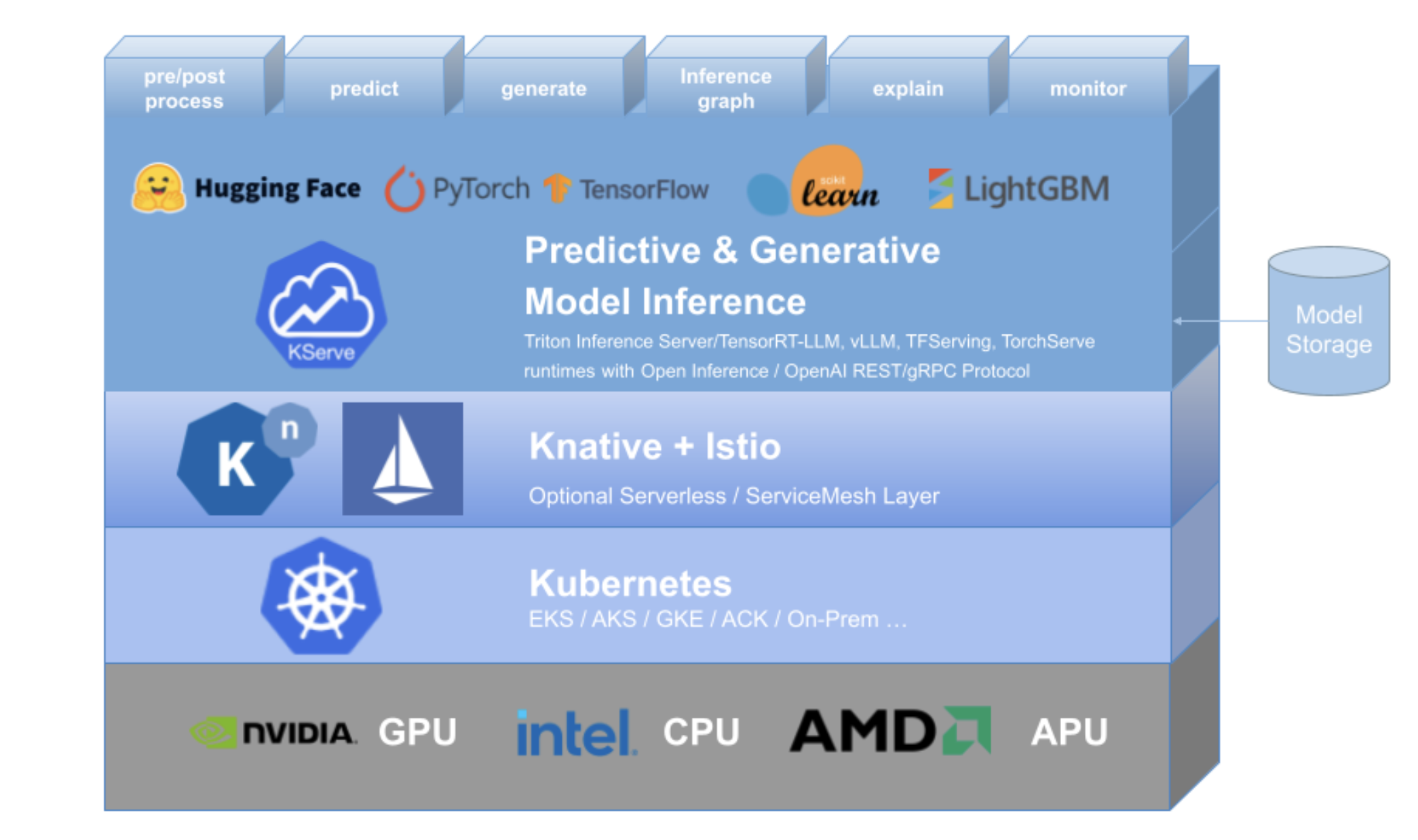
KServe是一个开源的云原生机器学习模型服务框架,专注于简化机器学习(ML)模型的部署、管理和扩展,尤其适用于大规模、分布式的生产环境。它基于Kubernetes(K8s)构建,遵循云原生理念,旨在为不同类型的模型提供标准化、高性能的推理服务。
https://github.com/kserve/kserve
一、定义与背景
KServe的前身是KFServing(Kubernetes-based Feature Store Serving),2021年由Linux基金会AI&Data(LF AI & Data)接管后更名为KServe,成为云原生机器学习部署的核心项目之一。其设计目标是:
1.提供标准化的模型服务接口,屏蔽不同框架的差异;
2.支持云原生环境(基于K8s),实现模型的弹性伸缩、高可用和自动化管理;
3.集成推理优化技术,提升模型服务的性能和效率。
二、核心功能
KServe的核心功能围绕“模型服务全生命周期管理”展开,主要包括:
1.多框架模型支持
兼容主流机器学习/深度学习框架及模型格式,无需修改模型即可部署:
经典ML:Scikit-learn、XGBoost、LightGBM;
深度学习:TensorFlow、PyTorch、MXNet;
优化格式:ONNX、TensorRT、TorchScript;
自定义模型:支持通过Python/Go等语言封装的自定义逻辑。
2.自动化模型部署与管理
声明式配置:通过Kubernetes自定义资源(CRD)`InferenceService`定义模型服务,无需编写复杂部署脚本;
版本管理:支持多模型版本并行部署,方便灰度发布和A/B测试;
自动扩缩容:基于CPU/内存使用率、请求量等指标自动调整副本数,甚至支持“零扩缩容”(无请求时缩容至0,节省资源)。
3.高性能推理优化
动态批处理:自动合并多个请求为批次推理,提升GPU/CPU利用率;
模型缓存:缓存高频请求的推理结果,减少重复计算;
集成专业推理引擎:内置或集成Triton Inference Server、TorchServe等高性能引擎,支持低延迟、高吞吐量场景。
4.模型服务增强能力
数据转换(Transformer):支持请求数据的预处理(如归一化、特征提取)和响应数据的后处理;
模型解释(Explainer):集成模型解释工具(如Alibi、SHAP),提供推理结果的可解释性;
流量管理:结合Istio等服务网格,实现流量路由、负载均衡和熔断降级。
5.可观测性集成
内置监控指标(如推理延迟、吞吐量、错误率),支持对接Prometheus+Grafana;
日志与追踪:集成ELK Stack(日志)、Jaeger(分布式追踪),方便问题排查。
三、架构组成
KServe的架构基于Kubernetes,分为控制平面和数据平面两部分:
| 平面 | 核心组件 | 功能描述 |
|------------|-----------------------------------|--------------------------------------------------------------------------|
| 控制平面 | KServe Controller | 监听`InferenceService`等CRD,自动创建/更新模型服务所需的K8s资源(Deployment、Service等);管理模型版本和扩缩容逻辑。 |
| | CRD(自定义资源) | 包括`InferenceService`(定义模型服务)、`TrainedModel`(关联训练好的模型)等,是用户配置模型服务的入口。 |
| 数据平面 | Inference Service Proxy | 处理客户端请求路由,协调Transformer、Predictor、Explainer的调用流程。 |
| | Predictor | 核心推理组件,集成Triton、TorchServe等推理引擎,加载模型并执行推理。 |
| | Transformer | 负责请求数据预处理(如格式转换、特征工程)和响应数据后处理。 |
| | Explainer | 生成模型推理的解释(如特征重要性),支持Alibi、SHAP等解释工具。 |
| | Ingress Gateway(如Istio) | 接收外部请求,转发至对应的Inference Service,支持流量控制和负载均衡。 |
四、典型使用场景
KServe适用于需要大规模、标准化、高可用模型服务的场景,例如:
1.企业级ML平台:统一管理多个团队的模型部署,避免重复开发;
2.实时推理服务:如推荐系统、欺诈检测、图像识别等低延迟需求场景;
3.多模型协同服务:需要同时部署多个模型(如上游特征模型+下游预测模型)并串联调用的场景;
4.云原生环境迁移:将现有模型从传统服务器迁移到K8s集群,利用云原生的弹性和可扩展性。
五、优势与不足
优势
1.云原生原生兼容:基于K8s,天然支持容器化、集群管理和自动运维,适合混合云/多云环境;
2.标准化与灵活性平衡:提供统一的模型服务接口,同时支持自定义逻辑(如Transformer);
3.高性能与可扩展性:通过推理引擎优化和动态批处理提升性能,支持横向扩展以应对高并发;
4.生态集成丰富:可与MLflow(模型生命周期)、Feast(特征存储)、Argo(工作流)等工具无缝集成。
不足
1.学习曲线陡峭:需掌握Kubernetes基础知识,对中小团队不够友好;
2.部署成本高:依赖K8s集群,部署和维护成本高于轻量级工具(如BentoML);
3.轻量场景冗余:对于小规模、单模型部署,KServe的复杂功能可能显得冗余。
六、与同类工具对比
| 工具 | 定位差异 | 适合场景 |
|--------------------|--------------------------------------------------------------------------|----------------------------------------------|
| KServe | 云原生、标准化模型服务框架,支持多引擎和复杂服务流程 | 大规模、企业级、K8s环境下的多模型管理 |
| Triton Inference Server | 专注于推理性能优化的引擎,支持多框架和批处理 | 对推理延迟/吞吐量要求高的场景(可被KServe集成) |
| BentoML | 轻量级模型打包与部署工具,支持本地/云/K8s部署 | 中小规模、快速部署,无需深入K8s知识 |
| Seldon Core | 基于K8s的模型服务框架,更侧重自定义推理流程和MLOps集成 | 需要高度定制推理逻辑的企业场景 |
| MLflow | 全生命周期管理工具(训练、部署、追踪),部署功能相对简单 | 需统一管理训练和部署的端到端场景 |
结言
KServe是云原生机器学习模型服务的标准化解决方案,尤其适合需要在Kubernetes环境下大规模部署、管理多框架模型的场景。它通过标准化接口、自动化运维和高性能推理优化,降低了生产级模型服务的复杂度,但也要求使用者具备一定的K8s知识。如果你的团队已采用云原生架构,且需要支持多样化模型和高可用服务,KServe是理想选择。