Deep & Cross Network(DCN)是谷歌和斯坦福大学在2017年提出的,用于广告点击预测(Ad Click Prediction)的模型,主要解决CTR(点击率)预估问题。它是对Wide&Deep模型的进一步改进,能够自动学习特征交叉,有效捕获有限阶上的有效特征交叉,无需人工特征工程或暴力搜索,且计算代价较低。
一、结构
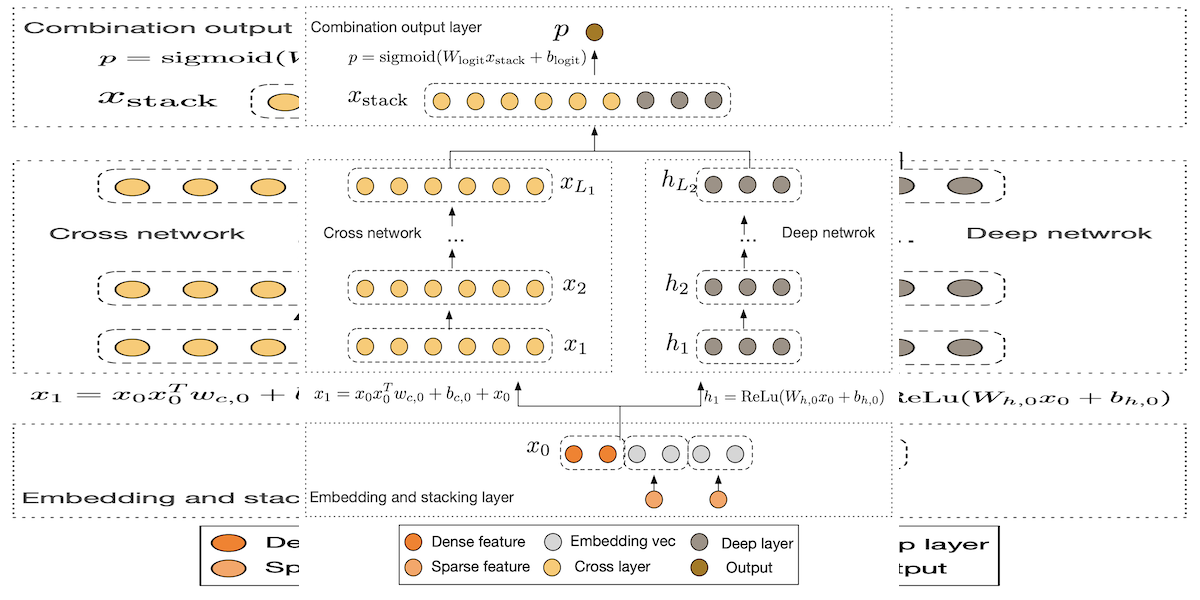
1.Embedding层:对于CTR问题输入的离散特征,通常先进行one-hot编码,但编码后特征稀疏且维度高。Embedding层可将其转换为低维实值密集向量(即Embedding向量),该矩阵参数会随网络训练一起学习。
2.Stacking层:用于组合Embedding层的输出,将离散特征的Embedding结果与原始连续特征组合在一起,形成后续网络的输入。
3.Cross Network:是DCN的核心部分,由多层组成。通过特殊结构,交叉特征的阶数会随层深度增加而增加,能高效学习组合特征。其每一层的计算是前一层输出和初始输入特征做交叉,以残差网络形式表达,可减少过拟合、防止梯度弥散,便于学习特征交叉属性。
4.Deep Network:是典型的全连接前馈神经网络,与Cross Network并行,用于捕捉高度非线性的特征交互。由于Cross Network参数较少、表达能力受限,引入Deep Network可弥补这一不足。
5.Output层:Combination Layer将Cross Network和Deep Network的结果组合,经过一层全连接层和sigmoid函数得到CTR预估结果。
二、算法原理
1.Embedding和Stacking:将输入的稀疏类别特征通过Embedding映射为低维向量,与连续特征堆叠后,得到模型的输入向量。
2.Cross Network计算:每一层的输出由前一层输出、初始输入特征的交叉运算,结合权重、偏置以及前一层输出本身共同得到,通过这种方式逐步提升特征交叉的复杂度。
3.Deep Network计算:通过多层全连接层,利用激活函数(如relu)处理前一层输出,逐步捕捉复杂的非线性特征交互。
4.组合输出:将Cross Network和Deep Network的输出结果拼接后,通过全连接层和sigmoid激活函数,最终输出点击率的预估概率。
三、模型优点
1. 自动高效学习特征交叉,减少人工成本
在传统机器学习或早期深度学习模型中,特征交叉(如“用户年龄×商品类别”“地区×消费习惯”等组合特征)依赖人工设计,需要领域专家通过经验筛选有效交叉特征,不仅耗时耗力,还可能遗漏潜在重要交叉模式。
DCN的Cross Network通过特殊的层叠结构,能自动学习不同阶数的特征交叉(交叉阶数随网络深度增加),无需人工干预即可捕获低阶到高阶的有效特征交互。例如,在广告点击预测中,可自动挖掘“用户性别×广告类型×时间段”等复杂交叉特征,大幅降低特征工程的人力成本和经验依赖。
2. 计算效率高,适合大规模数据场景
工业级任务(如电商推荐、信息流广告)通常面临海量样本和高维特征,模型的计算效率直接影响落地可行性。
DCN的Cross Network采用轻量化设计:每层计算仅通过前一层输出与初始输入的交叉运算实现,参数规模随输入维度线性增长(而非指数级),内存占用低,训练和推理速度快。相比需要暴力枚举交叉特征的模型(如FM的高阶扩展)或参数庞大的纯深度网络,DCN在处理千万级甚至亿级样本时,仍能保持高效的训练和实时推理能力,满足工业界高吞吐需求。
3. 兼顾记忆性与泛化性,提升预测精度
记忆性:Cross Network通过显式的特征交叉,能精准捕捉训练数据中频繁出现的“共现模式”(如特定用户群体对某类商品的偏好),类似传统模型的“记忆”能力。
泛化性:并行的Deep Network(全连接神经网络)通过非线性变换,可学习未在训练数据中直接出现的潜在特征关系(如跨类别商品的隐性关联),具备强泛化能力。
两者结合使DCN既能拟合已知的高频特征交互,又能泛化到新的特征组合,在稀疏数据或冷启动场景中(如新品推荐)表现更优,最终提升点击率、转化率等核心指标的预测精度。
4. 结构灵活,易于扩展和调优
DCN的模块化设计使其具备良好的可扩展性:
可根据任务需求调整Cross Network的深度(控制交叉阶数)和Deep Network的层数/神经元数,平衡模型复杂度与性能;
支持与其他技术结合,例如在Embedding层引入预训练向量提升特征表示,或在输出层加入注意力机制突出重要特征交叉;
后续改进版本(如DCN V2)通过低秩分解、专家混合(MoE)等优化,进一步提升了特征交互的表达能力和训练效率,可适配更复杂的业务场景。
5. 抗过拟合能力强,训练稳定性高
Cross Network采用残差连接结构(每层输出包含前一层的原始信息),能有效缓解深层网络的梯度弥散问题,使模型更容易训练收敛。同时,其参数规模远小于纯深度网络,减少了过拟合风险。在数据噪声较多或样本分布波动大的场景(如金融风控中的欺诈检测),DCN的稳定性更突出,模型鲁棒性更强。
四、应用场景
1. 与Wide&Deep的区别
Wide&Deep是DCN的前身,两者均采用“并行双路径”结构,但核心设计目标和能力不同:
特征交叉方式:
Wide&Deep的“Wide路径”依赖人工设计的特征交叉(如“用户年龄×商品类别”等预定义组合),无法自动学习交叉模式;而DCN的“Cross Network”通过特殊层叠结构自动学习有限高阶特征交叉,无需人工干预。
表达能力:
Wide&Deep的Wide路径仅能捕捉预设的低阶交叉,Deep路径捕捉非线性但缺乏显式交叉机制;DCN的Cross Network可随深度增加自动提升交叉阶数(如3层Cross可捕捉3阶交叉),同时Deep Network补充非线性,整体表达能力更全面。
参数效率:
Wide&Deep的Wide路径若人工交叉特征过多,会导致参数爆炸;DCN的Cross Network参数随输入维度线性增长,更高效。
2. 与Factorization Machine(FM)及高阶扩展模型的区别
FM及其高阶扩展(如FFM、HOFM)是早期特征交叉模型,核心区别在于交叉的“显式性”和“效率”:
特征交叉的阶数与效率:
FM仅能显式捕捉二阶特征交叉,高阶交叉需通过暴力扩展(如HOFM)实现,但参数规模随阶数呈指数增长,计算成本极高;DCN的Cross Network通过层叠结构,可显式捕捉有限高阶交叉(阶数=Cross层数),且参数随输入维度线性增长,计算效率远高于高阶FM扩展。
非线性能力:
FM是线性模型,仅能学习线性特征交叉,无法捕捉非线性关系;DCN通过并行的Deep Network补充强非线性特征交互,兼顾线性交叉与非线性泛化。
3. 与DeepFM的区别
DeepFM是FM与Deep Network的结合,核心区别在于“交叉路径的设计目标”:
交叉路径的机制:
DeepFM的“FM路径”仅负责二阶特征交叉,且交叉方式是隐式的(通过因子向量内积实现);DCN的“Cross Network”通过显式的交叉运算(前层输出与初始输入的交叉),可学习高阶显式交叉,且交叉阶数可控(通过调整层数)。
对稀疏特征的处理:
两者均通过Embedding层处理稀疏特征,但DeepFM的FM路径依赖Embedding向量的内积交叉,而DCN的Cross Network直接基于Embedding后的向量进行显式交叉,对高阶交叉的表达更直接。
4. 与纯Deep Network(如MLP)的区别
纯Deep Network(多层全连接神经网络)依赖非线性激活函数隐式学习特征交互,与DCN的核心区别在于“特征交叉的显式性”:
特征交叉的可解释性与效率:
纯Deep Network的特征交叉是隐式且无序的(通过多层非线性变换间接实现),无法明确控制交叉阶数,且高阶交叉需通过极深网络才能捕捉,易导致参数冗余和过拟合;DCN的Cross Network通过显式结构定向学习有限高阶交叉,阶数随层数透明增长,参数更少、效率更高。
对低频特征交叉的捕捉:
纯Deep Network在稀疏数据中,低频特征交叉难以被非线性变换捕捉;DCN的Cross Network通过“初始输入与前层输出的交叉”,可更高效地传递低频特征信息,提升对长尾交叉的学习能力。
5. 与xDeepFM的区别
xDeepFM是另一种改进的特征交叉模型,核心区别在于交叉网络的结构设计:
交叉单元的粒度:
xDeepFM的CIN(Compressed Interaction Network)基于“向量级交叉”(按特征域粒度交互),交叉过程依赖特征域划分;DCN的Cross Network基于“向量整体交叉”(输入向量与前层输出直接交叉),不依赖特征域,更灵活。
计算复杂度:
CIN的参数规模随特征域数量和层数增长,复杂度高于DCN的Cross Network(线性增长);因此DCN在特征域极多的场景(如千万级商品ID)中,训练和推理效率更高。
五、模型改进
DCN后续发展出了DCN V2版本,其重构了交叉网络组件,提出使用权重矩阵和残差连接对特征交互进行建模的新方法。同时引入低秩版本的交叉网络,将权重矩阵分解为两个较小矩阵的乘积,可在更高训练速度下达到可比性能。此外,受专家混合(Mixture-of-Experts,MoE)思想启发,利用多个专家在不同子空间中学习特征交互,并通过门控机制组合学习到的交叉特征,能更有效地捕获特征级和比特级的特征交互。