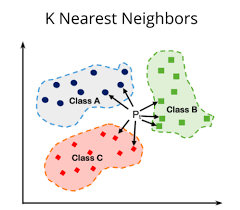
K-最近邻(K-Nearest Neighbors,KNN)算法是一种基于实例的学习方法,以其简洁明了的思路和广泛的适用性在机器学习领域占据重要地位。该算法的核心思想是:对于一个新的、未知类别的数据点,通过比较其与已知类别训练集中的数据点的距离,找出与其最近的K个邻居,并依据这K个邻居的多数类别来决定新数据点的类别归属。
一、KNN算法定义与工作流程
KNN算法是一种非参数、基于距离的分类方法,无需构建显式模型,而是直接依赖于训练数据进行预测。其主要工作流程如下:
1. 确定K值:K是一个预先设定的正整数,表示在训练集中选取与待分类点最近的邻居数量。K值的选择对最终预测结果有显著影响,需根据具体问题和数据特性进行合理选择。
2. 距离计算:计算待分类点与训练集中每一个点之间的距离。常用的距离度量包括欧氏距离、曼哈顿距离、切比雪夫距离、马氏距离等。这些距离函数旨在量化不同维度特征间差异的程度。
3. 寻找最近的K个邻居:根据计算得到的距离,按由近及远排序,选择与待分类点距离最近的K个训练数据点作为其邻居。
4. 类别决策:统计这K个邻居中各个类别的出现频率,将待分类点归为出现频率最高的类别。这种决策规则被称为“多数表决”或“硬投票”。此外,还可以采用加权投票的方式,赋予距离更近的邻居更大的权重。
二、KNN算法优缺点
优点:
● 简单易懂:KNN算法概念清晰,实现过程直观,便于理解与解释。
● 无需假设数据分布:KNN是非参数方法,不依赖于数据的具体分布形式,适用于各种类型的数据集。
● 适应性强:能够处理多种类型的数据(如数值型、名义型、序数型等),且对于缺失值和异常值有一定的鲁棒性。
缺点:
● 计算复杂度高:随着训练集规模增大,每次预测时都需要计算待分类点与所有训练点的距离,导致时间复杂度较高,尤其在高维空间中,所谓的“维度灾难”问题尤为突出。
● 存储需求大:KNN算法需要保存整个训练集,对于大规模数据集,存储成本可能过高。
● 对异常值敏感:异常值(离群点)可能对预测结果产生较大影响,因为它们可能成为某些待分类点的近邻。
● 对类别不平衡问题处理欠佳:当数据集中各类别样本数量严重不均衡时,KNN可能偏向于将新样本分类为样本数量较多的类别。
三、KNN算法的应用场景
KNN算法凭借其通用性和灵活性,在众多商业和科研领域有着广泛的应用:
1. 推荐系统:电商平台和流媒体服务利用用户的历史行为记录(如购买记录、观影历史等),通过KNN算法找到具有相似行为模式的用户群体,从而为其推荐可能感兴趣的商品或内容。
2. 金融市场分析:金融机构运用KNN算法预测个人或企业的信用评分,辅助信贷决策和风险评估;在股票市场中,可用于识别相似的投资组合,为投资者提供投资建议。
3. 市场细分与客户分类:企业通过KNN算法对客户进行聚类分析,识别具有相似特征和行为模式的客户群体,以实现精准营销和个性化服务。
4. 房地产估价:根据房屋的物理属性(如面积、房间数、地理位置等)以及附近类似房源的成交价格,利用KNN算法估算待售房屋的市场价值。
5. 客户服务:在客户支持系统中,KNN算法可协助将客户咨询自动分类,并将其转交给最擅长处理此类问题的客服人员。
6. 欺诈检测:通过分析交易模式和历史数据,KNN算法有助于识别信用卡交易、保险理赔等领域的异常行为,及时发现潜在的欺诈风险。
7. 手写识别:在手写识别系统中,KNN算法可根据笔画特征的相似性,将输入的手写字符与预存的模板库进行匹配,实现字符识别。
8. 图像识别:在计算机视觉任务中,KNN算法可用于图像内容分类,如识别图片中的物体或场景,或者在人脸识别中判断两张人脸是否属于同一人。
9. 生物信息学:在基因表达分析、疾病分类等领域,KNN算法可帮助科学家识别基因序列、蛋白质结构等生物数据中的模式和关联,支持疾病诊断与药物研发。
10. 智能个人助手:智能手机和平板电脑等智能设备中的语音助手,运用KNN算法理解用户的语音指令,并执行相应的操作(如打开应用、查询信息、设置提醒等)。
11. 交通规划:KNN算法可应用于交通流量数据分析,优化交通信号控制、预测交通拥堵、规划最优行驶路线等。
12. 医疗诊断:结合患者的临床特征、实验室检查结果等信息,KNN算法可用于辅助医生进行疾病诊断,特别是在罕见病或多因素疾病的诊断过程中。
尽管KNN算法在实际应用中表现出色,但应充分考虑其对异常值的敏感性、较高的计算复杂度以及对大规模数据存储的需求,适时结合数据预处理、降维技术、优化搜索策略等手段,以提高算法的效率和预测准确性。
四、Python环境下KNN算法的实现
在Python中,我们可以借助强大的机器学习库scikit-learn轻松实现KNN算法。以下是一个完整的示例,展示了如何使用scikit-learn对样本数据集进行分类:
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsClassifier
from sklearn.metrics import accuracy_score
# 加载数据集
iris = load_iris()
X, y = iris.data, iris.target
# 划分数据集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 创建KNN分类器实例
knn = KNeighborsClassifier(n_neighbors=3)
# 训练模型
knn.fit(X_train, y_train)
# 预测测试集
y_pred = knn.predict(X_test)
# 评估模型
accuracy = accuracy_score(y_test, y_pred)
print(f\"Model accuracy: {accuracy:.2f}\")
在这个例子中,我们首先导入所需的库和模块,然后加载鸢尾花数据集,将其划分为训练集和测试集。接着,创建一个KNN分类器实例,指定邻居数量(K值)为3,并用训练集对其进行训练。最后,利用训练好的模型对测试集进行预测,并计算预测准确率。
实际应用中,为了提升KNN算法的性能,可能还需要进行以下操作:
● 调整K值:通过交叉验证等方式,尝试不同K值,观察其对模型性能的影响,选择最佳K值。
● 特征缩放:由于KNN算法对特征尺度敏感,通常需要对数据进行标准化或归一化处理,确保各特征在相同尺度上进行距离计算。
● 距离度量选择:根据数据特性和问题背景,选用最适合的距离度量方法,如欧氏距离、曼哈顿距离、余弦相似度等。
● 模型调优:利用GridSearchCV或RandomizedSearchCV等工具进行参数网格搜索或随机搜索,找到最优的超参数组合。
综上所述,K-最近邻算法作为一种基础而实用的机器学习方法,在众多商业和科研领域中发挥着重要作用。尽管存在计算复杂度高、对异常值敏感等局限性,但通过合理的数据预处理、参数调整及优化策略,KNN仍能在许多实际问题中展现出良好的预测性能。在Python环境下,借助scikit-learn库,我们可以便捷地实现KNN算法,并进行模型训练、预测与评估。