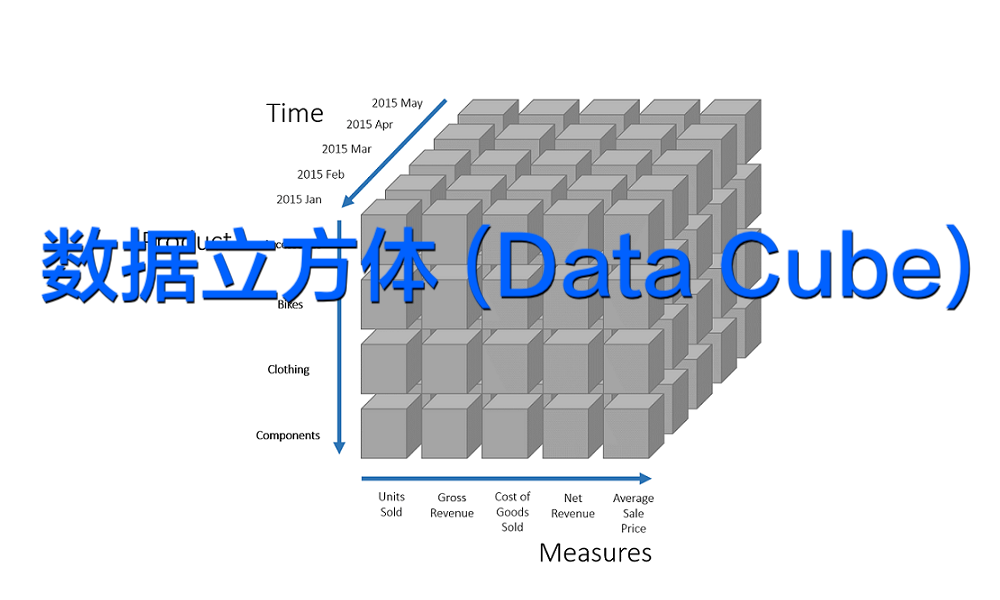
数据立方体(Data Cube),简称 Cube,是 OLAP(联机分析处理)技术的核心数据存储与分析结构,本质是一种多维数据模型的物理或逻辑实现,用于将分散的、二维的关系型数据,组织成多维度的结构化形式,支撑快速、灵活的多维分析操作(如切片、切块、钻取、旋转),解决传统二维表格难以应对的复杂商业查询问题。
简单来说,数据立方体就像一个“多维度的魔方”,每个维度对应魔方的一个面,维度的不同组合对应魔方的不同状态,而魔方的每个“小块”,就是一个具体的聚合数据值,能让分析师从多个角度(维度)快速定位、查看和分析核心指标(度量)。
一、定义
数据立方体的核心是“多维聚合”,它并非字面意义上的“立方体”(仅3个维度),而是可以包含 n个维度(n≥1)的多维数据结构,官方定义为:将数据按照“维度+度量”的模式,进行预先计算和存储,形成的多维度、多层次的聚合数据集合。
其本质是对原始业务数据的“预计算缓存” ——OLAP系统会提前对原始数据(来自OLTP数据库、数据仓库等)进行聚合计算(如求和、计数、平均值、最大值等),将计算结果存储在Cube中,当用户发起多维查询时,无需重新扫描海量原始数据,只需从Cube中提取预计算好的结果,从而实现“秒级响应”。
补充:与传统二维表格(仅行和列两个维度)相比,数据立方体的核心优势的是“维度可扩展”和“查询高效性”,例如:分析“销售额”时,可同时结合“时间、地区、产品、渠道”4个维度,而无需多次关联多张二维表格。
二、维度、度量与层级
数据立方体的结构由“维度”“度量”和“维度层级”三部分组成,三者相互关联,构成完整的多维分析体系,也是理解Cube的关键。
(一)维度(Dimension)
维度是“观察数据的角度或视角”,是数据立方体的“骨架”,用于对数据进行分类、筛选和分组。每个维度都包含若干个“维度成员”(即该维度下的具体取值),且支持多层级划分。
常见维度及示例:
•时间维度:成员为年、季、月、日(层级:年→季→月→日);
•地区维度:成员为国家、省份、城市、区县(层级:国家→省份→城市);
•产品维度:成员为品类、品牌、型号(层级:品类→品牌→型号);
•用户维度:成员为性别、年龄组、用户等级(层级:用户等级→年龄组→性别)。
维度的数量决定了Cube的“维度数”,例如:3个维度(时间、地区、产品)构成3维Cube,4个维度(增加渠道)构成4维Cube,理论上维度数可无限扩展,但维度过多会导致“维度爆炸”。
(二)度量(Measure)
度量是“要分析的核心数值指标”,是数据立方体的“血肉”,也是用户最终关注的分析结果,通常是可聚合的数值型数据。
常见度量及示例:
•业务指标:销售额、利润、销量、订单数、用户数;
•统计指标:平均客单价、转化率、库存周转率、同比增长率;
•计算指标:毛利率(利润/销售额)、复购率(复购用户数/总用户数)。
度量分为两种类型:
1.可加性度量:可在不同维度上直接求和(如销售额、销量),是最常用的度量类型;
2.非可加性度量:无法直接求和,需通过特殊计算得到(如平均客单价、转化率),Cube中会存储其计算所需的基础数据(如总销售额、总订单数),查询时实时计算。
(三)维度层级(Dimension Hierarchy)
维度层级是“维度成员的上下级关系”,用于支持“钻取”操作(下钻查看明细、上卷查看汇总),是Cube实现多层次分析的核心。
示例:时间维度的层级为“年→季→月→日”,当用户查看“2025年销售额”(上卷)时,Cube返回2025年4个季度的销售额总和;当用户下钻到“2025年Q1”时,返回Q1三个月的销售额明细,无需重新计算,直接调用预存的层级聚合数据。
三、预聚合与查询响应
数据立方体的高效性,核心在于“预聚合”机制,其工作流程分为两个阶段:数据加载阶段(预聚合)和查询响应阶段(提取预计算结果)。
(一)第一阶段:数据加载与预聚合
1.数据抽取:从OLTP数据库、数据仓库等数据源,抽取原始业务数据(如订单表、用户表、产品表);
2.数据清洗与转换:对原始数据进行去重、补全、格式统一,将二维数据转换为“维度+度量”的结构;
3.预聚合计算:按照所有维度的所有层级组合,提前计算度量值(如求和、计数),并将结果存储在Cube中。例如:3个维度(时间、地区、产品),每个维度有3个层级,会生成3×3×3=27种聚合组合,每种组合对应一个具体的度量值;
4.Cube存储:将预聚合数据按照多维结构存储(不同OLAP类型的存储方式不同),形成完整的数据立方体。
(二)第二阶段:查询响应
当用户发起多维查询(如“查询2025年Q1华东地区A产品的销售额”)时,OLAP系统的处理流程如下:
1.解析查询:提取查询中的维度(时间:2025年Q1、地区:华东、产品:A产品)和度量(销售额);
2.定位Cube中的聚合数据:根据解析后的维度组合,快速定位到Cube中对应的预聚合结果,无需扫描原始数据;
3.返回结果:将定位到的聚合数据整理后,返回给用户,整个过程通常在秒级完成。
补充:预聚合是Cube的核心优势,但也存在“更新延迟”的问题——当原始业务数据发生变化(如新增订单、修改销量)时,需要重新计算相关的聚合数据,更新Cube,因此Cube更适合“历史数据的分析”,而非“实时数据的查询”(实时分析通常用OLTP或实时OLAP技术)。
四、数据立方体的存储分类
根据存储方式和预聚合策略的不同,数据立方体主要分为3类,对应OLAP的三种类型(MOLAP、ROLAP、HOLAP),核心差异在于“预聚合数据的存储位置和方式”。
(一)MOLAP Cube(多维OLAP立方体)
这是最经典、最纯粹的数据立方体,采用“多维数组”的方式直接存储预聚合数据,与数据源(关系型数据库)完全分离。
•优点:查询速度最快(直接读取预聚合的多维数组,无需计算)、数据压缩率高、支持复杂的多维分析操作;
•缺点:数据更新慢(原始数据变化后,需重新计算整个Cube或相关维度的聚合数据)、维度过多时易出现“维度爆炸”(存储量急剧增加)、不支持大量明细数据存储;
•代表产品:Essbase、Apache Kylin、Microsoft SSAS(多维模式)。
(二)ROLAP Cube(关系OLAP立方体)
ROLAP Cube不单独存储多维数据,而是基于关系型数据库(如Oracle、MySQL),用“星型模型”或“雪花模型”模拟多维结构,预聚合数据存储在关系表中(称为“聚合表”)。
•优点:灵活性高(支持任意维度组合查询)、支持海量明细数据、数据更新快(只需更新聚合表,无需重新构建整个Cube)、易与现有关系型数据库集成;
•缺点:查询速度比MOLAP慢(需通过SQL查询聚合表,复杂查询需关联多张表)、预聚合策略复杂(需手动设计聚合表的维度组合);
•代表产品:Oracle OLAP、Teradata、Microsoft SSAS(关系模式)。
(三)HOLAP Cube(混合OLAP立方体)
结合MOLAP和ROLAP的优势,采用“混合存储”策略:常用的、高频查询的聚合数据(如高层级汇总数据)用MOLAP方式存储(多维数组),低频查询的明细数据和特殊维度组合数据用ROLAP方式存储(关系表)。
•优点:兼顾查询速度和灵活性,既解决了MOLAP更新慢、明细不足的问题,也解决了ROLAP查询慢的问题;
•缺点:架构复杂(需同时维护MOLAP和ROLAP存储)、配置和优化难度高;
•代表产品:IBM Cognos、SAP BW。
五、核心问题:维度爆炸(Dimension Explosion)
维度爆炸是数据立方体设计和使用中最常见的问题,指当维度数量或维度成员过多时,Cube的存储量会呈指数级增长,导致存储成本上升、更新速度变慢、查询效率下降。
1.产生原因
Cube的存储量 = 所有维度的成员数量的乘积 × 度量数量。例如:
•3个维度,每个维度有10个成员,1个度量:存储量 = 10×10×10×1 = 1000;
•5个维度,每个维度有10个成员,1个度量:存储量 = 10×10×10×10×10×1 = 100000(增长100倍);
•若维度增加到10个,每个维度10个成员,存储量将达到10¹⁰,远超普通存储设备的承载能力。
2.解决方法
1)维度筛选:删除无关、冗余的维度(如“用户ID”这类无法聚合的明细维度,无需放入Cube);
2)维度分层与合并:将相似维度合并(如“省份”和“城市”合并为“地区维度”),或删除低价值的维度层级;
3)稀疏Cube技术:只存储有实际数据的维度组合(大部分维度组合是无数据的,如“北京的冬季羽绒服销量”有数据,“海南的冬季羽绒服销量”无数据,可不存储);
4)动态聚合:不预计算所有维度组合,仅预计算高频查询的组合,低频组合在查询时实时计算;
5)分区存储:按核心维度(如时间)对Cube进行分区(如按年分区),查询时只加载相关分区的数据,减少数据扫描量。
六、应用场景
数据立方体主要用于“海量历史数据的多维分析”,核心场景集中在商业决策、业务监控、报表生成等领域,常见应用如下:
1.销售分析:通过“时间+地区+产品+渠道”多维Cube,分析不同维度组合下的销售额、利润、销量,定位热销产品、优势区域;
2.财务分析:构建“时间+部门+科目”Cube,分析各部门、各科目在不同时间段的支出、收入、利润,支撑预算管控和财务决策;
3.运营分析:构建“时间+用户+行为+渠道”Cube,分析用户留存、转化率、活跃度,优化运营策略;
4.供应链分析:构建“时间+供应商+产品+仓库”Cube,分析库存周转、物流效率、供应商绩效,优化供应链布局;
5.BI报表与大屏可视化:作为BI工具(如Tableau、Power BI)的核心数据源,快速生成多维报表、可视化大屏,支撑管理者实时查看业务数据。
七、与其他数据结构的区别
(一)Cube vs 二维表格(关系表)
•二维表格:仅支持行、列两个维度,查询复杂多维数据时需多次关联表格,效率低;
•Cube:支持n个维度,预聚合数据,查询速度快,可直接实现切片、钻取等多维操作。
(二)Cube vs 数据仓库
•数据仓库:是“面向主题的、集成的、稳定的、随时间变化的”数据集合,存储的是原始明细数据和基础聚合数据,是Cube的数据源;
•Cube:是在数据仓库的基础上,对数据进行进一步的多维预聚合,专注于“快速多维查询”,是数据仓库的“分析延伸”。
(三)Cube vs 数据集市
•数据集市:是面向特定业务部门(如销售部、财务部)的小型数据仓库,存储的是该部门相关的明细数据和简单聚合数据;
•Cube:可基于数据集市构建,专注于该部门的多维分析,比数据集市的查询效率更高、分析维度更灵活。
八、总结
数据立方体是OLAP技术的核心,其核心价值在于“将多维分析从‘复杂计算’转化为‘快速查询’”——通过预聚合机制,将海量原始数据转化为结构化的多维聚合数据,让分析师和管理者能从多个角度、多个层级快速挖掘数据价值,支撑商业决策。
其核心特点是“多维、高效、交互”,但同时也面临“维度爆炸”“更新延迟”等问题,实际应用中需结合业务场景,选择合适的Cube类型(MOLAP/ROLAP/HOLAP),并通过维度优化、分区存储等方式,平衡查询效率、存储成本和数据新鲜度。