当人工智能从单一模态的\"专精\"走向多模态的\"通识\",DeepMind提出的Flamingo系列模型以其突破性的架构设计,重新定义了视觉-语言交互的技术范式。作为专注于少样本学习的多模态巨头,Flamingo打破了传统模型对大规模标注数据的依赖,通过精巧的跨模态融合机制,实现了图像、视频与文本的深度协同推理,为多模态人工智能的实用化进程奠定了重要基石。
一、模型起源与核心定位
Flamingo的诞生源于多模态机器学习领域的核心挑战:如何让模型仅通过少量标注示例就能快速适配全新任务。在2022年NeurIPS会议上,DeepMind正式公布这一视觉语言模型(VLM)家族,其设计理念植根于大型语言模型(LLM)在少样本学习中的成功经验,并将这种能力拓展到视觉与语言的交叉领域。
与需要针对特定任务微调的传统模型不同,Flamingo的核心定位是\"通用多模态推理器\":它能够处理\"文本-图像-文本-视频\"等任意交错的输入序列,通过上下文学习(In-Context Learning)机制,仅需数十个任务示例即可在视觉问答、图像描述等多种任务中达到 state-of-the-art 性能,甚至超越那些使用数千倍任务特定数据微调的模型。这种灵活性使其能够无缝适配开放域与专业域的各类多模态需求。
二、突破性架构设计
Flamingo的卓越性能源于其四大核心架构创新,这些设计既保留了预训练模型的既有知识,又实现了跨模态信息的高效融合。
1.双冻结模型+桥接模块的融合架构
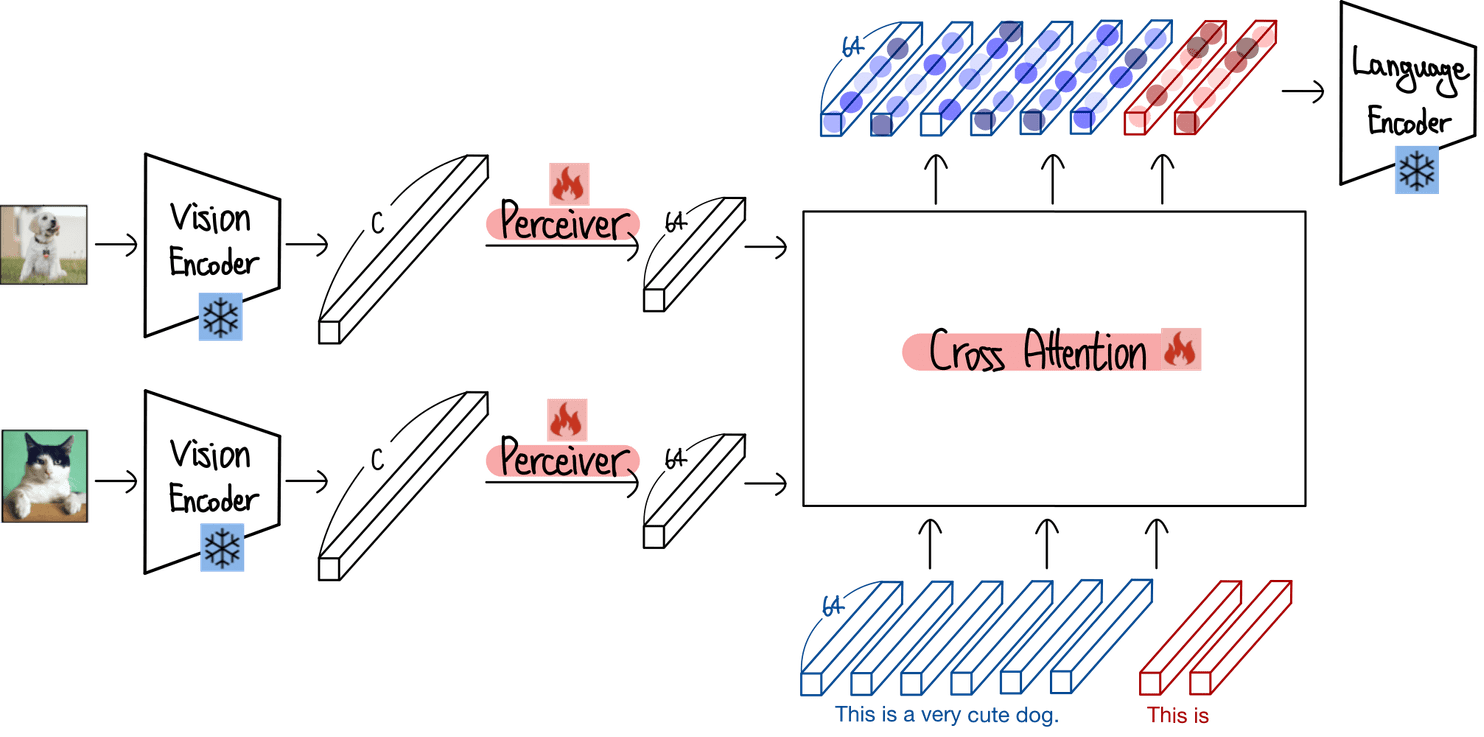
Flamingo创新性地采用\"冻结预训练模型+可训练桥接模块\"的混合架构,有效避免了多模态训练中的\"灾难性遗忘\"问题:
冻结视觉编码器:采用经对比学习预训练的Normalizer-Free ResNet(NFNet-F6),负责将图像或视频帧转换为时空特征。对于视频输入,模型以1 FPS速率采样帧,独立编码后拼接为三维特征网格并添加时间嵌入。
冻结语言模型:基于Chinchilla(70B参数)或Gopher(280B参数)等强大LLM,保留其在海量文本上习得的语言理解与生成能力,仅对新增模块进行训练。
感知器重采样器(Perceiver Resampler):作为连接视觉与语言模型的关键桥梁,它将视觉编码器输出的可变长高维特征(如H×W×C)通过交叉注意力计算压缩为固定长度的64个视觉Token,大幅降低了跨模态交互的计算复杂度。其核心公式可表示为:Ṽ = PerceiverResampler(V) = CrossAttention(Q, K, V),其中Q为可学习查询向量,K和V为视觉特征。
2.门控交叉注意力机制
为实现视觉信息的精准注入,Flamingo在LLM的Transformer层间插入了门控交叉注意力-稠密层(Gated XATTN-DENSE),这一模块的设计兼具稳定性与灵活性:
初始状态下,可学习门控权重σ(β)被初始化为0,确保模型行为与原始纯语言模型一致,保障训练稳定性。
训练过程中,门控值随任务需求动态调整,深层Transformer层的门控值更大,允许高层语义更灵活地融合视觉特征。
其核心计算逻辑为:GCA(Q, K, V) = LayerNorm(Q + σ(β) ⊙ CrossAttention(Q, K, V)),通过门控权重精确控制视觉信息对语言生成的影响程度。
3.图文交错序列处理机制
针对真实世界中图文交织的信息呈现模式,Flamingo设计了独特的序列处理策略:
使用特殊标记标识视觉输入,使模型能够处理任意顺序的\"文本-视觉\"混合序列。
通过因果掩码机制实现选择性注意力:文本Token仅关注紧邻其前的视觉内容,同时通过语言模型的自注意力传播对所有先前视觉输入的依赖性,既保证了局部关联的准确性,又兼顾了全局上下文的连贯性。
4.大规模多模态数据训练体系
数据是Flamingo能力的基础,其训练数据集涵盖三大核心来源,总规模超380M样本:
M3W(MultiModal MassiveWeb):从43M网页中提取的图文交错序列,包含1.85亿图像和182GB文本,真实还原网页中的信息呈现模式。
LTIP(Long Text & Image Pairs):312M高质量图文对,平均描述长度20.5个Token,覆盖复杂场景的详细描述需求。
VTP(Video & Text Pairs):27M短视频-文本对,支撑视频理解能力的构建。
为增强模型泛化性,训练中采用动态掩码策略:以50%概率让文本关注下一张图而非上一张,模拟网页中图文关系的不确定性。
三、核心能力与性能表现
Flamingo的能力体系围绕\"少样本多模态推理\"展开,在各类基准测试中展现出压倒性优势。
1.少样本学习能力
通过上下文学习机制,Flamingo仅需32个任务示例即可在16个多模态基准上超越微调模型。在视觉问答(VQA)任务中,其准确率较传统微调模型提升7.3%;在图像描述任务中,能够生成更贴合场景细节与上下文逻辑的文本内容。这种能力源于其对条件概率p(y|x)的直接建模,其中x为交错的图文序列,y为文本输出,无需任何任务特定调整。
2.跨模态理解与生成
Flamingo实现了从\"感知\"到\"认知\"的跨模态跃迁:
图像理解:不仅能识别物体、场景等基础视觉元素,还能解读图像中的情感倾向、逻辑关系等高层语义。
视频分析:通过时空特征建模,可捕捉视频中的动作序列、事件发展脉络,甚至预测后续可能发生的场景。
自由文本生成:针对混合模态输入,能够生成开放域回答、结构化报告、创意文案等多种形式的文本输出,且保持内容的连贯性与准确性。
3.泛化与适配能力
得益于多样化的训练数据与灵活的架构设计,Flamingo展现出强大的泛化能力:训练时每序列最多使用5张图像,评估时却能从多达32对图像/视频-文本序列中获益;不仅适配自然场景任务,在医疗影像解读、工业质检等专业领域也表现出巨大潜力。
四、技术演进与生态拓展
Flamingo的技术理念已从视觉-语言领域延伸至更广阔的多模态空间,形成了多元化的技术生态。NVIDIA推出的Audio Flamingo 3(AF3)便是这一理念在音频领域的典型实践,它构建了\"听觉-语言\"双引擎系统,支持10分钟长音频处理、语音-环境音-音乐整合理解等能力,在20项音频理解任务中刷新基准。
这种演进体现了Flamingo核心设计的普适性:通过冻结专业模态编码器、设计高效跨模态桥接模块、采用门控融合机制,可快速构建适配不同模态的多模态模型,为实现\"通用人工智能\"提供了可行路径。
五、局限与未来展望
尽管Flamingo取得了突破性进展,仍存在一些待解挑战:一是对长序列视觉输入的处理效率有待提升,尤其是高清视频分析场景;二是在细粒度视觉推理任务中,对微小差异的识别精度仍有优化空间;三是模型规模较大,部署成本较高,不利于边缘设备应用。
未来的发展方向清晰可见:其一,通过模型压缩与量化技术,降低部署门槛,推动在消费电子、工业设备等终端场景的应用;其二,融合更多模态信息(如触觉、嗅觉等),构建更全面的多模态理解能力;其三,强化可解释性,使跨模态推理过程更透明,满足医疗、司法等专业领域的合规需求。
从技术创新到生态拓展,Flamingo不仅为多模态学习提供了全新范式,更推动人工智能从\"单一能力\"向\"综合智能\"跨越。在少样本学习这一核心优势的支撑下,它正加速多模态技术在各行各业的落地应用,为智能交互、内容创作、行业诊断等场景带来革命性变革。