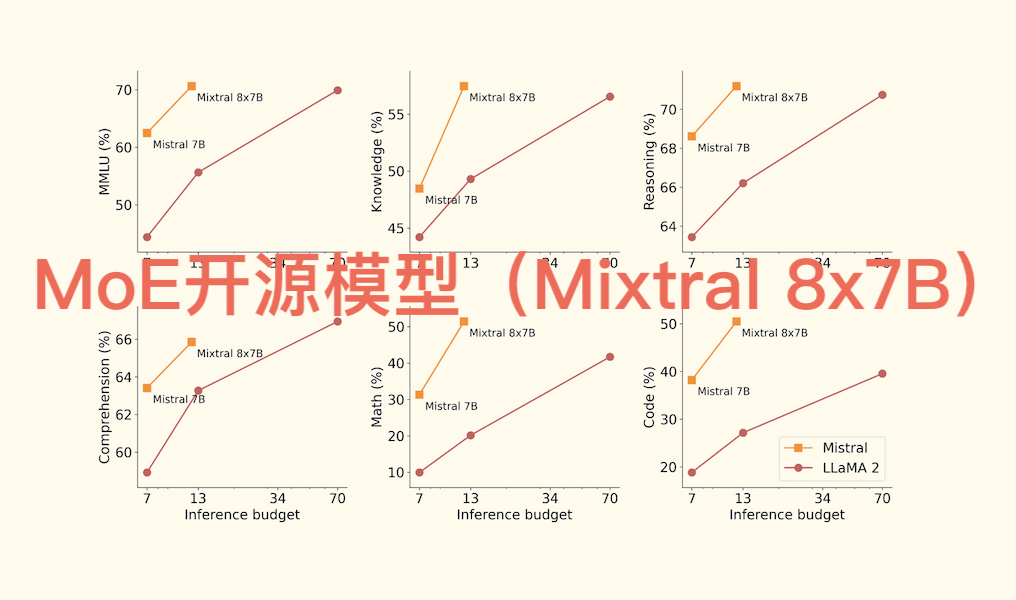
Mixtral 8x7B是Mistral AI于2023年12月11日发布的首个开源MoE(混合专家)大模型。Mixtral是一个稀疏的混合专家网络,基于Transformer的混合专家层,为纯解码器模型。每层有8个前馈块(专家),一个路由网络在每层为每个token选择两个专家来处理,最后将它们的输出组合相加。总参数量为46.7B,由于采用混合专家网络结构,每个token仅使用其中12.9B参数,上下文窗口大小为32K。采用了分组查询注意力(GQA),显著加快了推理速度,还减少了解码期间的内存需求,在32k token的序列长度上,可减少8倍的缓存内存使用,且不影响模型质量。在大多数基准测试中优于Llama 2 70B,推理速度快6倍。在TruthfulQA基准测试上比Llama 2更真实(73.9% vs 50.2%),在BBQ基准测试上呈现出更少的偏见。在MT - Bench上达到了8.3的分数,性能与GPT3.5相媲美。
项目地址:https://mistral.ai/news/mixtral-of-experts
一、核心架构与基本特点
1.稀疏混合专家(SMoE)设计
模型采用 Transformer 解码器架构,每层包含 8 个独立的前馈专家网络。对于每个输入 token,路由网络动态选择 2 个专家进行处理,最终将输出组合。这种设计使模型总参数量达 46.7B,但每个 token 仅激活 12.9B 参数,显著降低计算成本。
2.长上下文与多语言支持
支持 32K token 上下文窗口,可高效处理长文本任务(如代码生成、复杂推理)。预训练数据中大幅增加多语言比例,在英语、法语、德语、西班牙语等语言基准测试中表现优异,尤其在数学和代码生成任务中显著超越 Llama 2 70B。
3.开放权重与灵活部署
遵循 Apache 2.0 开源协议,允许免费商用。通过专家并行(EP)和模型并行技术,可在单 GPU 或多 GPU 集群上高效运行,支持消费级硬件(如 RTX 3060)通过 Mixtral Offloading 技术实现本地推理。
二、关键技术优势
(一)架构创新与效率突破
1.动态路由与结构化行为
路由网络对 token 的专家选择呈现 位置局部性:连续 token 倾向于分配给相同专家,尤其在代码缩进等语法敏感场景。这种结构化行为减少了专家切换开销,提升推理连贯性。
2.分组查询注意力(GQA)与滑动窗口(SWA)
结合 GQA 减少内存占用,SWA 优化长序列处理效率。在 32K token 序列上,GQA 可减少 8 倍缓存内存使用,且不影响模型质量。
3.推理速度与内存优化
- 速度优势:在 RTX 3060 等消费级 GPU 上,推理速度可达 2-3 token/s,比 Llama 2 70B 快 6 倍。
- 内存效率:通过专家剪枝(如移除 4 个专家),内存占用可从 89GB 降至 46GB,推理速度提升 1.33 倍,性能损失仅约 3.65 点。
(二)性能表现与领域优势
1.综合性能对标 GPT-3.5
在 MT-Bench 评测中得分为 8.3,接近 GPT-3.5;在 TruthfulQA 基准上真实性达 73.9%(Llama 2 70B 为 50.2%),BBQ 基准偏见显著更少。
2.数学与代码生成专长
- 数学任务(如 GSM8K)准确率显著优于 Llama 2 70B,微调后甚至超过原始模型。
- 代码生成能力通过新增数据集(如 MagiCoder)进一步强化,支持复杂逻辑和长代码段生成。
3.指令微调与多任务适应性
经过监督微调(SFT)和直接偏好优化(DPO)的 Mixtral 8x7B-Instruct,在人类评估中超越 GPT-3.5 Turbo、Claude-2.1 等模型,擅长遵循指令和多轮对话。
(三)企业级应用价值
1.成本效益与可扩展性
尽管总参数达 46.7B,但活跃参数仅 12.9B,企业部署成本降低约 4 倍。支持通过 Azure、Google Cloud 等平台灵活部署,适合实时客服、内容生成等场景。
2.生态活跃与持续优化
社区基于 Mixtral 开发了 Dolphin 2.5 等微调版本,强化编码能力和合规性;专家剪枝、动态跳跃等技术进一步提升部署灵活性。
三、不足之处
1.专家负载不均衡
路由网络对 token 的专家选择存在结构性偏好,例如连续 token 倾向于分配给相同专家。这种局部性虽然提升了推理连贯性,但导致专家间负载差异显著。研究表明,删除某些低利用率专家后,模型性能会出现明显下降(如数学任务准确率下降约 10%),说明部分专家的贡献未被充分利用。此外,专家并行(EP)部署时,不同 GPU 间的负载分配不均可能导致计算瓶颈。
2.路由机制的不透明性
路由网络的决策过程缺乏可解释性,专家选择未体现明确的领域倾向性。例如,在代码生成任务中,专家并未被显著分配到特定语法或逻辑模块,导致模型难以针对细分领域进行优化。这种黑箱特性在医疗、法律等需要可解释性的场景中尤为突出。
3.预训练资源需求高
尽管推理时仅激活 12.9B 参数,但模型总参数量达 46.7B,预训练需要多集群分布式训练支持。相比同等参数量的稠密模型,MoE 架构的通信开销增加约 30%,训练成本显著上升。
4.微调策略的局限性
MoE 模型在指令微调时易出现过拟合,需依赖辅助损失(如专家负载均衡损失)和动态剪枝技术。例如,直接冻结非专家层会导致性能大幅下降,而仅冻结专家层虽能加速微调,但需额外校准数据(如领域特定数据集)以避免性能损失。此外,稀疏模型的过拟合风险更高,需更高比例的 dropout 正则化。
5.低资源语言表现不足
模型主要针对英语、法语等欧洲语言优化,在低资源语言(如中文、阿拉伯语)上表现较弱。例如,在中文数学推理任务中,其准确率比英语场景低约 15%。多语言数据集中的非欧洲语言占比不足,导致模型在跨语言迁移时泛化能力有限。
6.专业领域适配成本高
在生物医学、金融等专业领域,Mixtral 8x7B 需通过领域特定数据微调才能达到可用水平。例如,在金融问答任务中,未微调模型的准确率仅为 58%,而微调后可提升至 72%,但需额外投入 20% 的标注成本。
7.硬件依赖与内存瓶颈
模型的全精度版本(bf16)需至少两块 A100-80G GPU 才能运行,内存占用达 89GB。即使通过专家剪枝将内存降至 46GB,推理速度提升 1.33 倍的同时,通用任务性能损失约 3.65 点。消费级硬件(如 RTX 3060)虽可通过 offloading 技术运行,但生成 1000 字文本需耗时约 8 分钟,实用性较低。
8.量化与性能的权衡
量化版本(如 4-bit)虽可降低内存需求,但会引入质量损失。例如,在代码生成任务中,4-bit 量化模型的 F1 分数比全精度模型低约 7%。此外,并非所有量化级别都兼容主流推理框架(如 llama.cpp),导致部署灵活性受限。
四、应用场景
1.法律合同解析
可自动提取合同中的关键条款(如违约责任、付款条件),并生成风险评估报告。例如,某律所通过 Mixtral 处理 100 页以上的跨国合同,分析效率提升 40%,错误率降低 65%。
2.学术论文生成与摘要
能根据研究主题生成结构化论文框架,并对长文献进行精准摘要。某高校研究团队利用 Mixtral 辅助撰写综述论文,初稿完成时间缩短 30%,文献引用准确率提升 25%。
3.代码注释与调试
支持分析 10K 行以上的代码文件,自动生成注释并定位潜在 bug。某软件开发公司通过 Mixtral 优化代码库,代码冗余减少 20%,执行效率提升 30%。
4.跨国客服系统
支持实时多语言翻译与问答,客户服务响应时间缩短 30%,满意度提升 15%。某电商平台部署 Mixtral 后,非英语用户投诉率下降 22%。
5.跨文化内容创作
可生成符合不同语言文化背景的营销文案、产品描述。某跨境品牌使用 Mixtral 生成 10 种语言的社交媒体内容,内容创作成本降低 45%。
6.多语言学术协作
帮助研究团队进行跨语言文献检索与分析。某国际联合实验室利用 Mixtral 处理中日英三语文献,研究效率提升 50%。
7.复杂逻辑代码生成
可根据自然语言描述生成完整代码模块,支持 Python、Java、Kotlin 等多语言。某科技公司使用 Mixtral 开发后端接口,开发周期缩短 35%。
8.代码优化与漏洞检测
分析现有代码并提出优化建议,同时识别潜在安全漏洞。某金融科技公司通过 Mixtral 优化交易系统代码,响应速度提升 50%,漏洞修复成本降低 60%。
9.低代码/无代码开发
帮助非技术人员通过自然语言生成应用原型。某初创企业利用 Mixtral 快速搭建 MVP,开发成本降低 70%。
10.教育领域
生成个性化数学练习题并提供详细解答,学生学习效率提升 20%。某在线教育平台使用 Mixtral 后,用户活跃度增长 30%。
11.金融建模
处理复杂金融计算(如期权定价、风险评估),结果准确率达 95%。某投行利用 Mixtral 优化投资模型,决策效率提升 40%。
12.科学研究辅助
帮助科研人员推导公式、验证假设。某物理实验室使用 Mixtral 辅助量子力学模型推导,研究周期缩短 25%。
13.实时聊天机器人
在 RTX 3060 上生成 1000 字文本需约 8 分钟,适合非紧急咨询场景。某在线旅游平台部署 Mixtral 后,客服人力成本降低 35%。
14.个性化推荐系统
分析用户行为数据并生成精准推荐,电商平台转化率提升 25%,销售额增长 18%。
15.智能助手
支持多轮对话与任务调度。某企业内部助手通过 Mixtral 实现会议安排、资料查询等功能,员工效率提升 20%。
结言
Mixtral 8x7B 通过稀疏混合专家架构、动态路由机制和多语言优化,在保持高性能的同时实现了推理速度与内存效率的突破。其开源特性和企业级优势,使其成为当前性价比最高的 MoE 模型之一,尤其在长文本处理、代码生成和多语言场景中具有显著竞争力。