支持向量机(Support Vector Machines, SVM)作为一种经典的机器学习方法,以其卓越的泛化能力和对非线性问题的有效处理,在模式识别、分类及回归分析等领域展现出强大的应用潜力。其核心理念在于构建一个最优的决策边界,该边界不仅能够清晰地划分不同类别样本,而且具有最大间隔,以期增强模型在未知数据上的预测性能。本文将深入剖析SVM的主要概念、工作原理、核函数种类、实际应用及优缺点。
一、SVM的主要概念
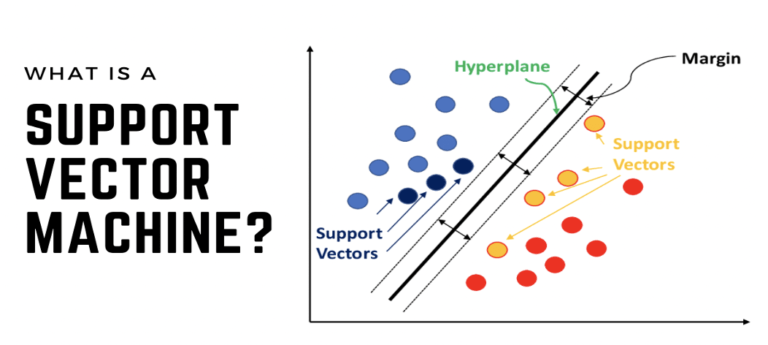
1. 决策边界(Decision Boundary):决策边界是将数据集中的不同类别样本严格区分的分割线或面。在二维空间中,决策边界表现为一条直线;在多维空间中,则表现为一个超平面。理想的决策边界应确保同类样本尽可能远离边界,异类样本则严格位于边界两侧。
2. 支持向量(Support Vectors):支持向量是距离决策边界最近的训练样本,它们对最终决策边界的确定起到决定性作用。即使数据集中存在大量冗余样本,SVM仅依赖于这些关键的支持向量来刻画分类边界,从而降低了过拟合的风险并提高了模型的稳健性。
3. 间隔(Margin):间隔是指决策边界与最近支持向量之间的距离,它反映了分类的“确信度”或“稳定性”。较大的间隔意味着分类结果更为可靠,模型的泛化能力更强。
4. 最优间隔(Maximal Margin):最优间隔是指在满足所有样本正确分类的前提下,决策边界与支持向量间能达到的最大间隔。SVM的目标就是通过数学优化手段找到这样的决策边界。
5. 核函数(Kernel Function):面对非线性可分数据,SVM巧妙地运用核函数将原始特征映射到高维特征空间,在新空间中寻找线性可分的决策边界。核函数的选择和设计对SVM的性能至关重要,它无需显式进行高维变换,极大地简化了计算过程。
二、SVM的工作原理
1. 线性可分问题:对于线性可分的数据集,SVM的任务是在众多可能的决策边界中找出一个能最大化间隔的超平面。这一过程可通过构造并求解相应的凸二次规划问题实现。
2. 非线性问题:当数据分布呈现复杂的非线性结构时,SVM利用核函数将低维的非线性问题转换为高维的线性问题。例如,通过RBF核函数,原本在原始空间中看似杂乱无章的数据在高维空间中可能会展现出清晰的线性分离趋势。
3. 优化问题:SVM的求解过程实质上是一个优化问题。目标函数通常包含两部分:一是最大化间隔(即最小化间隔的倒数),二是惩罚违反间隔约束的样本(即软间隔)。通过拉格朗日乘子法和KKT条件,可以将原问题转化为对偶问题,进而采用高效的优化算法如SMO(Sequential Minimal Optimization)求解。
4. 软间隔与正则化:现实世界的数据往往存在噪声和异常值,完全满足间隔约束可能过于苛刻。因此,SVM引入了软间隔概念,允许部分样本在一定范围内违反间隔约束,同时通过正则化参数C来权衡间隔最大化与误分类惩罚的程度。C值越大,对误分类的容忍度越低,模型倾向于寻求更严格的间隔;反之,C值越小,模型更侧重于保持大的间隔,可能会牺牲一定的分类精度。
三、SVM的核函数
1. 线性核:适用于线性可分或者近似线性可分的数据集,直接在原始特征空间中寻找线性决策边界。简单直观,计算效率高。
2. 多项式核:通过构建特征的高次组合,适用于存在较明显非线性但复杂度适中的数据。多项式阶数的选择直接影响模型的复杂度和拟合能力,过高可能导致过拟合,过低可能无法捕捉数据的非线性特性。
3. 径向基函数(RBF)核:RBF核是最常用的非线性核函数之一,尤其适用于高维、复杂非线性数据。其参数γ决定了核函数的宽度,对模型的复杂度和分类效果有显著影响。RBF核因其局部性、平滑性和无限维映射等特性,常能在保持较低模型复杂度的同时获得良好的分类性能。
4. sigmoid核:形似逻辑回归中的sigmoid函数,将特征映射至(-1,1)区间。尽管理论上适用于非线性分类,但由于其在实际应用中容易导致过拟合、难以选择合适的参数等问题,sigmoid核在SVM中的应用相对较少。
四、SVM的应用
SVM凭借其优秀的泛化能力和处理非线性问题的优势,在诸多领域得到广泛应用:
● 图像识别:在人脸识别、物体检测、医学影像分析等任务中,SVM能够有效处理图像像素间的非线性关系,实现精确分类。
● 语音识别:通过对语音信号的特征提取,SVM可用于区分不同的语音命令或说话人,提升语音交互系统的准确率。
● 基因表达分析:在生物信息学领域,SVM可用于肿瘤亚型分类、疾病诊断标志物筛选等任务,揭示基因表达数据背后的生物学意义。
● 文本分类:针对大规模文本数据,SVM结合词袋模型、TF-IDF等特征表示方法,可实现新闻分类、情感分析、主题识别等任务。
● 手写识别:在光学字符识别(OCR)系统中,SVM用于识别手写数字、字母甚至汉字,提升自动识别的准确度。
五、SVM的优缺点
优点:
● 强泛化能力:SVM通过最大化间隔,有效防止过拟合,特别适合小样本学习任务。
● 非线性处理能力:借助核函数,SVM能够在高维特征空间中处理复杂的非线性问题,无需显式进行维度提升。
● 核技巧:避免了直接在高维空间中的计算,降低了计算复杂度,提升了模型的可解释性和泛化能力。
缺点:
● 计算复杂度:当特征数量极其庞大时,SVM的训练时间可能会显著增加,特别是在使用复杂核函数(如高阶多项式核)或大规模数据集时。
● 核函数选择与参数调优:选择合适的核函数和调整相关参数(如C、γ等)对SVM的性能至关重要,但这通常需要丰富的经验或通过交叉验证等方法进行试错,增加了模型训练的复杂性。
六、Python使用
在Python中,支持向量机(SVM)可以通过多种机器学习库实现,其中最流行的是`scikit-learn`。以下是使用`scikit-learn`中的`SVC`(支持向量分类器)实现SVM的一个基本示例:
### 安装scikit-learn
如果你还没有安装`scikit-learn`,可以通过`pip`进行安装:
```bash
pip install scikit-learn
```
### 使用SVM进行分类的步骤
1. **导入必要的库**:
```python
from sklearn import svm
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.metrics import classification_report, accuracy_score
```
2. **加载数据集**:
这里以鸢尾花(Iris)数据集为例,`scikit-learn`自带了这个数据集。
```python
iris = load_iris()
X = iris.data
y = iris.target
```
3. **划分训练集和测试集**:
```python
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
```
4. **创建SVM模型**:
```python
# 使用支持向量分类器(SVC)
model = svm.SVC(kernel='linear') # 这里选择线性核函数
```
5. **训练模型**:
```python
model.fit(X_train, y_train)
```
6. **进行预测**:
```python
y_pred = model.predict(X_test)
```
7. **评估模型**:
```python
print(classification_report(y_test, y_pred))
print(\"Accuracy:\", accuracy_score(y_test, y_pred))
```
### SVM的核函数选择
在创建SVM模型时,可以通过`kernel`参数选择不同的核函数:
- `'linear'`:线性核
- `'poly'`:多项式核
- `'rbf'`:径向基函数核
- `'sigmoid'`:sigmoid核
### 参数调优
SVM模型还有一些其他参数可以调整,以提高模型的性能:
- `C`:正则化参数,控制间隔的宽度。较大的C值会增加间隔宽度,较小的C值会允许更多的样本点违反间隔约束。
- `gamma`:在使用RBF核时,这个参数控制了影响的尺度。
例如,使用RBF核并调整参数:
```python
model = svm.SVC(kernel='rbf', C=1.0, gamma='auto')
```
在这里,`gamma='auto'`意味着`gamma`将由`1 / n_features`决定。
### 使用GridSearchCV进行参数调优
`scikit-learn`还提供了`GridSearchCV`工具,可以用于自动化地搜索超参数的最优组合:
```python
from sklearn.model_selection import GridSearchCV
param_grid = {
'C': [0.1, 1, 10, 100],
'gamma': ['scale', 'auto'],
'kernel': ['rbf']
}
grid_search = GridSearchCV(svm.SVC(), param_grid, cv=5)
grid_search.fit(X_train, y_train)
print(\"Best parameters:\", grid_search.best_params_)
print(\"Best score:\", grid_search.best_score_)
```
使用SVM进行机器学习任务时,理解算法的工作原理、选择合适的核函数以及进行参数调优都是至关重要的。通过`scikit-learn`,这些步骤都变得相对容易实现。
综上所述,支持向量机作为一类强大的监督学习算法,凭借其独特的最优间隔最大化思想、核函数技巧以及对非线性问题的良好处理能力,在众多实际应用中展现出卓越的性能。尽管面临计算复杂度、核函数选择与参数调优等方面的挑战,但随着计算资源的不断丰富和技术的持续进步,SVM仍然是机器学习工具箱中不可或缺的一员,为各类模式识别与分类任务提供有力支持。