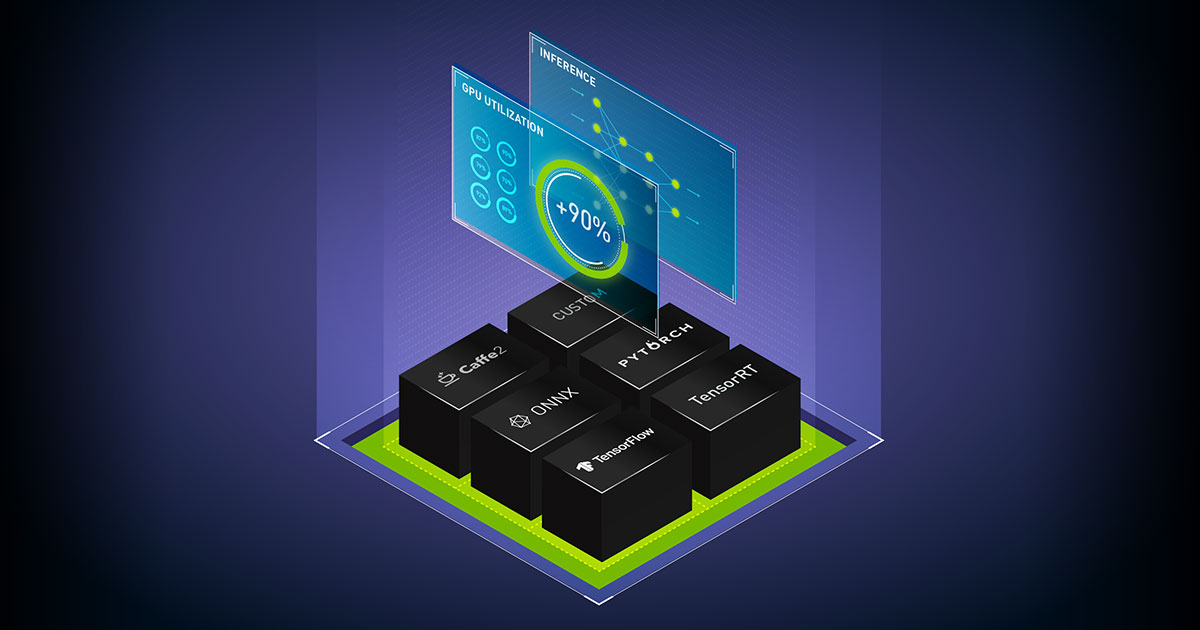
Triton框架(全称NVIDIA Triton Inference Server)是一款由NVIDIA开发的开源模型推理部署工具,旨在简化机器学习模型从训练到生产环境部署的流程,同时优化推理性能(如吞吐量、延迟)。它支持多框架、多模型、多硬件部署,广泛应用于云服务、边缘计算、嵌入式设备等场景。
项目地址:https://github.com/triton-inference-server/server
一、定位与价值
Triton的核心目标是解决模型部署中的碎片化问题:实际生产中,团队可能使用PyTorch、TensorFlow、ONNX等多种框架训练模型,且需要在GPU、CPU、边缘设备等不同硬件上运行。Triton通过统一的接口兼容这些场景,降低部署复杂度,同时通过动态批处理、模型并行等技术提升推理效率。
二、核心功能
Triton的功能围绕“高效部署”和“性能优化”展开,主要包括:
1.多框架支持
兼容主流深度学习框架及模型格式,无需修改模型即可部署:
框架:PyTorch、TensorFlow、ONNX Runtime、TensorRT、XGBoost、LightGBM等;
格式:ONNX、TorchScript、TensorFlow SavedModel、TensorRT Plan等;
扩展:支持自定义后端(如Python、C++),可集成自研模型或框架。
2.灵活的模型管理
版本控制:同时部署同一模型的多个版本(如A/B测试),通过请求参数指定调用版本;
热加载:更新模型时无需重启服务,动态加载新模型,减少 downtime;
并发部署:单服务实例可同时部署多个模型(如目标检测+分类模型的流水线)。
3.性能优化工具
动态批处理:自动将多个小请求合并为批次推理(减少GPU调用开销),支持按延迟或吞吐量自适应调整;
模型并行与张量并行:支持大模型拆分到多GPU(如Transformer模型);
推理优化:集成TensorRT自动优化(量化、层融合),提升GPU利用率。
4.多协议与多场景适配
接口:支持HTTP/REST、gRPC、C API,方便不同客户端调用;
硬件:兼容GPU(NVIDIA)、CPU(x86/ARM)、边缘设备(Jetson);
场景:支持实时推理(低延迟)、批量推理(高吞吐量)、流式推理(如音频/视频实时处理)。
5.监控与可观测性
内置 metrics 接口(兼容Prometheus),可监控吞吐量、延迟、GPU利用率等指标;
支持推理轨迹追踪(与OpenTelemetry集成),方便排查性能瓶颈。
三、架构组成
Triton的架构设计模块化,核心组件包括:
| 组件 | 功能 |
|-------------------|----------------------------------------------------------------------|
| 前端(Frontend) | 处理客户端请求,支持HTTP/REST、gRPC、C API协议,解析请求参数(如模型名、版本)。 |
| 模型管理器(Model Manager) | 加载/卸载模型、管理版本、检查模型兼容性,支持从本地文件或云存储(S3/GCS)加载模型。 |
| 推理引擎(Inference Engines) | 调用对应框架的 runtime(如PyTorch Runtime、TensorRT Engine)执行推理计算。 |
| 调度器(Scheduler) | 协调请求队列,实现动态批处理、优先级调度,优化GPU资源利用。 |
| 后端适配器(Backend Adapters) | 适配不同框架的接口,屏蔽底层差异,统一输出格式。 |
四、典型使用场景
Triton适用于需要高效部署模型的各类场景,例如:
1.云服务推理:在AWS、GCP等云平台部署多框架模型,通过Kubernetes容器化管理,支持弹性扩缩容;
2.边缘计算:在Jetson边缘设备(如自动驾驶传感器、工业摄像头)部署轻量化模型,低延迟处理实时数据;
3.多模型流水线:串联多个模型完成复杂任务(如“图像预处理→目标检测→属性分类”),Triton可按顺序调度模型;
4.高并发场景:如电商推荐系统、实时语音识别,通过动态批处理提升GPU吞吐量,降低单请求成本。
五、优势与生态
兼容性:摆脱框架绑定,同一服务可部署PyTorch、TensorFlow等模型,简化异构环境管理;
性能:集成TensorRT优化、动态批处理等技术,相比原生框架部署,吞吐量可提升数倍;
生态集成:
容器化:支持Docker、Kubernetes,方便在集群中部署;
监控:与Prometheus、Grafana集成,可视化推理指标;
开发工具:提供Python SDK(`tritonclient`),方便客户端调用和测试。
六、与同类工具的对比
| 工具 | 特点 | 适用场景 |
|--------------------|---------------------------------------|------------------------------|
| Triton Inference Server | 多框架支持、性能优化强、场景灵活 | 异构框架、高并发、边缘/云部署 |
| TensorFlow Serving | 仅支持TensorFlow,集成TF生态 | 纯TensorFlow环境 |
| TorchServe | 仅支持PyTorch,轻量简洁 | 纯PyTorch环境 |
| ONNX Runtime Server | 基于ONNX,跨平台但功能较简单 | 以ONNX格式为主的部署 |
结言
Triton Inference Server是一款“一站式”模型推理部署工具,通过多框架兼容、性能优化和灵活的场景适配,成为生产环境中模型部署的主流选择,尤其适合需要处理异构模型、高并发推理的团队。其开源特性和NVIDIA的持续维护,也保证了生态的活跃度和功能的迭代。