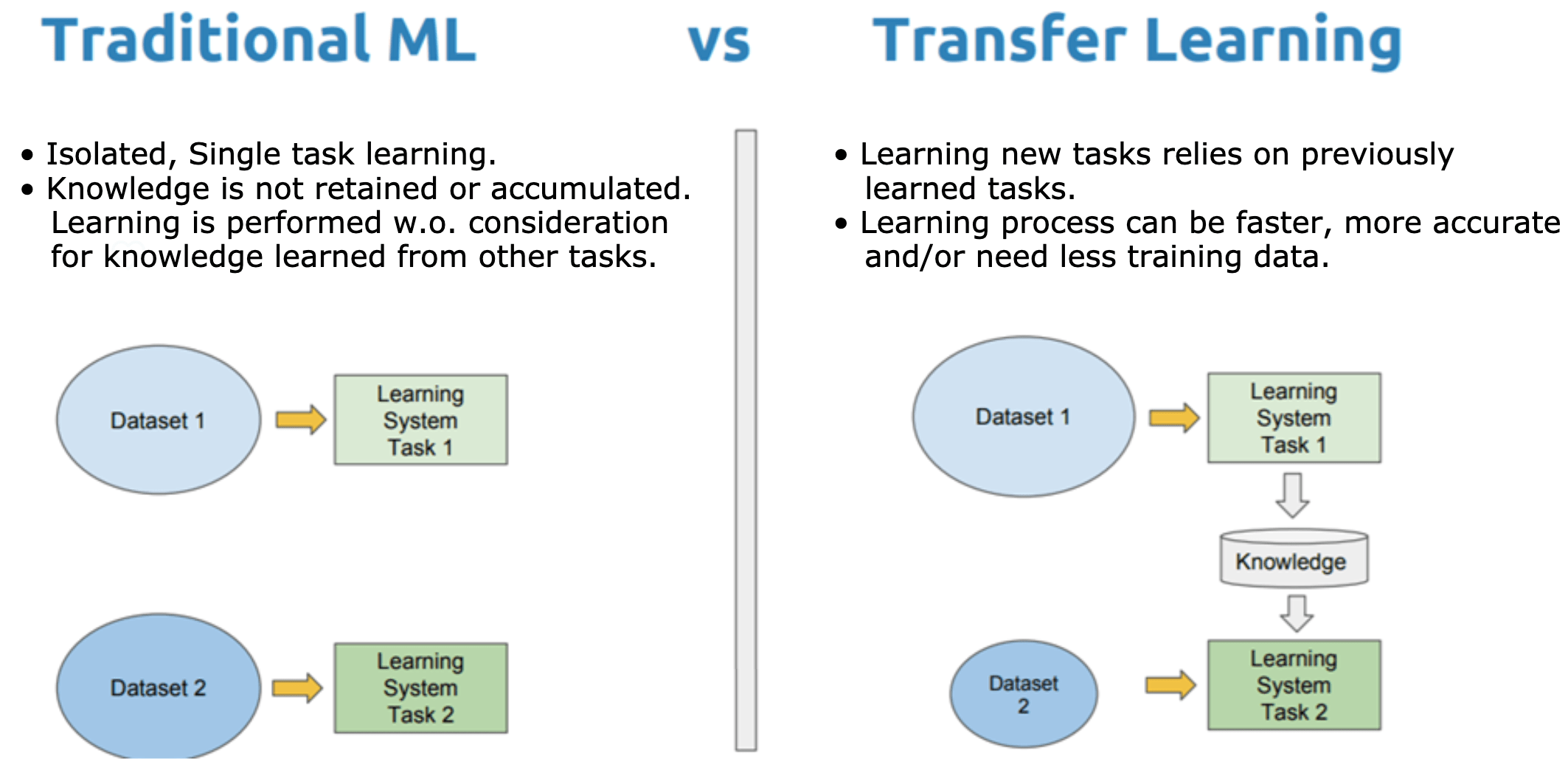
在人工智能与机器学习的发展历程中,传统机器学习与迁移学习是两类具有里程碑意义的技术范式。前者构建了机器学习的基础框架,后者则打破了传统模式的局限,成为解决数据稀缺、降低训练成本的核心技术。本文将从核心定义、核心差异、适用场景、典型案例及未来趋势五个维度,系统剖析二者的区别与联系,为技术选型提供参考。
一、核心定义
1.传统机器学习(Traditional Machine Learning)
传统机器学习是一类通过算法让计算机从特定任务的标注数据中自主学习规律,进而对未知数据进行预测或决策的技术。其核心逻辑是“为单一任务定制学习模型”,即针对每个新任务,都需要重新收集足量标注数据、设计特征工程,并训练全新的模型。模型的学习过程局限于当前任务的数据集,无法利用其他任务的知识经验,学习结果也仅适用于当前任务场景。
例如,用传统机器学习构建“猫识别模型”时,需专门收集大量猫的标注图片,训练出的模型仅能完成猫的识别,若要实现“狗识别”,则需重新进行数据收集与模型训练。
2.迁移学习(Transfer Learning)
迁移学习是一种基于“知识复用”的机器学习范式,其核心目标是将从源任务(Source Task)中学习到的知识和经验,迁移到与源任务相关但不同的目标任务(Target Task)中,从而帮助目标任务在数据不足、标注成本高的情况下,快速构建高性能模型。
迁移学习打破了“一次学习仅针对一个任务”的限制,认为不同任务之间存在可复用的共性知识(如图像识别中的边缘检测、纹理特征,自然语言处理中的语法规则)。通过迁移这些共性知识,目标任务无需从零开始训练,只需在源任务模型的基础上进行微调(Fine-tuning)即可达到理想效果。例如,将在“ImageNet数据集(含数千类物体)”上训练好的ResNet模型,迁移到“医学影像肿瘤识别”任务中,仅需用少量医学影像数据微调模型,就能实现高精度识别。
二、核心差异
传统机器学习与迁移学习的差异贯穿于数据依赖、训练模式、特征工程、模型泛化等多个核心环节。在数据依赖方面,传统机器学习依赖大量标注数据,且数据需与目标任务高度匹配,数据稀缺时模型性能会急剧下降;而迁移学习的目标任务仅需少量标注数据,其核心依赖源任务的海量数据,通过源任务数据弥补目标任务数据不足的问题。
在任务关联性要求上,传统机器学习中各任务相互独立,每个任务的模型都与其他任务无关,不考虑任务间的知识复用;迁移学习则核心依赖源任务与目标任务的关联性,诸如语义关联、特征关联等,且二者关联性越强,迁移效果越好。训练模式上,传统机器学习采用“从零开始训练”的方式,针对目标任务设计模型结构后,用目标任务数据从头训练参数;迁移学习则遵循“先预训练后微调”的逻辑,先在源任务上训练出包含通用知识的预训练模型,再用目标任务数据对模型参数进行微调。
特征工程环节,传统机器学习依赖人工设计特征,需要针对目标任务的特点定制特征提取规则,不仅成本高,还高度依赖领域经验;迁移学习的预训练模型已从源任务中学习到通用特征,如图像的轮廓、文本的语义等,因此目标任务无需或少需人工设计特征。训练效率方面,传统机器学习每次面对新任务都需完整训练,训练周期长,计算资源消耗大,尤其是深度学习模型;迁移学习仅需微调预训练模型,训练参数少、周期短,计算资源消耗仅为传统模式的10%-30%。
模型泛化能力上,传统机器学习的泛化能力局限于目标任务的数据集分布,若数据分布发生变化,如光照变化、语境变化,模型性能易下降;迁移学习的预训练模型因学习了通用知识,对目标任务的分布变化适应性更强,泛化能力更优。核心风险方面,传统机器学习的风险主要包括过拟合(数据量不足时)、欠拟合(模型复杂度不够时)以及特征设计不合理导致的性能瓶颈;迁移学习的核心风险则是负迁移,即若源任务与目标任务关联性弱,迁移的知识会干扰目标任务学习,导致性能下降。
三、适用场景
二者的适用场景差异本质上是“数据可用性”与“任务关联性”的匹配问题,具体适用场景如下:
1.传统机器学习的适用场景
•数据充足且易标注的场景:如电商平台的商品分类(有大量标注商品图片)、金融领域的信用评分(有海量用户交易数据)。
•任务独立且特殊化的场景:如某企业内部的定制化数据统计任务,任务与外部通用任务关联性弱,无需知识迁移。
•模型复杂度低的场景:如简单的线性回归预测(如房价预测)、决策树分类(如客户流失预测),这类任务无需复杂的预训练模型支持。
2.迁移学习的适用场景
•目标任务数据稀缺或标注成本高的场景:如医学影像诊断(高质量标注影像少)、自动驾驶场景识别(特殊天气数据难获取)。
•任务具有关联性的通用场景:如自然语言处理中的情感分析(可迁移通用语言模型知识)、计算机视觉中的人脸识别(可迁移通用图像特征提取能力)。
•快速迭代的任务场景:如短视频平台的实时内容分类,需快速适配新的内容类型,迁移学习可缩短模型上线周期。
四、典型案例
1.传统机器学习案例:垃圾邮件分类
早期垃圾邮件分类多采用传统机器学习方法:收集大量标注的“垃圾邮件”与“正常邮件”数据,人工提取邮件中的关键词频率、发送地址特征等,训练朴素贝叶斯或SVM模型。该模型仅针对“邮件分类”任务设计,若要迁移到“短信垃圾识别”,则需重新收集短信数据并训练新模型。
2.迁移学习案例:BERT模型在行业文本分析中的应用
BERT模型是在海量通用文本(如维基百科、书籍语料)上预训练的自然语言处理模型,已学习到通用的语法规则和语义理解能力。某金融机构需构建“金融新闻情感分析”模型时,无需从头训练:直接使用BERT作为基础模型,用少量标注的金融新闻数据微调模型参数,即可快速实现对金融术语(如“降息”“涨停”)的精准情感判断,模型准确率较传统方法提升30%以上,训练周期缩短80%。
五、未来趋势
传统机器学习与迁移学习并非对立关系,而是互补共存的技术体系。未来,二者的融合将成为主流趋势:
1.传统机器学习为迁移学习提供基础:迁移学习的预训练模型本质上仍是基于传统机器学习算法(如神经网络)构建,传统算法的优化(如损失函数改进)将直接提升迁移学习的效果。
2.迁移学习拓展传统机器学习的边界:在数据稀缺的特殊领域(如航天、深海探测),迁移学习可帮助传统机器学习突破数据瓶颈,实现技术落地。
3.自适应迁移学习成为新方向:未来的模型将具备“自主判断任务关联性”的能力,避免负迁移风险,同时结合传统机器学习的任务定制化优势,实现“通用知识+定制化学习”的高效融合。
六、总结
传统机器学习是“专一化的从零学习”,依赖充足数据和人工设计,适用于简单、数据充足的任务;迁移学习是“通用化的知识复用”,通过预训练与微调打破数据限制,适用于复杂、数据稀缺的场景。在实际技术选型中,需结合任务的“数据量”“任务关联性”“迭代需求”等因素综合判断——既不盲目追求迁移学习的高效,也不忽视传统机器学习在特定场景的简洁性,二者的合理搭配将最大化发挥机器学习的价值。