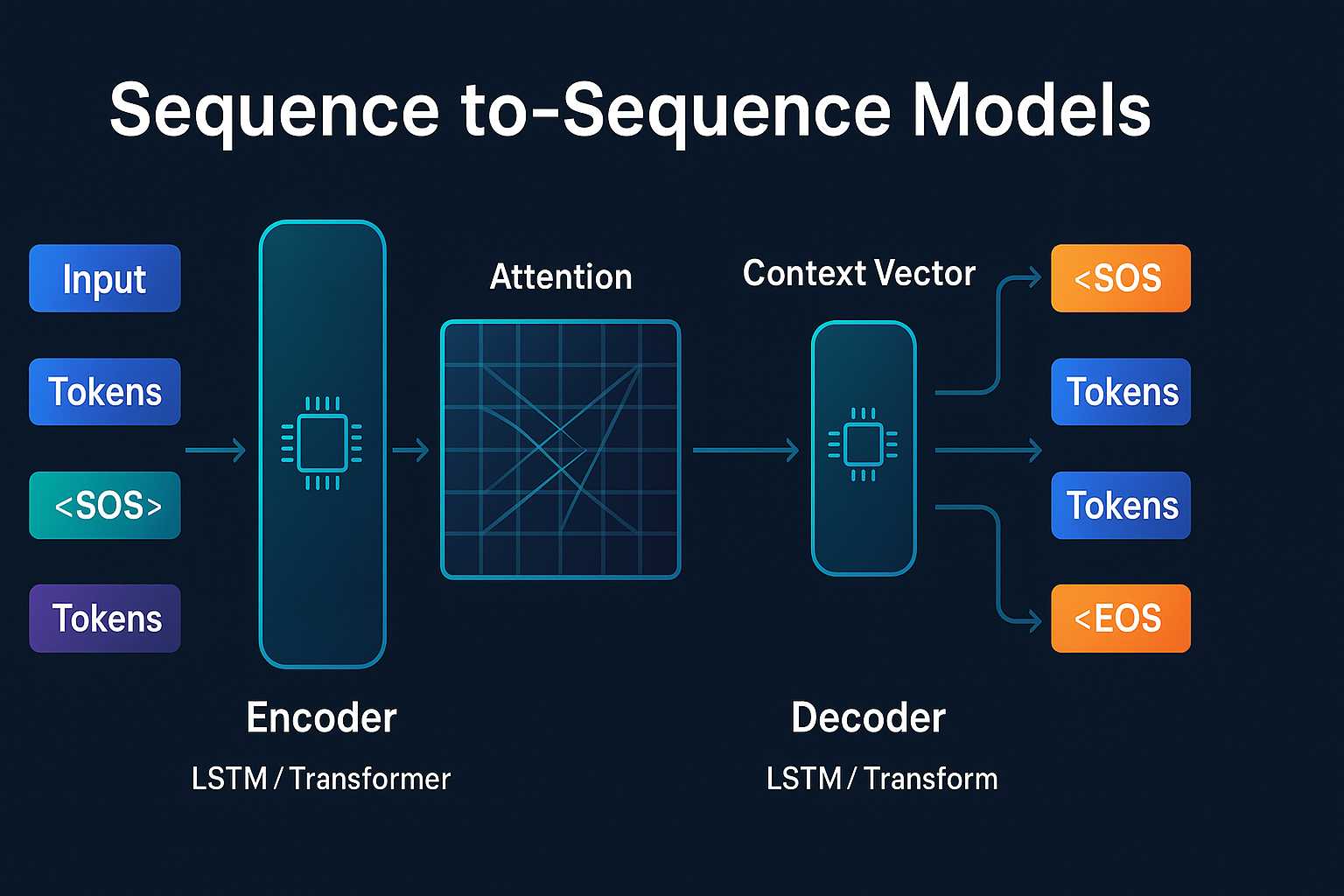
序列到序列模型(Sequence-to-Sequence, 简称Seq2Seq)是深度学习领域中专门处理序列转换任务的核心框架,其核心价值在于打破传统模型对输入、输出序列长度的限制,能够将任意长度的输入序列映射为任意长度的输出序列,实现了从“理解-分类”到“理解-生成”的范式跨越,成为自然语言处理、时序预测等领域的基础模型架构之一。
一、定义
Seq2Seq模型的本质,是解决“序列到序列”的映射问题:给定输入序列x = (x₁, x₂, …, x_Tx)(其中Tx为输入序列长度),生成输出序列y = (y₁, y₂, …, y_Ty)(其中Ty为输出序列长度)。两者长度可不同,且输入与输出的词汇表也可存在差异,典型应用如机器翻译(不同语言的序列转换)。
其核心思想通过“编码-解码”两步实现序列转换:首先由编码器(Encoder)读取输入序列,将其语义信息压缩为统一的特征表示(即上下文向量);再由解码器(Decoder)基于该上下文向量,逐元素自回归生成目标输出序列。整个过程采用端到端训练方式,无需手动设计特征工程,可自动学习输入与输出的映射关系。
二、架构
Seq2Seq模型的基础架构由编码器和解码器两部分组成,二者最初多采用循环神经网络(RNN)及其变体(LSTM、GRU)实现,后续随着技术演进,逐步采用Transformer架构作为核心组件,大幅提升模型性能。
(一)编码器(Encoder)
编码器的核心任务,是将变长的输入序列编码为固定长度的上下文向量,该向量需完整承载输入序列的全部语义信息,为解码器生成输出提供核心依据。
传统编码器多由多层LSTM或GRU组成,工作流程如下:按时间步依次读入输入序列的词嵌入(将离散词汇转换为连续向量),不断更新内部隐藏状态;输入序列处理完毕后,上下文向量通常取最后一个时间步的隐藏状态(若为双向LSTM,则取前向与后向最后隐藏状态的拼接)。
基于Transformer的编码器结构更为复杂,由6个相同的层堆叠而成,每层包含两个子层:多头自注意力机制(Multi-Head Self-Attention)和前馈网络。每个子层均添加残差连接和层归一化,能更好地捕捉输入序列的长程依赖关系;同时通过位置编码(Positional Encoding)注入序列的位置信息,解决注意力机制无法感知序列顺序的问题,位置编码的具体公式如下:
1.位置编码公式(正弦项):PE(pos, 2i) = sin( pos ÷ 1000的(2i/d_model)次方 )
2.位置编码公式(余弦项):PE(pos, 2i+1) = cos( pos ÷ 1000的(2i/d_model)次方 )
说明:pos代表序列中的位置,i代表编码维度的索引,d_model代表模型的维度;公式中“1000的(2i/d_model)次方”即1000^(2i/d_model),位置编码与词嵌入维度一致,可直接相加融合,确保模型捕捉序列顺序信息。
(二)解码器(Decoder)
解码器的核心任务,是基于编码器输出的上下文向量,自回归生成目标输出序列——即每个时间步的输出,会作为下一个时间步的输入,直至生成终止符号(如)。
传统解码器同样采用LSTM或GRU结构,其初始隐藏状态由编码器输出的上下文向量初始化;训练阶段,为加速模型收敛,通常采用“教师强制”(Teacher Forcing)方式:解码器每个时间步接收前一个真实目标词作为输入,而非自身的预测结果,通过softmax函数输出当前目标词的概率分布,损失函数采用交叉熵损失,衡量预测序列与真实序列的差异。
基于Transformer的解码器也由6个相同的层堆叠而成,每层包含三个子层:带掩码的多头自注意力子层(防止解码器关注未来时间步的信息)、多头交叉注意力子层(关注编码器输出的上下文向量)和前馈网络子层。各子层均配备残差连接和层归一化,最终通过线性层和softmax层输出预测结果。
三、注意力机制(Attention Mechanism)
传统Seq2Seq模型存在一个致命缺陷——信息瓶颈:编码器输出的固定长度上下文向量,需承载输入序列的全部语义信息,当输入序列较长(如长文本翻译)时,极易导致信息丢失,使得解码器无法精准捕捉输入序列的关键细节,进而降低模型性能。
注意力机制的出现,完美解决了这一问题。其核心思想类比人类视觉系统,将有限的认知资源聚焦于输入序列的关键部分:解码器在生成每个输出词时,会动态回顾输入序列的不同片段,为每个片段赋予不同的关注权重(权重之和为1),再基于权重对编码器的隐藏状态进行加权求和,得到动态的上下文向量,彻底打破了固定长度上下文向量的束缚。
注意力机制的核心工作流程如下:
1.计算相似度:计算解码器当前隐藏状态与编码器各时间步隐藏状态之间的相似度(得分);
2.生成权重:通过softmax函数将相似度得分转换为注意力权重,体现输入序列各部分的重要程度;
3.生成上下文向量:根据注意力权重,对编码器的隐藏状态进行加权求和,得到动态上下文向量;
4.生成输出:将动态上下文向量与解码器当前状态结合,生成当前时间步的输出。
常见的注意力机制变体包括全局注意力、局部注意力、交叉注意力和自注意力,其中自注意力是Transformer架构的核心,能够直接捕捉输入序列内部的依赖关系,进一步提升模型对长序列的处理能力。
四、训练与推理过程
(一)训练过程
Seq2Seq模型采用端到端训练方式,核心目标是优化模型参数,使生成的序列尽可能接近真实序列,具体流程如下:
1.数据预处理:对输入序列和目标序列进行分词、编码(转换为token_id)、填充或截断,确保符合模型输入要求;
2.编码阶段:编码器处理输入序列,输出上下文向量;
3.解码阶段:采用“教师强制”方式,解码器接收真实目标序列的前一个词作为输入,生成当前词的概率分布;
4.损失计算与参数更新:通过交叉熵损失(分类任务)或均方误差(时序预测任务),计算预测值与真实值的差异,利用梯度下降算法更新模型参数,反复迭代直至模型收敛。
(二)推理过程
推理阶段无法使用“教师强制”方式,解码器需自回归生成输出序列,常见的解码策略有两种:
1.贪心搜索:每个时间步选择概率最高的词作为当前输出,计算简单但易陷入局部最优,可能导致生成序列不连贯;
2.束搜索(Beam Search):每个时间步保留B个最优候选序列(束宽),后续基于这些候选序列继续生成,在搜索空间与计算开销之间取得平衡,是实际应用中更常用的策略。
五、应用场景
Seq2Seq模型凭借灵活处理变长序列、融合多源信息的能力,在多个领域得到广泛应用,涵盖自然语言处理、时序预测、语音处理等多个方向,典型应用场景如下:
1.自然语言处理(NLP)
•机器翻译:将一种语言的序列转换为另一种语言的序列(如英文转中文),是Seq2Seq模型最经典的应用场景;
•文本摘要:将长文本序列压缩为简洁的短文本序列,自动提取核心信息,降低阅读成本;
•对话生成:根据用户输入的对话序列,生成符合语境的回复序列,应用于智能客服、聊天机器人等;
•代码生成:将自然语言描述的需求,转换为对应的代码序列,提升开发效率;
•问答系统:根据问题序列和上下文序列,生成准确的答案序列,实现智能问答。
2.时序预测
Seq2Seq模型可将历史时序数据作为输入序列,生成未来的时序预测序列,广泛应用于能源电力、金融、零售、物联网等领域:
•能源电力领域:基于历史负荷数据、温度等信息,预测未来24小时至一周的电力负荷曲线,优化电力调度;
•金融领域:处理股票价格、交易量等时序数据,预测未来价格走势或波动率,为投资决策提供参考;
•零售与供应链领域:融合历史销量、促销活动等信息,预测未来多个SKU的销量,指导库存优化;
•物联网与工业维护:基于传感器采集的振动、温度等序列数据,预测设备未来的健康状态,实现预测性维护。
3.其他领域
•语音识别:将音频特征序列转换为文本序列,实现语音到文字的转换;
•图像描述:将图像特征序列转换为文字描述序列,实现图像内容的文字化表达;
•多变量融合任务:整合多个相关时序变量(如股票的开盘价、最高价、成交量),生成多变量联合预测序列。
六、优势与局限
1.核心优势
•灵活适配:天然支持输入与输出序列长度可变,可适应不同类型的序列转换任务,兼容性强;
•整体优化:直接对多步预测序列进行联合优化,建模输出步之间的依赖关系,避免迭代预测的误差传播;
•表征能力强:深度学习架构可自动从数据中学习复杂模式和高级特征,无需手动设计特征工程,降低人工成本;
•信息融合能力强:易于整合多源异构数据(多变量时序、静态特征、已知未来信息),构建统一的处理框架。
2.主要局限
•长序列处理不足:传统基于RNN的Seq2Seq模型难以捕捉长序列的依赖关系,即便引入注意力机制,仍存在计算复杂度较高的问题;
•可解释性差:深度学习架构的“黑箱”特性,使得模型生成输出的决策过程难以解释,无法明确说明输出与输入的关联逻辑;
•推理效率较低:自回归生成方式导致输出序列的生成速度较慢,难以满足实时性要求较高的场景;
•训练成本高:尤其是基于Transformer的Seq2Seq模型,需要大量的训练数据和计算资源,训练周期较长。
七、演进
Seq2Seq模型自2014年由Cho等人首次在RNN中提出以来,经历了多轮技术迭代,核心演进路径如下:
1.初代模型:基于RNN的Encoder-Decoder架构,解决了变长序列转换的核心问题,但存在长序列信息丢失、梯度消失等缺陷;
2.优化升级:采用LSTM、GRU替代传统RNN,缓解梯度消失问题;引入注意力机制,打破信息瓶颈,提升长序列处理能力;
3.范式革新:2017年《Attention Is All You Need》论文提出Transformer架构,完全基于注意力机制构建编码器和解码器,摆脱RNN的时序依赖,实现并行计算,大幅提升模型训练效率和长序列处理能力;
4.当前发展:基于Transformer的Seq2Seq模型衍生出众多变体(如BERT、GPT系列模型),结合预训练-微调范式,在各类序列任务中实现性能突破,同时朝着多模态融合、小样本学习、可解释性提升等方向持续发展。
八、总结
Seq2Seq模型以“编码-解码”为核心架构,以注意力机制为关键优化手段,实现了变长序列的灵活转换,成为连接输入与输出、实现“理解-生成”的核心工具。其应用场景覆盖自然语言处理、时序预测等多个领域,为智能生成、预测决策提供了强大支撑。尽管目前仍存在长序列处理、可解释性、推理效率等方面的局限,但随着与Transformer、预训练等技术的深度融合,Seq2Seq模型的应用边界将不断拓展,在更多复杂场景中发挥重要作用。