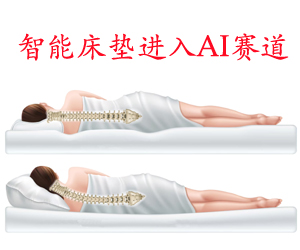
一、研究背景康复评估作为康复医学的核心环节,是制定个性化康复方案、监测康复进程及评估治疗效果的重要依据。当前传统康复评估模式面临诸多瓶颈:过度依赖治疗师主观经验,不同评估者间评分差异可达22%,标准化程度不足;评估周期长且数据采集频率低,每日仅1-2次,无法实现动态监测导致治疗调整滞后,使康复效率下降35%;多源评估数据格式不统一,整合分析能力薄弱,难以支撑精准康复决策。随着人工智能与医疗技术的深度融合,深度学习在多模态数据处理、智能分析等方面的优势日益凸显,为构建高效、客观、智能的康复评估报告自动生成系统提供了技术支撑。